若有收获,请记得分享和转发哦
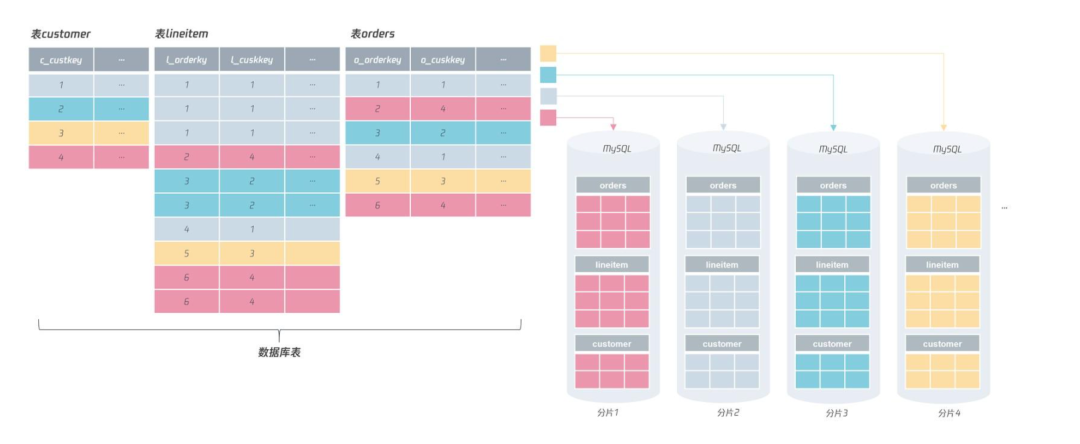
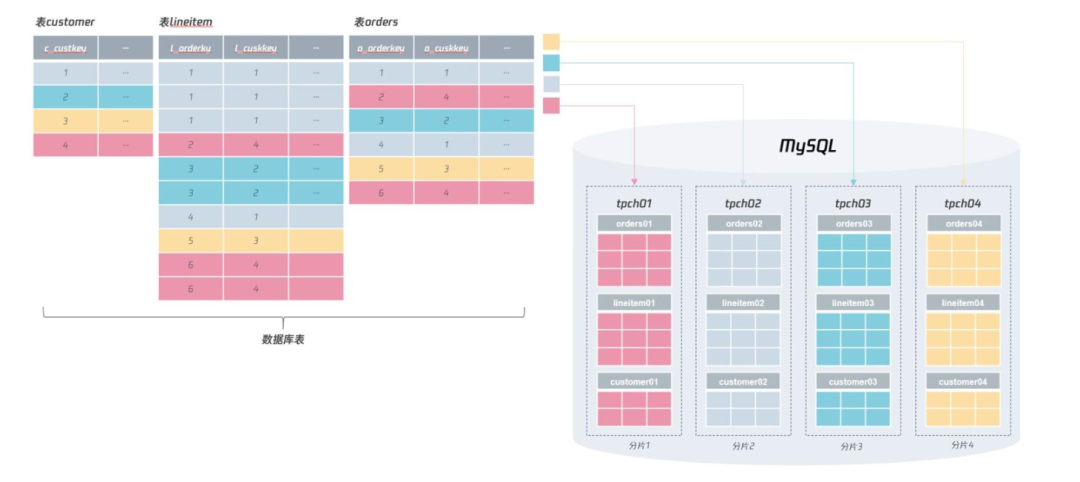
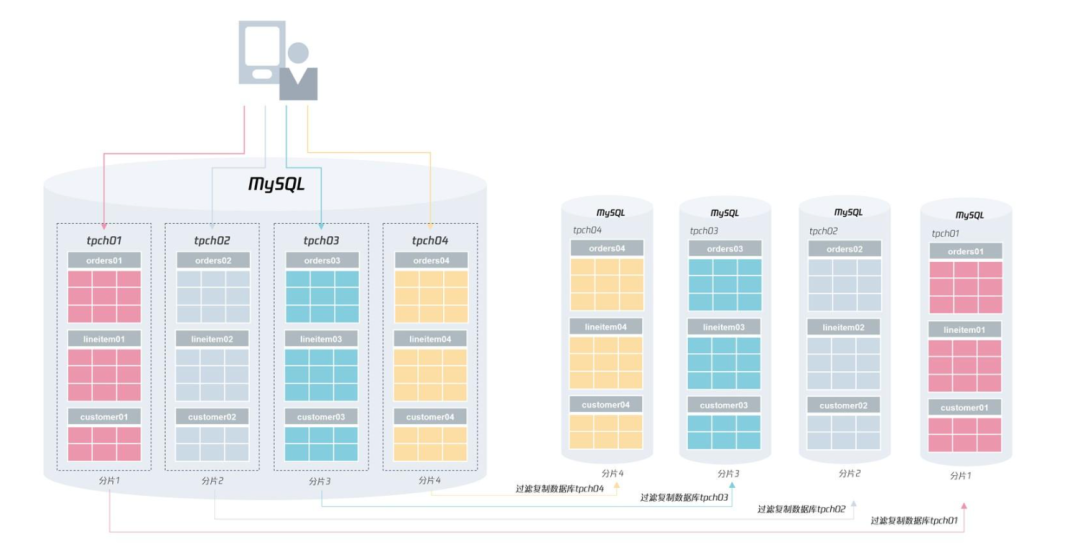
我们知道分布式数据库是将数据打散到不同节点上存储,从而提升性能与可靠性。那么今天我们来看看在分布式数据库中,一个非常重要的设计:正确地把数据分片,充分发挥分布式数据库架构的优势。
选出分片键
在对表中的数据进行分片时,首先要选出一个分片键(Shard Key),即用户可以通过这个字段进行数据的水平拆分。
对于我们之前使用的电商业务的订单表orders,其表结构如下所示:
CREATE TABLE `orders` (
`O_ORDERKEY` int NOT NULL,
`O_CUSTKEY` int NOT NULL,
`O_ORDERSTATUS` char(1) NOT NULL,
