指标管理作为数据资产的一部分,在数据的应用中可以发挥重要作用。指标管理也与数据中台中的OneData完美契合,属于其中一部分。指标库可以统一管理、定义数据口径并实现复用、提高效率。指标组合展示借助于”方案“来体现,一个方案可像积木一样组装多个指标(同一主维度),只需页面点选就自动生成报表数据、可用于数据分析和数据探索。
定义了指标后就可直接应用,不写sql和代码,而且指标可以配置多个查询条件,比如定义了一指标:门店销售额,汇总维度是门店,同时维护查询维度包含客户性别,则指标数据在展示时,可以选择查看门店男性客户销售额、女性客户销售额。
一、基本原理
1、kylin
大数据OLAP主要分两派,MPP和预计算,都是为了解决大数据查询下很慢的问题。kylin是预计算,kylin提前将hive数据做多维度聚合汇总生成一个数据立文体(cube),当用sql查询时转化为查询cube,将hive查询变成了一个HBase查询的问题,构建为KV数据存入HBase里,基本上可以达到一个亚秒级别的查询。
2、指标管理
指标管理的核心就是将定义的指标进行组合时,生成sql提交给kylin,接收结果并展示。
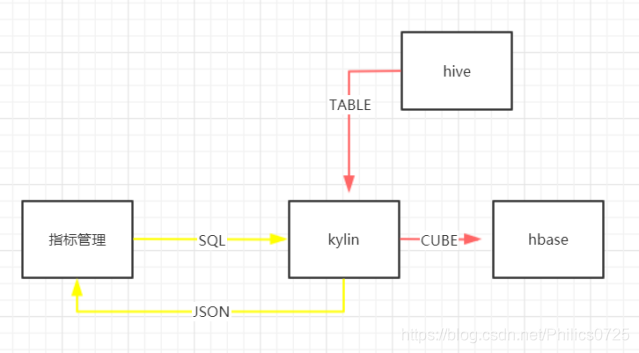
二、环境准备
1、搭建kylin环境(略)
2、准备测试数据
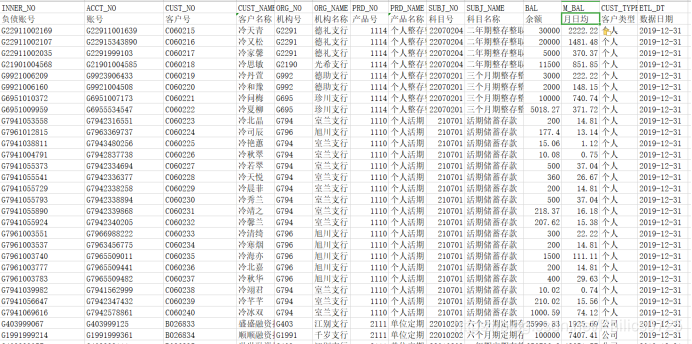
存款数据MDM_DEP_ACCT_DTL_HIS,包括负债账号,账号,客户号,客户名称 ,机构号,机构名称,产品号,产品名称 ,科目号,科目名称,余额,月日均,客户类型,数据日期
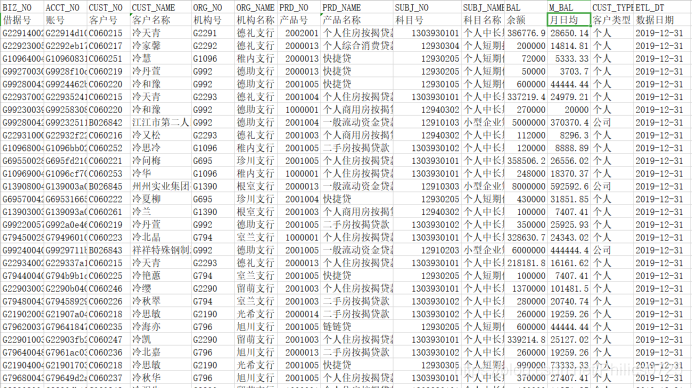
贷款数据MDM_LNS_ACCT_DTL_HIS,包括借据号,账号,客户号,客户名称 ,机构号,机构名称,产品号,产品名称 ,科目号,科目名称,余额,月日均,客户类型,数据日期
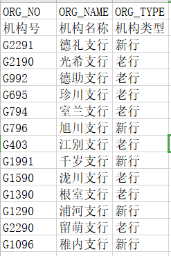
主数据:机构信息DIM_ORG_INFO,包括机构号、机构名,机构类型
三、kylin构建cube
1、引入hive表
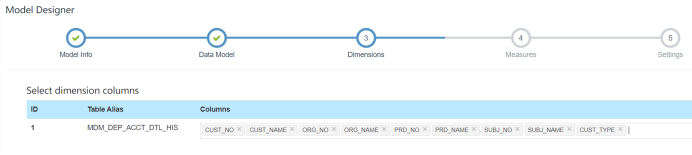
