Unicode
我们知道unicode编码解决了ASCII码只支持英文数字等字符的单一问题;
unicode编码目前普遍采用USC-2格式,该格式采用两个字节来编码一个字符,所以两个字节最多可以表示2^16=65536个字符(一个字节为8位)
但是两个字节的容量要表示的是各国语言,而汉字字符----简体加繁体字就共有约7w个!,显然2个字节根本无法囊括所有汉字。因此也有采用USC-4格式,即4个字节来编码字符的情况,但目前为止普遍仍采用USC-2格式,毕竟常用几千个汉字足以满足所需!
同时字符编码一般用十六进制来表示,比如汉字"经"的编码是0x7ECF,其中0x表示十六进制,7ECF若转换为十进制就是32463,二进制为1111110 11001111,两个字节足以表示这个字符
当然,unicode编码表也继承了ASCII码表中的字符,只是以十六进制的形式来表示而已。例如,字符”a“在ASCII码表中对应的十进制序号为97,在unicode编码表中对应的十六进制序号为0x61,换算到十进制仍然为序号97!
UTF-8
如前所述,unicode编码有诸多问题。首先,它始终采用两个字节来表示字符,这就会对只需要一个字节来表示的字符来说,产生浪费空间的情况;其次,两个字节能表示的字符太有限!
这个时候,UTF-8编码规则发挥作用的时候到了,它是一种可变长度的编码规则,根据不同情况可以占用1~4个字节不等。
那么就会有一个问题,既然字符所占有的字节数不尽相同,程序在读一段连续的字节的时候是如何分辨哪些是字节连在一起表示某一字符,而哪些字节又是以单个形式来表示某一字符的呢?
当字符编码只占一个字节时,第一个二进制都是0,0xxx xxxx,表示这个字符占一个字节,考虑一下,余下7位(2^7=128)恰好能表示ASCII码中的128个字符的序号,因此编码方式等同于标准ASCII码。
当字符编码占两个字节时,第一个字节的前两位是11,第三位是0,第二个字节的前两位是10,110x xxxx 10xx xxxx,表示这个字符总共需要占两个字节。
具体规则如下表所述:
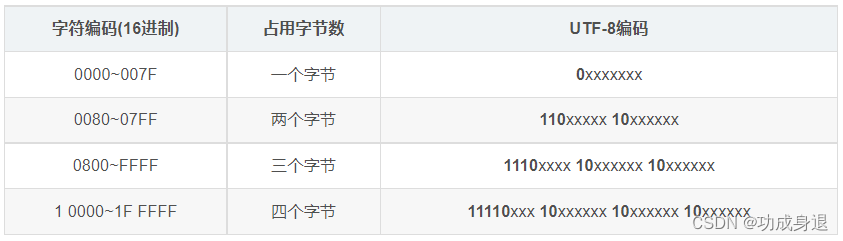
现在明白了吧,原来UTF-8字符编码方式的巧妙之处在于,每一个字符对应编码的首字节的开头一位或者几位二进制携带了这样一个信息,该字符需要用几个字节来表示!
例如,我们知道在UTF-8中汉字一般由三个字节来表示(其他不常用汉字用4个字节来表示),当程序在一连串字节码中读取到一个字节的开头几位是1110(3个1),这就代表着程序还需要连续读取接下来的2个字节;同时,剩下两个字节的开头两位10也同样表示,这俩字节是该汉字的成员字节。读取完毕后,程序将这三个字节与UTF-8编码表比对,从而得到对应的汉字!
那么具体是怎么实现的呢,来看下面的例子:
汉字【知】在unicode编码中表示为U+77E5,77E5转换到二进制为111 0111 1110 0101;再看UTF-8编码规则中,占用三个字节的字符对应的编码中 1110(第1个字节前三位) 10(第2个字节前两位) 10(第3个字节前两位)是固定位占有的,那么三个字节剩下的位总共还有16个,16个位刚好等价于两个字节,能够表示大部分常用汉字了!我们只要把111 0111 1110 0101 这16位按顺序依次填入剩余待定位,最终得到的三个字节 【111001111001111110100101】 就是汉字【知】在UTF-8格式中的编码!
