我们先来看看需要采集的网站:
以综艺类搜索页第一页为例子:http://list.mgtv.com/1/---------2-1---.html,其中一页有60部综艺信息
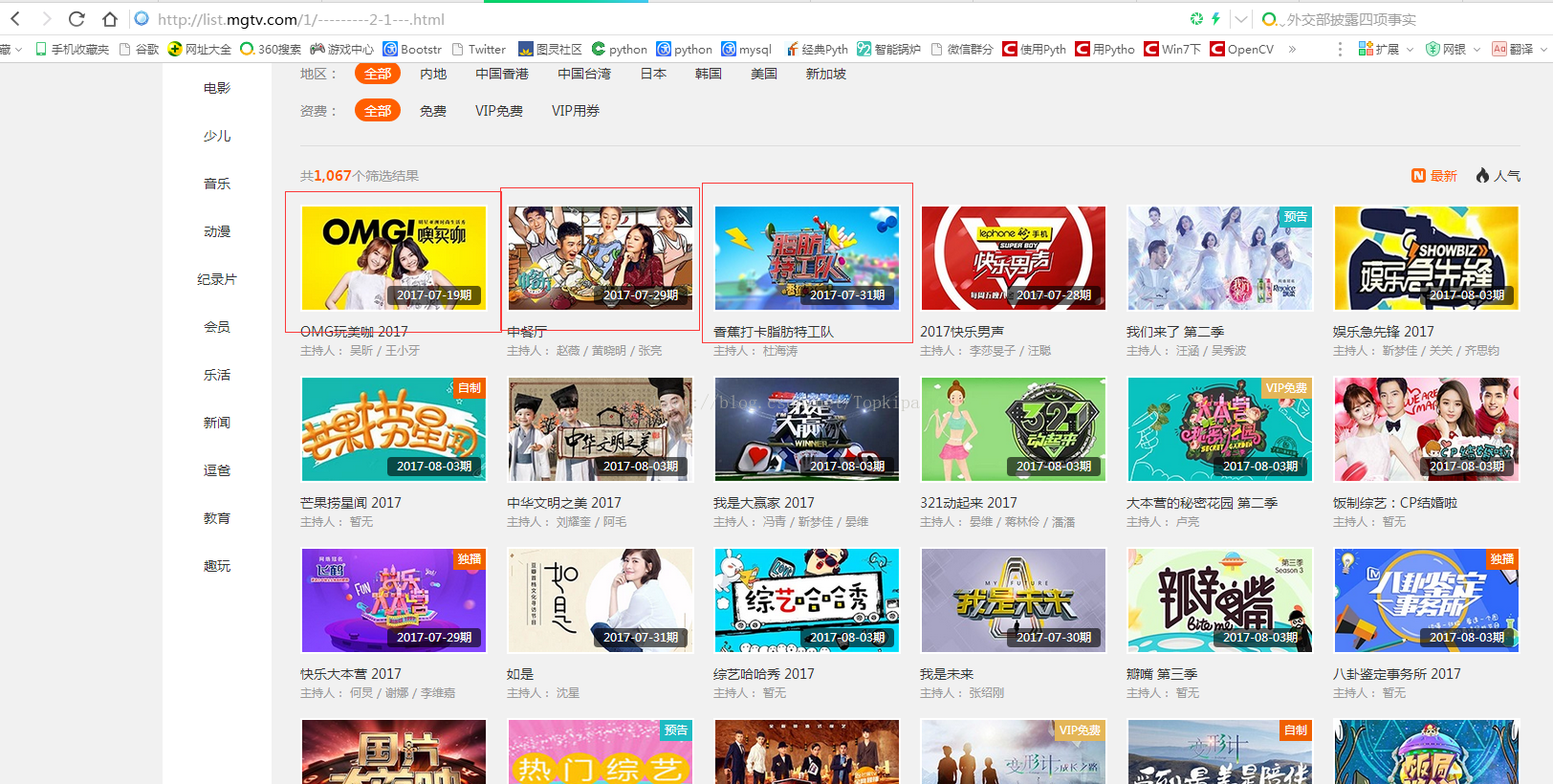
信息:
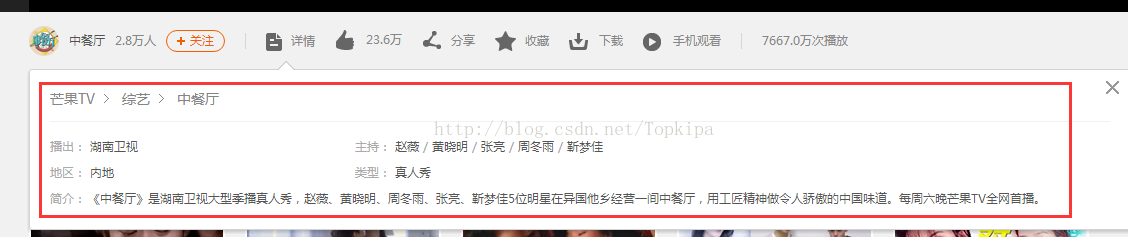
教程:
创建工程:具体方法前面教程都有,创建完了之后,整体大概如下图:
data.py为主要运行的文件,贴上代码:


我们来看一下re_search.py 文件:
# -*- coding: utf-8 -*-
import re
def search(text,html):
if re.search(r'%s'%(text),html):
message = re.search(r'%s'%(text),html).group(1)
else:
message = ''
return message就是一个简单的正则。
关于data.py:
# -*- coding: utf-8 -*-
import scrapy
from re_search import *
import re
from variety.items import VarietyItem
class DataSpider(scrapy.Spider):
name = "data"
allowed_domains = ["mgtv.com"]
start_urls = ['http://list.mgtv.com/1/---------2-1---.html']
def parse(self, response):
html = response.body
body = search('<div class="m-result-list">([\s\S]*?)<div class="m-result-list">',html)
li_div = re.findall(r'<li[\s\S]*?>([\s\S]*?)</li>',body)[0:-1]
for index,li in enumerate(li_div):
release = search('<em class="u-meta">([\s\S]*?)</em>',li).strip()
hosts = search(r'主持人:([\s\S]*?)</span>',li)
title = search('<a class="u-title"[\s\S]*?>([\s\S]*?)</a>',li)
if '暂无' in hosts:
hosts = ''
else:
hosts = '|'.join(re.findall(r'<a[\s\S]*?>([\s\S]*?)</a>',hosts))
img = re.search(r'<img[\s\S]*?src="([\s\S]*?)"',li).group(1)
href = re.search(r'<a[\s\S]*?class="u-video[\s\S]*?href="([\s\S]*?)"',li).group(1)
if re.search(r'style="background:#F06000;">([\s\S]*?)</i>',li):
lable = re.search(r'style="background:#F06000;">([\s\S]*?)</i>',li).group(1)
else:
lable = ''
