目录
1、回忆v1,v2
V1:引入了深度可分离网络(DW+PW)
V2:引入了倒残差结构(bottleneck)
2、V3的网络特点
1、更新了block(beck),在V2基础上进行了简单改动:
引入了SE模块(Squeeze-and-excitation),对于SE模块,不再使用sigmoid,而是采用ReLU6(x + 3) / 6作为近似(h-sigmoid)
使用hard-swish激活函数代替ReLU6
2、使用了NAS(神经架构搜索)搜索参数
3、重新设计了耗时层结构
4、扩展层使用的滤波器数量不同(使用NetAdapt算法获得最佳数量)
5、瓶颈层输出的通道数量不同(使用NetAdapt算法获得最佳数量)
6、修改了MobileNetV2后端输出head
3、详细解释
网络的整体结构:

对于第一点:引入SE模块:

pool:这里是平均池化1*1,FC1这里将通道数减小为1/4,后接一个ReLU函数,FC2将通道数变为原来一样,后接h-sigmoid函数,得到的权重与原来的特征矩阵相乘得到新的特征矩阵。
h-sigmoid函数:
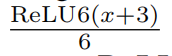

h-swish函数:


对于第三点、重新设计耗时层结构:减少第一个卷积层的卷积核个数(32->16)
MobileNet v1和v2都从具有32个滤波器的常规3×3卷积层开始,修改头部卷积核channel数量,mobilenet v2中使用的是32 x 3 x 3,作者发现,其实32可以再降低一点,所以这里作者改成了16,在保证了精度的前提下,降低了3ms的速度。然而实验表明,这是一个相对耗时的层,只要16个滤波器就足够完成对224 x 224特征图的滤波。虽然这样并没有节省很多参数,但确实可以提高速度。
精简Last stage:准确率没有发生变化,节省了7ms(11%)

版权声明:本文为qq_53029963原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。