学完了numpy,相信大家感受到了它的强大之处,今天我们来学习新的python库之pandas,它和numpy密切相关,我们不管是工作还是学习,数据分析的时候都会用到,pandas主要用于表格式数据,方便我们在视觉上观察。接下来跟我一起来学习吧!相信我,你会爱上pandas的!

一、创建数据及查看数据属性
1.1、Series
1.1.1、通过列表创建数据
import pandas as pd
import numpy as np
data = [1,2,3,4]
s = pd.Series(data=data)
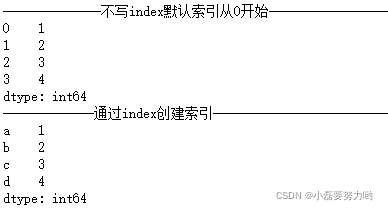
print('--------------不写index默认索引从0开始------------------------------')
print(s)
s = pd.Series(data=data,index=['a','b','c','d'])
print('-------------通过index创建索引----------------------------')
print(s)
1.1.2、通过字典创建数据
import pandas as pd
dic = {
'语文':100,
'数学':99,
'理综':250
}
s = pd.Series(data=dic) # 键为索引,值为值
print(s)

1.1.3、查看属性
print(f'shape返回维度元组:{s.shape}')
print(f'size返回行数数字:{s.size}')
print(f'index返回索引:{s.index}')
print(f'values返回值:{s.values}')
print(f'dytpe返回数据类型:{s.dtype}')

1.1.4、Series常见方法
s = pd.Series(data=[1,2,3,4,5,4,2])
# 为了方便看结果,将Series结果转为了列表
list(s.head(3)) #显示前n个数据 [1, 2, 3]
list(s.tail(3)) #显示后n个元素 [5, 4, 2]
s.unique() #去重 array([1, 2, 3, 4, 5], dtype=int64)
list(s.isnull()) #用于判断每一个元素是否为空,为空返回True,否则返回False [False, False, False, False, False, False, False]
list(s.notnull())#用于判断每一个元素是否为空,不为空返回Frue,否则返回False [True, True, True, True, True, True, True]
1.1.5、Series运算
- 法则:索引一致的元素进行算数运算否则结果为NaN
s1 = Series(data=[1,2,3],index=['a','b','c'])
s2 = Series(data=[1,2,3],index=['a','d','c'])
s = s1 + s2
s
# s1和s2索引中都有a和c,所以索引a对应的值为1+1=2,c类似;b和d只存在于一个Series中,因此无法计算,结果为NaN

1.2、DataFrame
- DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
1.2.1、通过ndarray创建DataFrame
df = pd.DataFrame(data=[[1,2,3],[4,5,6]])
df
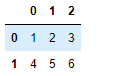
- 指定列索引和行索引
df = pd.DataFrame(data=[[1,2,3],[4,5,6]],index=['a','b'],columns=['e','f','g'])
df

1.2.2、通过字典创建DataFrame
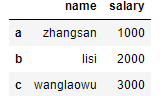
dic = {
'name':['zhangsan','lisi','wanglaowu'],
'salary':[1000,2000,3000]
} # 键为列索引, 字典中的列表式值为DataFrame中一列一列的值
df = pd.DataFrame(data=dic,index=['a','b','c'])
df
1.2.3、查看DataFrame的属性及总体描述
print(df.values) # 输出格式为数组, 一行作为一个数组中的一个列表元素
print(df.columns) # 输出列索引