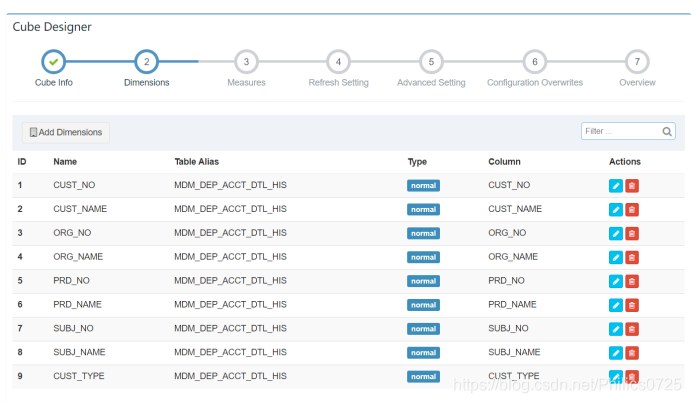
2、创建model,将表映射为model,可以去掉不需要的字段,减少维度,比如我去掉了负债账号(pk)、账号等粒度很小的字段。
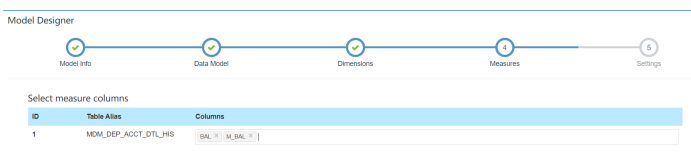
度量即我们需要汇总的数值,也可以去掉不需要的。
选择分区字段
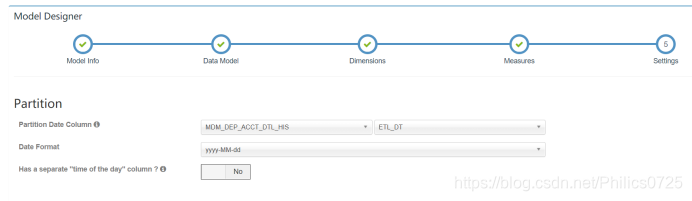
所需的3个model
3、创建cube
选择model,可以具体要求再进一步减少维度,减少维度可减少cube的计算时间。
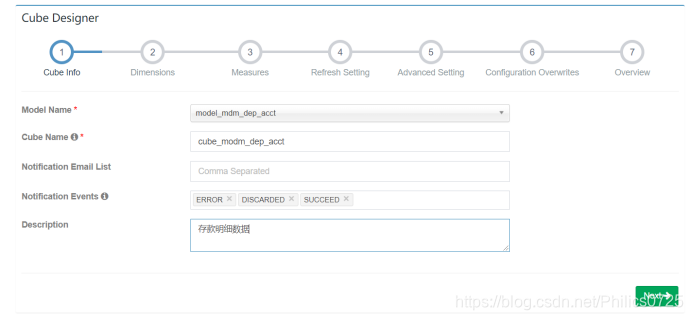
我这边为满足指标的多条件查询都保留了model中的维度
度量的选择也是一样的,默认会生成一个count度量 ,我主要用金额的 sum值
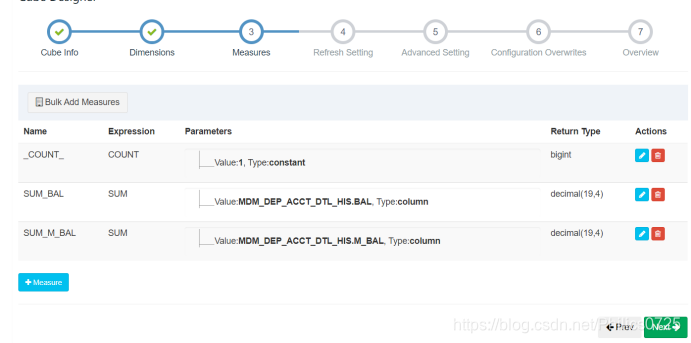
4、cube计算(build cube)
这就是kylin预处理的核心,分区表需要指定分区,可由ETL接管做定时跑批