`O_TOTALPRICE` decimal(15,2) NOT NULL,
`O_ORDERDATE` date NOT NULL,
`O_ORDERPRIORITY` char(15) NOT NULL,
`O_CLERK` char(15) NOT NULL,
`O_SHIPPRIORITY` int NOT NULL,
`O_COMMENT` varchar(79) NOT NULL,
PRIMARY KEY (`O_ORDERKEY`),
KEY `idx_custkey_orderdate` (`O_CUSTKEY`,`O_ORDERDATE`),
KEY `ORDERS_FK1` (`O_CUSTKEY`),
KEY `idx_custkey_orderdate_totalprice` (`O_CUSTKEY`,`O_ORDERDATE`,`O_TOTALPRICE`),
KEY `idx_orderdate` (`O_ORDERDATE`),
KEY `idx_orderstatus` (`O_ORDERSTATUS`),
CONSTRAINT `orders_ibfk_1` FOREIGN KEY (`O_CUSTKEY`) REFERENCES `customer` (`C_CUSTKEY`)
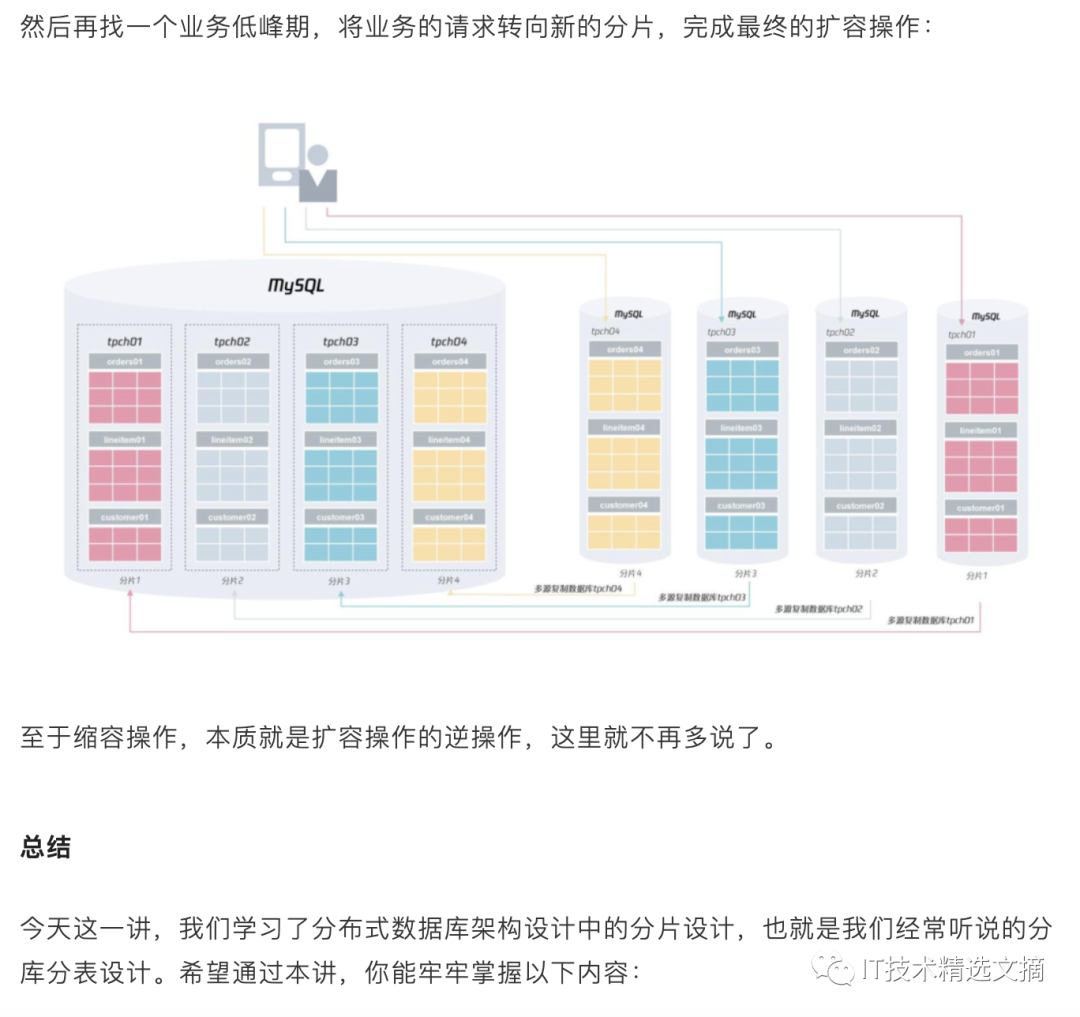
) ENGINE=InnoDB对于类似淘宝、京东、拼多多这样业务体量的应用来说,单实例 MySQL 数据库在性能和存储容量上肯定无法满足“双 11、618 ”大促的要求,所以要改造成分布式数据库架构。
而第一步就是要对表选出一个分片键,然后进行分布式架构的设计。
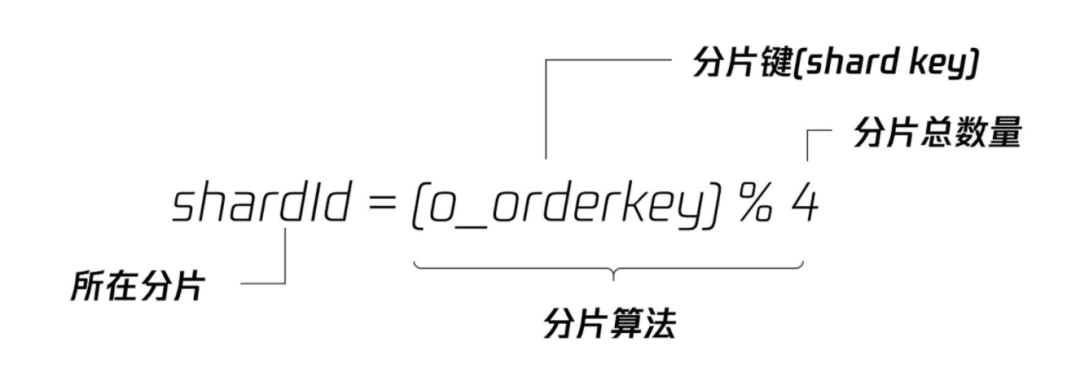
对于上面的表orders,可以选择的分片键有:o_orderkey、o_orderdate、也可以是o_custkey。在选出分片键后,就要选择分片的算法,比较常见的有 RANGE 和 HASH 算法。