print(df.index) # 输出行索引
print(df.shape) # 输出维度(行数,列数)

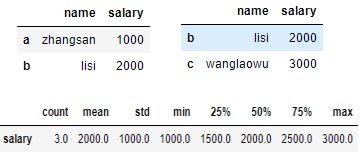
df.head(2) # 显示前两行
df.tail(2) # 显示最后两行
df.describe().T # 对DataFrame的数值型列进行统计性描述 包括:计数、均值、标准差、最小值、1/4位数、中位数、3/4位数、最大值
1.2.4、常用方法总结
| 方法 | 说明 |
|---|---|
| head(n) | 查看前n行 |
| tail(n) | 查看最后n行 |
| values | 查看值 |
| shape | 查看维度 |
| fillna(0) | 填充空值为0 |
| replace(m,n) | 将m替换为n |
| isnull()、notnull() | 判断值是否为空 |
| dropna(axis,how) | 删除空值 axis=0删除行,axis=1删除列;how=any只要有空值就删除,how=all某行或某列全是空值才删除改行或该列 |
| drop(列名) | 删除某一列 |
| unique() | 查看唯一值,将所有值去重后显示 |
| nunique() | 查看唯一值的数量 |
| reset_index() | 重置索引 |
| set_index(‘列名’) | 修改索引,将某列设为索引 |
| columns | 查看列索引 |
| index | 索引 |
| sort_index(ascending,inplace) | 根据索引排序,默认True升序,False降序;inplace默认False不修改原数据,True修改原数据 |
| sort_values(by,ascending,inplace) | 根据某列的值排序,参数by根据哪一列排序 |
| info() | 输出表数据的行列索引,数据类型,数量大小 |
| describe | 对DataFrame的数值型列进行统计性描述 包括:计数、均值、标准差、最小值、1/4位数、中位数、3/4位数、最大值 |
二、读取外部数据
| 数据类型 | 说明 | 读取方法 |
|---|---|---|
| csv\tsv\txt | 默认逗号分割 | pd.read_csv() |
| csv\tsv\txt | 默认\t 制表符分割 | pd.read_table() |
| excel | xls或xlsx | pd.read_excel() |
| mysql | 关系型数据库表 | pd.read_sql() |
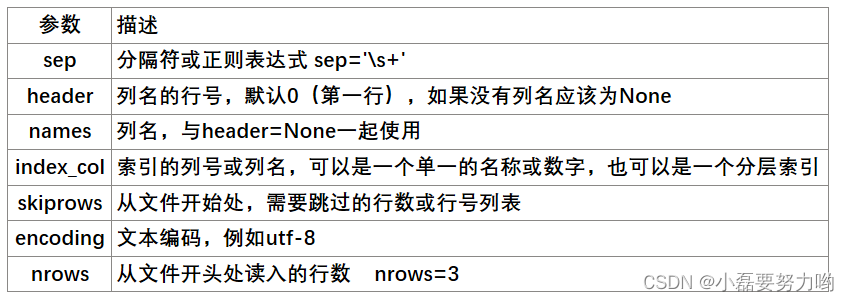
pd.read_csv()、pd.read_table()与pd.read_excel()类似
pd.read_sql(SQL查询语句,con=connect) 与其不同,
connect = pymysql.connect(host = 'localhost',user = '数据库用户名',password = '数据库密码',database = '数据库名称',charset = '字符编码类型')
pymysql 是python的库,用来连接数据库服务器,以便用python直接操作数据库
具体怎么用,以后会详细介绍的;涉及到了数据库知识。这里不详细的讲解了
df1 = pd.read_excel('C:/Users/dell/Desktop/测试2.xls')
df2 = pd.read_excel('C:/Users/dell/Desktop/测试2.xls',index_col='号码') # 将号码列作为行索引
df3 = pd.read_excel('C:/Users/dell/Desktop/测试2.xls',header=1) # 将第二行作为表头列索引
df4 = pd.read_excel('C:/Users/dell/Desktop/测试2.xls',index_col=0,header=None,names=['name','score']) # 将号码列作为行索引 不把第一行作为列索引 列索引名为name和score
df5 = pd.read_excel('C:/Users/dell/Desktop/测试2.xls',index_col=0,skiprows=1,header=None,names=['name','score']) # 将号码列作为行索引 跳过一行