yield scrapy.Request(url=href,callback=self.parse_play,meta={'img':img,'lable':lable,'title':title,\
'release':release,'host':hosts})
def parse_play(self,response):
html = response.body
item = VarietyItem()
title = response.meta['title']
release = response.meta['release']
host = response.meta['host']
img = response.meta['img']
broadcast = search('播出:</span>[\s\S]*?<a[\s\S]*?>([\s\S]*?)</a>',html)
summary = search('<span class="details">([\s\S]*?)</span>',html)
if re.search(r'类型:</span>([\s\S]*?)</p>',html):
types = re.search(r'类型:</span>([\s\S]*?)</p>',html).group(1).strip()
types = '|'.join(re.findall(r'<a[\s\S]*?>([\s\S]*?)</a>',types))
else:
types = ''
infoid = re.search(r'b/([\s\S]*?)/[\s\S]*?.html',response.url).group(1)
areas = search('地区:</span>([\s\S]*?)</p>',html).strip()
area = '|'.join(re.findall(r'<a[\s\S]*?>([\s\S]*?)</a>',areas)).replace('国内','')
url = 'http://www.mgtv.com/h/'+str(infoid)+'.html'
print url
print infoid
print title
print img
print area
print release
print host
print broadcast
print summary
print types
print response.meta['lable']
print ''
item['url'] = url
item['infoid'] = infoid
item['title'] = title
item['img'] = img
item['area'] = area
item['release'] = release
item['host'] = host
item['broadcast'] = broadcast
item['summary'] = summary
item['types'] = types
item['lable'] = response.meta['lable']
yield item接下来就是设置setting.py,pipelines.py.items.py了:
setting:配置文件
pipelines:数据存储
main:调用cmdline运行程序
建议大家采数据的时候用正则吧,虽然很繁琐,但是比较准确,同时,做循环的时候用enumerate()代替,如果大家还有不懂的,可以留言@我。
版权声明:本文为Topkipa原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。