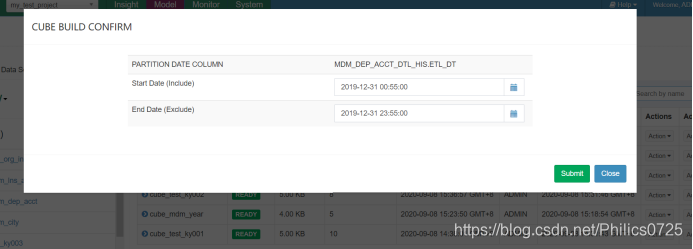
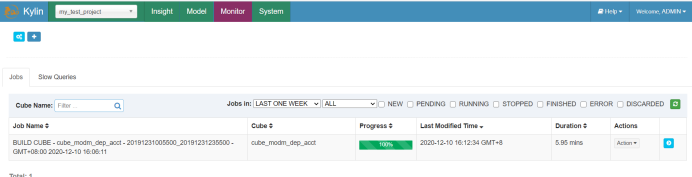
计算过程提供监控界面
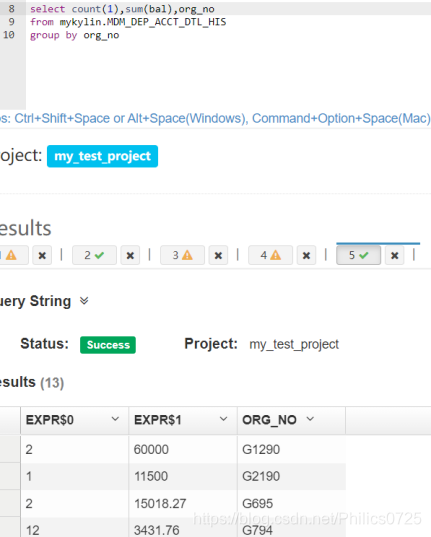
计算完成后,可在kylin的sql查询界面上验证,正常返回结果
5、其它ETL
a、将hive表元数据信息导入到指标管理,会用到列的注释信息
b、将hive表中的维度字段的字典数据导入到指标管理,做查询条件下拉
四、指标管理
基于springboot、vue、element-ui、echarts的前后端分离项目
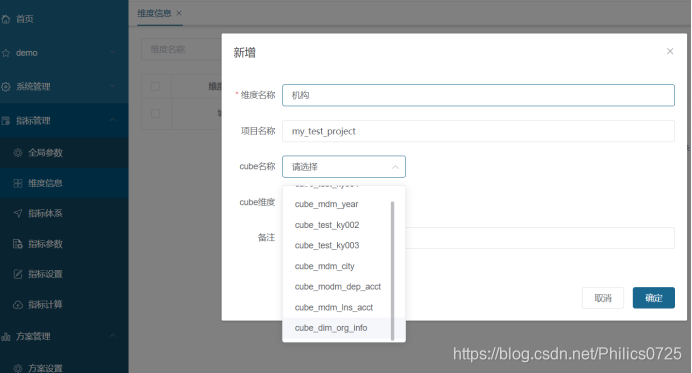
1、主维度定义
数据汇总维度,一般为报表中左边第一列内容。定义时引用hive中dim维度表生成的cube。
2、指标定义
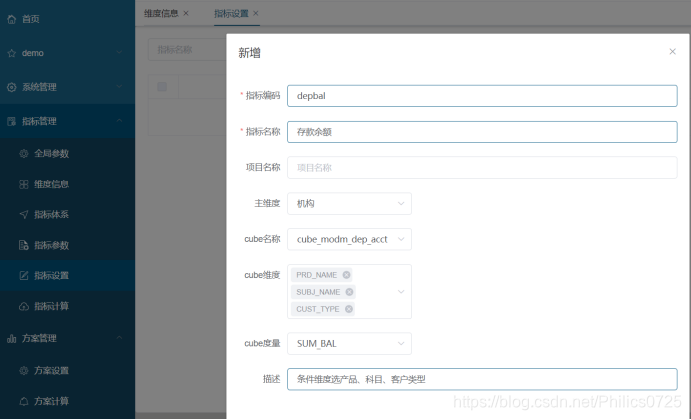
定义时引用hive事实表生成的cube,cube维度可以多选,为指标的查询维度,cube度量只能选一个,是指标的业务含义。比如销售额金额、存款时点余额等。