df6 = pd.read_excel('C:/Users/dell/Desktop/测试2.xls',index_col=0,skiprows=1,header=None,names=['name','score'],nrows=3) # nrows读取前三行
三、数据提取与条件查询
3.1、数据提取iloc和loc
| 方法 | 解释 | 说明 |
|---|---|---|
| df[col] | 取一列 | col只能为列名 不能为数字 |
| df[[col1,col2]] | 取多列 | col只能为列名 |
| df[i:j] | 取多行 | i和j为数字 |
| df[i:i+1] | 取第i+1行 | 索引为i |
| df.iloc[index,col] | 取具体某个位置的元素 | index和col只能是数字 |
| df.iloc[:,col1:col3] | 切片,取某几列连续的列 | |
| df.iloc[:,[col1,col2]] | 切片,取某指定的某几列 | |
| df.loc[index,col] | 切片 | index可以是数字或文字,col必须是列名称,不能是列索引数 |
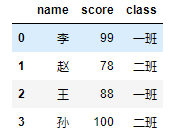
3.1.1 普通提取
dic = {
'name':['李','赵','王','孙'],
'score':[99,78,88,100],
'class':['一班','二班','一班','二班']
}
df = pd.DataFrame(dic)
df
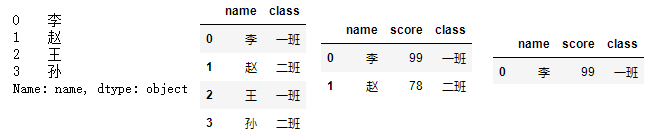
# 取姓名列
df['name'] # 输出的是Series类型
#取 姓名列和班级列
df[['name','class']]
# 取前两行
df[0:2]
# 取第一行
df[0:1]
3.1.2 iloc[] 隐式索引
只能输入索引数字
# 取第一行数据
df.iloc[1]
# 取前三行数据
df.iloc[0:3]
# 取前2列数据
df.iloc[:,0:2]
# 取第一列数据
df.iloc[:,0]
# 取第2和3行且是第2和3列的数据
df.iloc[1:3,1:3]
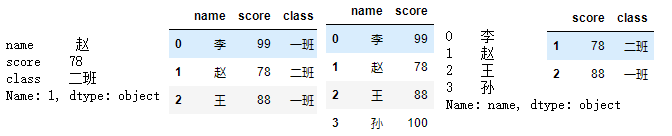
3.1.3 loc[] 显式索引
可以输入数字或文字
df2 = df.set_index('name') # 将name列设为索引
df2
df2.loc[['李','赵'],['score','class']]

3.2、条件查询
单条件查询df[条件] 多条件查询df[(条件1) & (条件2)] 多条件查询时将各个条件用括号括起来 否则出错
# ==有着判断的意思, 例如print(1==2) 结果是False
# 筛选出一班的学生信息
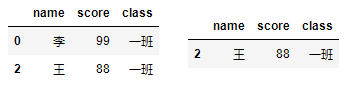
df[df['class']=='一班']
# 筛选出一班姓王的学生信息
df[df['class']=='一班' & df['name'] == '王']
四、常用类型数据及转换
4.1、数据类型
| 说明 | 类型 |
|---|---|
| 字符串类型 | object |
| 整数类型 | Int64,Int32,Int16, Int8 |
| 无符号整数 | UInt64,UInt32,UInt16, UInt8 |
| 浮点数类型 | float64,float32 |
| 日期和时间类型 | datetime64[ns]、datetime64[ns, tz]、timedelta[ns] |
| 布尔类型 | bool |
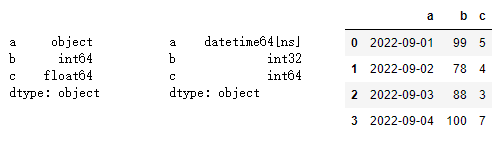
dic = {
'a':['2022-09-01','2022-09-02','2022-09-03','2022-09-04'], # 默认字符串类型 object
'b':[99,78,88,100], # 默认整数类型 int64
'c':[5.4,4.5,3.2,7.8] # 默认浮点型 float64
}
df = pd.DataFrame(dic)
print(df.dtypes)
# astype()强制转换数据类型
df['a'] = df['a'].astype('datetime64') # 将a列转换为日期类型
df['b'] = df['b'].astype('int32') # 将b列转化为int32类型
df['c'] = df['c'].astype('int64') # 将c列转化为int64类型,浮点数的小数点后的位数直接舍掉
print(df.dtypes)
df
