因果推断-增益模型综述 :http://proceedings.mlr.press/v67/gutierrez17a/gutierrez17a.pdf
| 名词/缩写 | 英文全称 | 名词解释 | 备注 |
| treatment | 干预、实验组 | ||
| control | 不干预、控制组 | ||
| uplift model | uplift model | 增益模型: 预测某种干预treatment的增量的模型 | |
| CE | causal effect | 因果效应: 用户在干预和不干预的情况下的提升,即干预前后结果的差值。 | 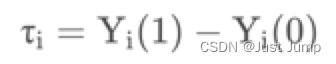 |
| ACE | Average Causal Effect | 平均因果效应: 取所有用户的因果效应期望的估计值来衡量整个用户群的效果。 | |
| ITE | Individual Treatment Effect | 个体因果效应() | |
| ATE | Average Treatment Effect | 平均因果效应 | 所有用户的因果效应期望。 |
| CATE | Conditional Average Treatment Effect | 条件平均因果效应 | 所有用户的因果效应期望。 Conditional是指基于用户的特征。 |
| CIA | Conditional Independence Assumption | 条件独立假设 | 用户特征和干预策略相互独立。 AB实验的两组样本在特征分布上基本一致,即满足CIA。 |
| ATT | 只关注treatment的ATE | ||
| ATC | 只关注control的ATE | ||
| Meta-learning methods | Meta-learning methods | 元学习方法 | |
| S-learner | Conditional Outcome Modeling (COM) | 将treatment作为特征,干预组和非干预组一起训练,解决bias不一致的问题。 问题: 特征维度很高,干预/不干预只有1-dim,容易导致treatment效果丢失。 | |
| T-Learner | grouped Conditional Outcome Modeling (Grouped COM / GCOM) | 为解决COM中增益效果提升趋向于0的问题。模型加强了对T的权重,其他流程跟COM一样。 | |
| X-Learner | 在T-learner基础上,利用全量的数据进行预测,主要解决Treatment组间数据量差异较大的情况。 | ||
| R-learner | R-learner的思路将问题转化为定义损失函数R-loss的形式进行学习训练,更专注残差。 | ||
| 标签转换方法 | The Class Transformation Method | 适用于treatment、 outcome都是二分类的情况。通过将预测目标做转换,实现one model的预测。
| |
| 增量直接建模 | Tree-Based Method | ||
| 分布散度 | 常见的分布散度有KL散度、欧式距离、卡方散度。 | ||
| 因果森林 | CausalForest | 因果森林的核心是把一个个建立好的因果树 causal tree(或 uplift tree)做组合ensemble,把每棵因果树计算出的干预结果取平均。 | |
| CTS算法 | Contextual Treatment Selection | ||
| 基于神经网络的方法 | NN-Based Method | ||
| DragonNet | |||
| uplift柱状图 | 计算流程: (1)在测试集上,将实验组和对照组分别按照模型预测出的增量由高到低排序,根据用户占比,分别划分10等份,即Top10%, 20%,…100% (2)分别计算Top10%, 20%,…100%的用户平均预测转化概率,即Avg(y-pred),预测分数的均值,然后相减作为这个十分位分组内的提升uplift,绘制柱状图 | 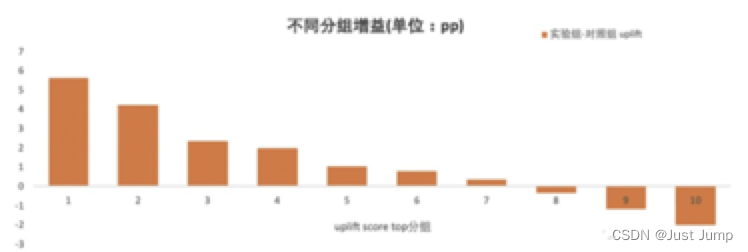 | |
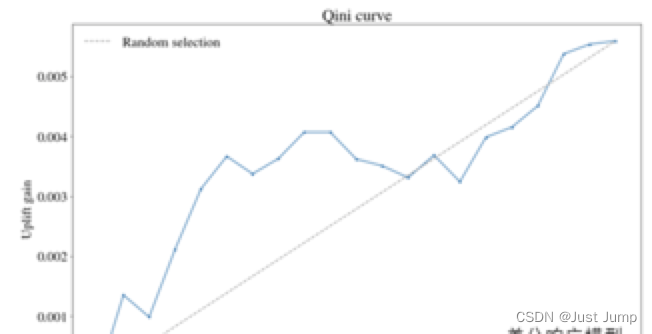
| 基尼曲线 | Qini Curve | 计算流程: (1)在测试集上,将实验组和对照组分别按照模型预测出的增量由高到低排序,根据用户占比,分别划分10等份,即Top10%, 20%,…100% (2)计算Top10%, 20%,…100%的Qini系数,生成Qini曲线数据(Top10%, Q(Top10%)),…(Top100%, Q(Top100%)) | 1、Qini系数计算公式:Q(i)
|
| 调整Qini曲线 | Adjusted Qini Curve | 调整Qini曲线是为了避免实验组和对照组数据不均衡而导致Qini系数失真而设计的。 | 1、Aqini系数计算公式:
|
| AUUC 增益曲线面积 | Area Under the Uplift Curve | uplift曲线如何绘制? 使用AUUC评价模型时,优点是可以避免实验组和对照组用户数量差别较大导致的指标不可靠问题。 但,当分桶时,对照组边界点预估出的增量与实验组边界点的预估有较大差别的时候,Qini曲线和AUUC两个指标都不可靠。要选AUUC的另一个计算方法。 | 1、AUUC指标计算公式:G(i)
|
| AUUC非平衡情况分析 | 如果实验组和对照组满足随机性,但不平衡,即不是1:1或 P(T=1|x)=q, q!=0.5概率。那么增益曲线uplift curve: |  | |
| AUUC优化-降低方差 | |||
| 累积增益曲线 | Cumulative Gain Curve | 1、指标计算公式:
|

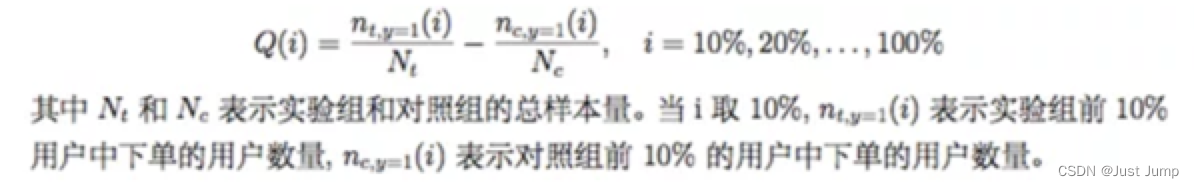
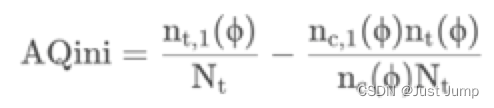


版权声明:本文为eylier原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。