这处我选择了产品名称、科目名称、客户类型做为查询维度,度量选了金额的汇总值。
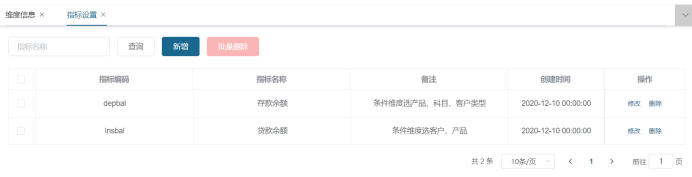
同样定义贷款余额指标
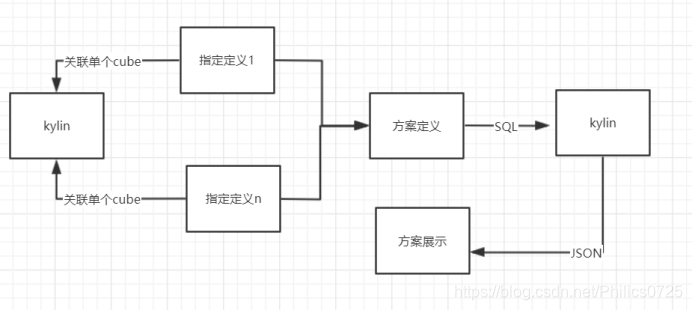
3、方案定义
首先选择主维度,同一方案的指标必须为同一汇总维度。然后增加指标
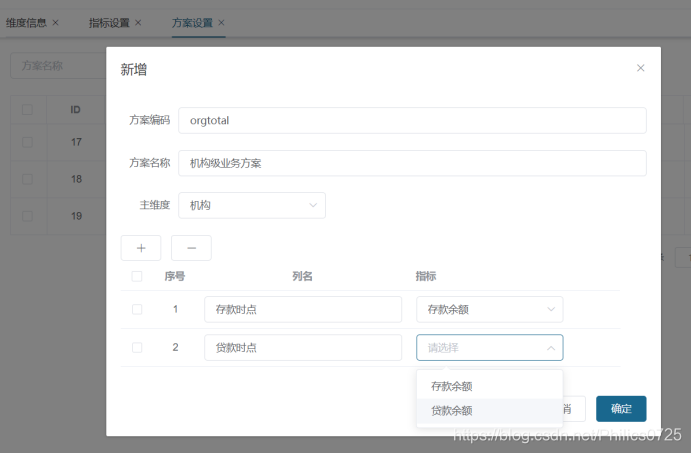
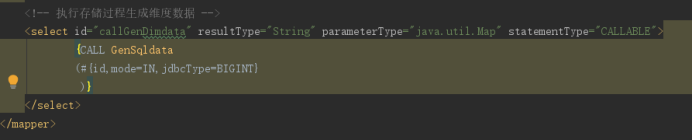
通过存储过程生成 sql 语句并保存
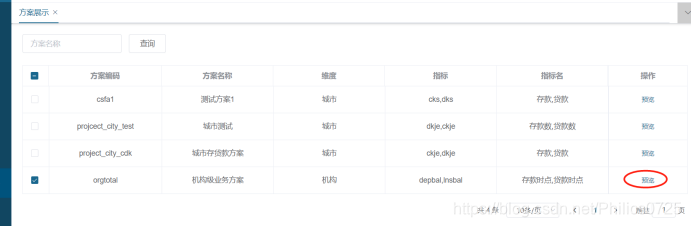
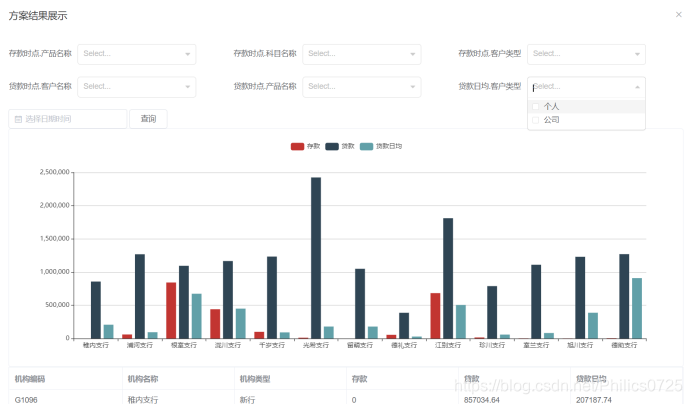
4、方案展示
方案维护后,可进行数据预览
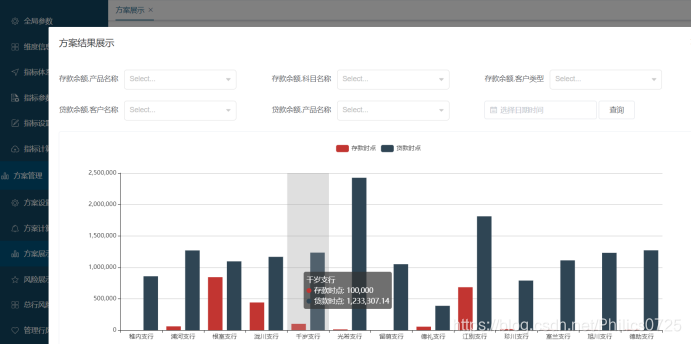
查询条件框中的查询条件为自动扩展显示,来源为指标定义时选择的查询维度。