4.2、日期类型函数
| 方法 | 说明 |
|---|---|
| to_numeric() | 转为数字型 |
| to_datetime() | 转为日期型 |
| to_timedelta() | 转为日期差类型 n days xx:xx:xx 利用dt.days提取天数 |
| dt.year | 年 |
| dt.month | 月 |
| dt.day | 日 |
| dt.hour | 时 |
| dt.minute | 分 |
| dt.second | 秒 |
| strtime(format,datetime) | 将日期时间按指定格式转化 但输出的类型是object |
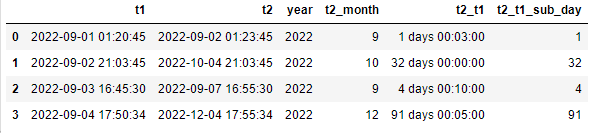
dic = {
't1':['2022-09-01 01:20:45','2022-09-02 21:03:45','2022-09-03 16:45:30','2022-09-04 17:50:34'], # 默认字符串类型 object
't2':['2022-09-02 01:23:45','2022-10-04 21:03:45','2022-09-07 16:55:30','2022-12-04 17:55:34'], # 默认字符串类型 object
}
df = pd.DataFrame(dic)
# 将t1和t2列转为日期类型
df['t1'] = pd.to_datetime(df['t1'])
df['t2'] = pd.to_datetime(df['t2'])
# 提取t1的年份和t2的月份
df['year'] = df['t1'].dt.year
df['t2_month'] = df['t2'].dt.month
# 计算t2与t1的日期差 (具体到秒)
df['t2_t1'] = df['t2']-df['t1'] # 日期差类型为timedelta64[ns]
# 只提取日期天数差 针对timedelta64[ns]类型的提取天数用dt.days
df['t2_t1_sub_day'] = df['t2_t1'].dt.days
df
print(df.dtypes)
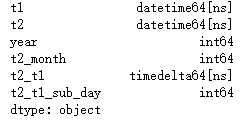
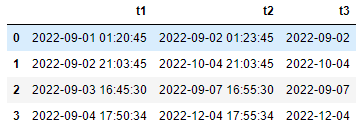
df['t3'] = pd.to_datetime(df['t2'].dt.strftime('%Y-%m-%d'))
df
五、处理缺失值与重复值
5.1、处理缺失值
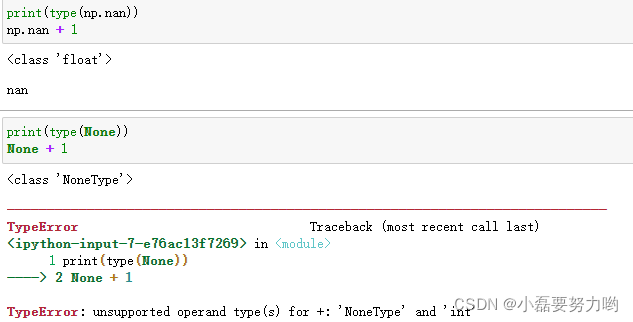
在python中含有两种空值:None 和 NaN 区别如图:
- NAN可以参与运算的 NAN的数据类型是float 因此我们处理数据时遇到的多数是NAN型缺失值
- None是不可以参与运算 None的数据类型是NoneType ;在pandas中如果遇到了None形式的空值则pandas会将其强转成NAN的形式。
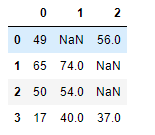
df = pd.DataFrame(data=np.random.randint(0,100,size=(4,3))) #随机生成一些数据
# 将其中三个数分别改为None和Nan型空值
df.iloc[2,2] = None
df.iloc[1,2] = np.nan
df.iloc[0,1] = None
df
# 从以下结果可以看出, 显示的均是Nan
遇到空值是一般的想法就是:删除空值或填充空值
- 首先判断是否有空值(一般情况下每行每行的看是否有空值)
#哪些行中有空值
#any(axis=1)检测哪些行中存有空值
df.isnull().any(axis=1) # 将每行作为一个单位,any只要行有空值,那么该行输出True
#true对应的行就是存有缺失数据的行
df.isnull().sum(axis=0) # 0代表行轴, 对每一列空值计数
df.isnull().sum(axis=1) # 1代表列轴, 对每一行空值计数
# 行列轴这块优点绕, 现实与axis设置相反

- 删除空值:dropna(axis,how,subset,inplace)
|参数|说明|
|–|–|
axis=0/1 | 行(0)还是列(1)有空值删除
how=any/all|是否全部是空值才删除
subset=[col1,col2,col3]|看哪几列
inplace=True/False|是否在原数据上改动
