目录
local模式Spark
安装
第一步:解压编译后的源码包
第二步:修改spark的配置文件
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
cp spark-env.sh.template spark-env.sh
使用spark-shell
启动验证
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
./bin/spark-shell --master local
退出spark shell客户端
spark>:quit
测试提交jar包
执行spark自带的程序jar包运算圆周率
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
100
100是计算次数
standAlone模式Spark
安装
在local模式Spark的基础上
第一步:修改配置文件
在node01修改spark-env.sh
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
vim spark-env.sh
添加以下内容:
export JAVA_HOME=/export/servers/jdk1.8.0_141
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
修改slaves文件
cp slaves.template slaves
vim slaves
将localhost修改为以下内容
node02
node03
修改spark-defaults.conf
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
添加以下内容
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
spark.eventLog.compress true
第二步:hdfs创建日志文件存放的目录
hdfs dfs -mkdir -p /spark_log
第三步:安装包分发到其他机器
node01服务器执行以下命令
cd /export/servers/
scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0/ node02://export/servers/
scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0/ node03://export/servers/
第四步:启动spark集群
在master节点(node01)上执行
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/start-all.sh
sbin/start-history-server.sh
第五步:浏览器页面访问
浏览器页面访问spark
http://node01:8080/
查看spark任务的历史日志
http://node01:4000/
使用spark-shell
node01执行以下命令进入spark-shell
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-shell --master spark://node01:7077
退出spark-shell
scala> :quit
测试提交jar包
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
100
standAlone(HA)模式Spark
安装
第一步:停止之前的spark集群
停止spark的所有进程
node01服务器执行以下命令停止spark集群
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/stop-all.sh
sbin/stop-history-server.sh
第二步:修改配置文件
修改spark-env.sh
node01服务器修改spark-env.sh
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
vim spark-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
#export SPARK_MASTER_HOST=node01 这句注释掉
export SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
# 添加以下内容,是以zookeeper的选举机制来决定alive的master节点
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
修改slaves文件(standAlone模式修改过,不用修改)
node01修改slaves配置文件
cp slaves.template slaves
vim slaves
node02
node03
修改spark-defaults.conf(standAlone模式修改过,不用修改)
spark的程序运行,我们为了方便调试开发,一般我们都会配置spark的运行日志,将spark程序的运行日志保存到hdfs上面,方便我们运行程序之后的开发调试
node01修改spark-defaults.conf
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
添加以下内容
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
spark.eventLog.compress true
第三步:hdfs创建日志文件存放的目录(创建过的就不用再创建)
hdfs dfs -mkdir -p /spark_log
第四步:配置文件分发到其他服务器
node01服务器执行以下命令进行分发
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
scp spark-env.sh node02://export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
scp spark-env.sh node03://export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
第五步:启动spark集群
node01服务器执行以下命令启动spark集群
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/start-all.sh
sbin/start-history-server.sh
node02服务器启动master节点
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/start-master.sh
node03上也可以启动master节点,但是有两个足以形成HA(高可用)了。
进入spark-shell
spark的HA模式,进入spark-shell
node01执行以下命令进入spark-shell
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/
bin/spark-shell --master spark://node01:7077,node02:7077
只做测试,进入即退出即可
测试提交jar包
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077,node02:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
100
on-yarn模式Spark
安装
on-yarn模式的安装继承standAlone的安装即可,不用专门安装。on-yarn模式是指spark集群基于yarn集群来进行任务资源调度,而不是基于spark自身。这与安装无关,与是否高可用无关,只要是集群形式的spark即可。
但是仍然需要修改spark-env.sh文件,修改如下:
添加以下内容:
export HADOOP_CONF_DIR=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
export YARN_CONF_DIR=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
然后将spark-env.sh用scp分发给node02和node03。
完成修改spark-env.sh文件后,将spark加入到环境变量中:
三台机器执行以下命令添加spark环境变量
vim /etc/profile
在profile添加
export SPARK_HOME=/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
export PATH=:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
最后三台机器都执行source /etc/profile。
on-yarn模式提交jar包之两种方式的介绍
spark on yarn client模式提交
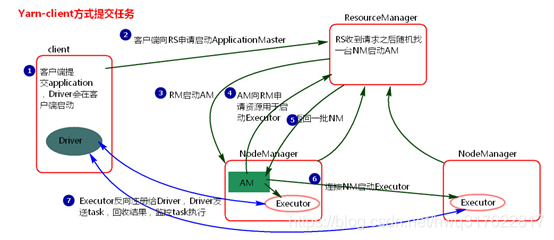
- 客户端提交一个Application,在客户端启动一个Driver进程。
- Driver进程会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
- RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
- AM启动后,会向RS请求一批container资源,用于启动Executor.
RS会找到一批NM返回给AM,用于启动Executor。 - AM会向NM发送命令启动Executor。
- Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
总结:
- Yarn-client模式是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
- ApplicationMaster的作用:为当前的Application申请资源;给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
spark on yarn cluster模式提交任务
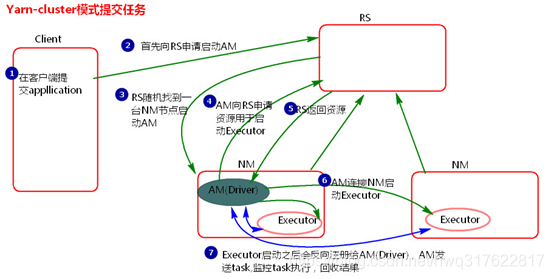
执行流程
- 客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
- RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
- AM启动,AM发送请求到RS,请求一批container用于启动Executor。
- RS返回一批NM节点给AM。
- AM连接到NM,发送请求到NM启动Executor。
- Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
总结
- Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
- ApplicationMaster的作用:为当前的Application申请资源;给nodemanager发送消息 启动Excutor;任务调度。这里和client模式的区别是AM具有调度能力,因为其就是Driver端,包含Driver进程
- 停止集群任务命令:yarn application -kill applicationID
测试提交jar包
spark on yarn client模式提交
集群任意机器执行
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
10
spark on yarn cluster模式提交
集群任意机器执行
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
10