按指标名称.查询维度 进行展示。默认进来不加条件进行展示,数据分两部分,上面是eccharts柱图,下面是列表。查询条件、图表、列表都是根据方案定义自动扩展显示。
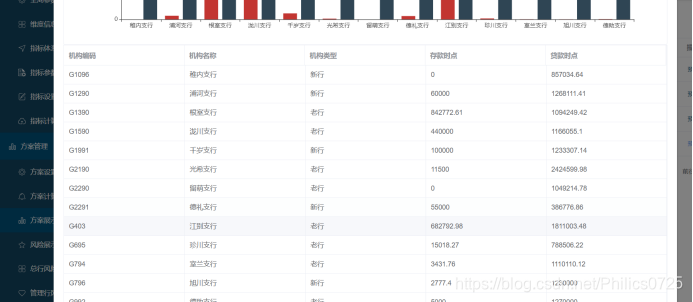
明细列表数据可以显示主维度表所有字段,比如机构类型
其中查询条件的值可以多选,选择条件及日期后,按查询条件重新拼装sql并返回新的结果。数据发生了变化
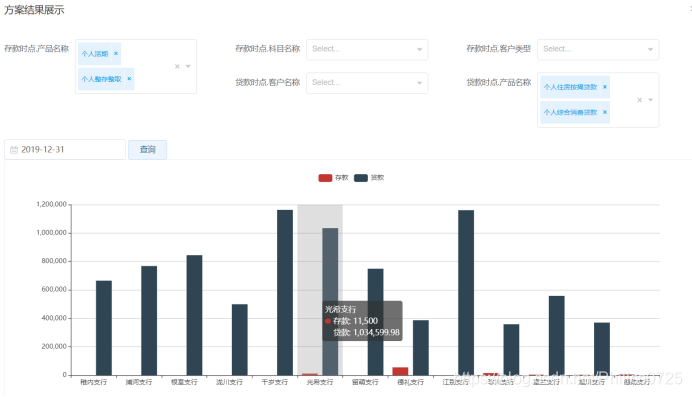
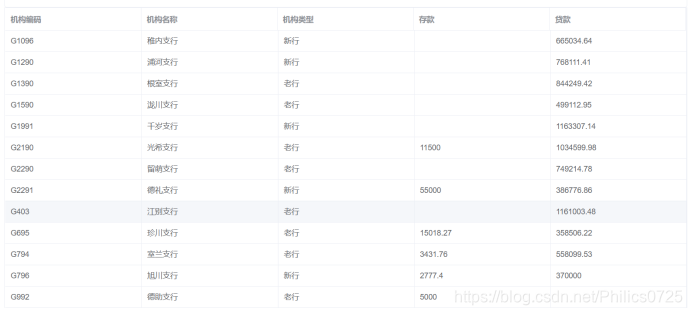
5、方案扩展
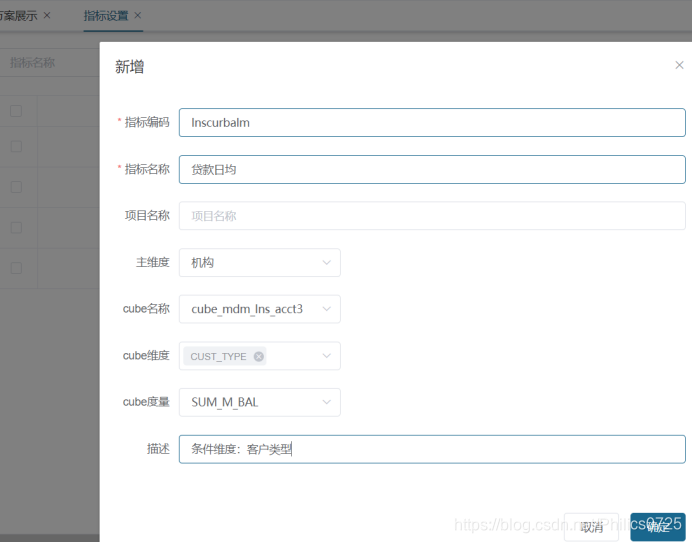
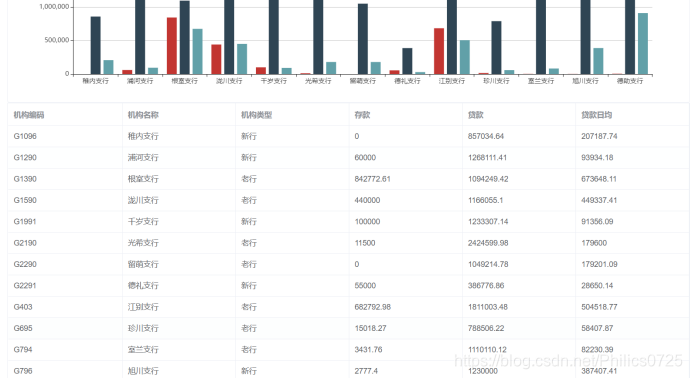
增加新的一个指标,贷款日均,条件维度选客户类型
方案中增加这个指标,保存后会更新sql
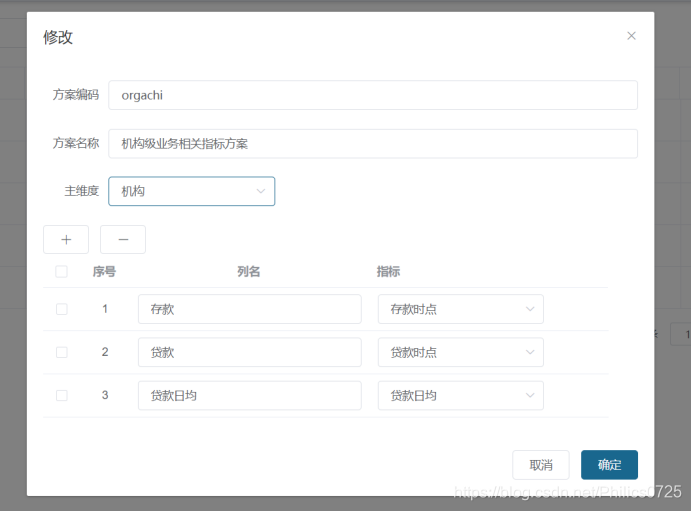
方案展示时,查询条件自动带出新指标的查询条件,图表自动增加新的列,列表也自动显示新的指标列。
6、后续
优化亿点、扩展亿点