df.dropna(axis=0,how='any',subset=['a','b']) # 行轴,a列和b列中只要有Nan就删除,
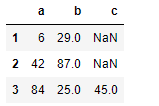
- 填充空值 fillna(axis,value,method)
|参数|说明|
|–|–|
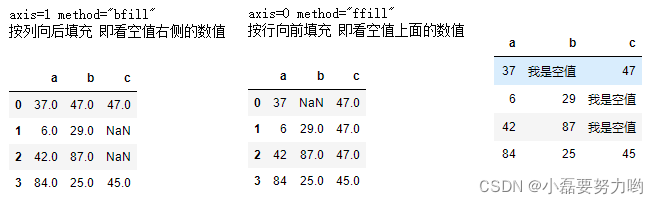
axis=0/1 | 行轴(0)是method的时候看上下值,列轴(1)看左右值,利用最近值填充
value|填充值
method=bfill/ffill/|向后填充/向前填充
inplace=True/False|是否在原数据上改动
df.fillna(axis=1,method='bfill')
df.fillna(axis=0,method='ffill')
df.fillna('我是空值')
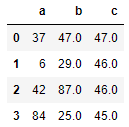
# 利用均值填充
df.fillna(df.mean) # 按每列的均值填充
5.2、处理重复值
| 方法 | 说明 |
|---|---|
| duplicated() | 检测哪些行存有重复的数据,返回布尔类型 |
| drop_duplicates() | 直接删除重复值,返回的数据没有重复值 |
| 参数 | 说明 |
|---|---|
| suset | 子集 只要在某几列中,查看是否存在重复行。多列时输入列表 |
| keep | first保留第一个/last保留最后一个/False全部删除 |
| inplcae | True替换原数据/False不替换原数据 |
df = pd.DataFrame(data=np.random.randint(0,100,size=(4,6)))
df.iloc[1] = [1,1,1,1,1,1]
df.iloc[2] = [1,1,1,1,1,1]
df.duplicated(keep='first') # 重复值中的第一个返回False
df.loc[~df.duplicated(keep='last')] # 筛选非重复值,保留最后一个
df.drop_duplicates(keep='last') # 删除重复值,保留最后一个
df.drop_duplicates(keep=False) # 删除重复值,都不保留

六、排序
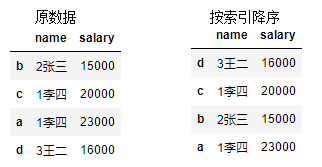
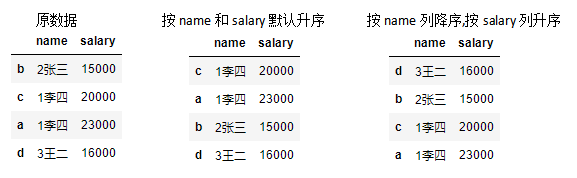
dic = {
'name':['2张三','1李四','1李四','3王二'],
'salary':[15000,20000,23000,16000]
}
df = pd.DataFrame(data=dic,index=['b','c','a','d'])
df
6.1、按索引排序
用法:df.sort_index(axis,ascending,inplace)
参数解释:
axis = 0(按行索引排序)/1(按列索引排序)
ascending = True(默认升序)/False(降序)
inplace = True(在原数据上修改)/False(默认不修改原数据)
df.sort_index(ascending=False) # 按列索引降序
6.2、按某列值排序
用法:df.sort_values(by,ascending,inplace,na_position)
参数解释:
by = [col1,col2……] 按照某几列排序
ascending = True(默认升序)/False(降序)
inplace = True(在原数据上修改)/False(默认不修改原数据) 多列时可以输入列表如[True,False]
na_position first/(缺失值排在最前面)last默认缺失值排在最后面
df.sort_values(by=['name','salary']) # 默认按照name和salary列升序
df.sort_values(by=['name','salary'],ascending=[False,True]) # 按name列降序,若name相同,按salary列升序
七、数学运算与统计函数
7.1、数学运算
| 方法 | 反转方法 | 描述 |
|---|---|---|
| add | radd | 加法 |
| sub | rsub | 减法 |
| div | rdiv | 除法 |
| floordiv | rfloordiv | 整除 |
| mul | rmul | 乘法 |
| pow | rpow | 幂次方 |
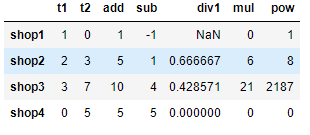
dic = {
't1':[1,2,3,0],
't2':[0,3,7,5]
}
df = pd.DataFrame(dic,index=['shop1','shop2','shop3','shop4'])
df['add'] = df['t1'].add(df['t2']) # t1+t2
df['sub'] = df['t1'].rsub(df['t2']) # t2-t1 反转
pd.options.mode.use_inf_as_na = True # 利用这句可以将inf值转为NaN
df['div1'] = df['t1'].div(df['t2']) # t1/t2 分母为0的话,输出inf无穷
df['mul'] = df['t1'].mul(df['t2']) # t1*t2
df['pow'] = df['t1'].pow(df['t2']) # t1**t2
df
7.2、数学统计函数
| 函数 | 描述 |
|---|---|
| count | 计数 |
| sum | 求和 |
| mean | 均值 |
| mad | 平均绝对方差 |
| median | 中位数 |
| min\max | 最小\大值 |
| argmin\argmax | 最小\大值的索引 |
| idxmin\idxmax | 每列最小\大值的行索引 |
| mode | 众数 |
| abs | 绝对值 |
| prod | 乘积 |
| std | 标准差 |
| var | 方差 |
| sem | 标准误 |
| skew | 偏度系数 |
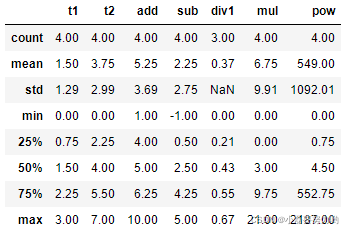
t1_min = df['t1'].min() # t1列最小值为0
t2_argmax = df['t2'].argmax() # t2列最大值为7,索引为2
print(t1_min,t2_argmax) # 0 2
# 最简单的一个方法可以查看计数、最小\大值、分位数等
round(df.describe(),2)
八、数据分组、透视与分箱
8.1、 分箱:qcut和cut
- 作用:将连续数据离散化,打上标签,方便处理
Python实现连续数据的离散化处理主要基于两个函数:
pandas.cut(x,bins,labels) 根据指定分界点对连续数据进行分箱处理
参数 x:需要分割的数据
bins:分界点
labels:标签
pandas.qcut(x,q) 可以指定箱子的数量对连续数据进行等宽分箱处理
参数 x:需要分割的数据
q:箱子数
(注意:所谓等宽指的是每个箱子中的数据量是相同的)
# 将[1992, 1983, 1922, 1932, 1973]打上标签1900——1950 和1950——2000
year = [1992, 1983, 1922, 1932, 1973] # 待分箱数据
box = [1900, 1950, 2000] # 指定箱子的分界点
res1 = pd.cut(year, box)
print(res1)
print('-'*100)
# labels参数为False时,返回结果中用不同的整数作为箱子的指示符
res2=pd.cut(year,box,labels=False)
print(res2)
# 可以看出输出结果有0和1:因为(1900,1950]<(1950,2000] 因此0代表前者,1代表后者
print('-'*100)
# 分箱之后自定义标签:50年代前和50年代后
box2 = ['50年代前','50年代后']
res3 = pd.cut(year, box, labels=box2)
print(res3)

8.2、数据分组与聚合函数:groupby
- pandas中的数据分组和聚合与数据库中SQL语句的分组聚合类似;
- 分组函数groupby(列名):根据哪几列分组;
- 聚合函数:mean\max\min\count\sum
- 格式groupby(根据哪列分组)[对哪列进行聚合操作].max()聚合函数
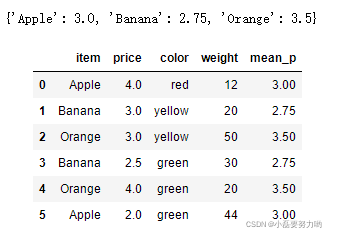
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})
# 计算出每一种水果的平均价格
df.groupby(by='item')['price'].mean()
# 将水果的平均价格汇总到原表中
dic=df.groupby('item')['price'].mean().to_dict() # 将结果转为字典
df['mean_p'] = df['item'].map(dic) # 利用map函数将其匹配 类似于excel的vlookup函数 和 SQL中的表连接操作
8.3、数据透视:povit_table和crosstab
8.3.1、 数据透视表:povit_table
- 透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
- 透视表的优点:
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
用法:pd.pivot_table(fata,index, values, columns, aggfunc,fill_value)
参数:data 数据表
index:行索引
columns:列索引
values:值
aggfunc:聚合函数
fill_value:填充值
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple','Apple'],
'price':[4,3,3,2.5,4,2,3],
'color':['red','yellow','yellow','green','green','green','green'],
'weight':[12,20,50,30,20,44,45]})
# 以(水果,颜色)分组,求其均值;显示为数据透视表
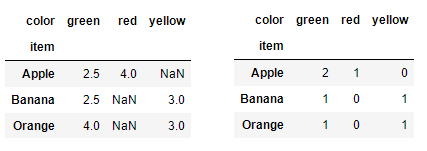
pd.pivot_table(df,index='item',columns='color',values='price',aggfunc='mean')
# 以(水果,颜色)分组,求其计数;显示为数据透视表,空值填充为0
pd.pivot_table(df,index='item',columns='color',values='price',aggfunc='count',fill_value=0)
8.3.2、数据交叉表:crosstab
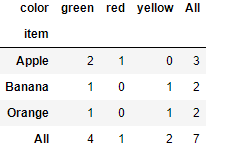
是透视表的一部分, aggfunc=count而已,一种用于计算分组的特殊透视图,对数据进行汇总
用法:pd.crosstab(index,colums, margins=True)
参数 index:分组数据,交叉表的行索引
columns:交叉表的列索引
pd.crosstab(df['item'],df['color'],margins=True)
九、数据替换
替换操作可以同步作用于Series和DataFrame中
df.replace(to_replace=,value=) 参数(原值,替换后的值)
单值替换
普通替换:替换所有符合要求的元素:to_replace=15,value='e'
按列指定单值替换:to_replace={列标签:替换值} value='value'
多值替换
列表替换:to_replace=[] value=[]
字典替换(推荐)to_replace={to_replace:value,to_replace:value}
df = pd.DataFrame({'item':['Apple','Banana','Orange','Banana'],
'price':[4,3,45,20],
'color':['red','yellow','green','red'],
'weight':[12,20,50,4]})
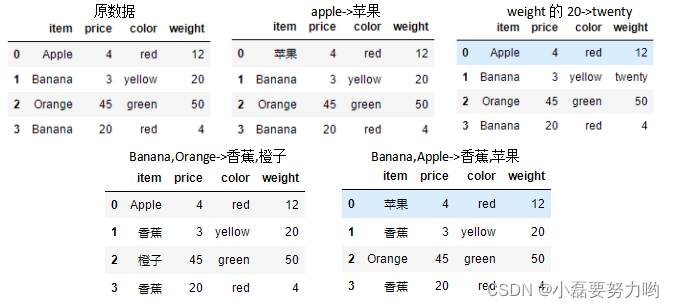
# 1、单值替换 将apple 替换为 苹果
df.replace(to_replace='Apple',value='苹果')
# 2、指定列替换 将weight中的20替换为twenty
df.replace(to_replace={'weight':20},value='twenty')
# 3、多值字典替换 将Banana替换为香蕉,Orange替换为橙子
df.replace(to_replace={'Banana':'香蕉','Orange':'橙子'})
# 4、多值列表替换 将Banana替换为香蕉,Apple替换为苹果
df.replace(to_replace=['Banana','Apple'],value=['香蕉','苹果'])
下期预告:pandas之表与表的连接合并及高级查询语句
版权声明:本文为m0_69435474原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。