1: zookeeper 集群搭建
这里使用三台虚拟机器完成zookeeper 集群的搭建
192.168.217.128 2181 2888 3888
192.168.217.135 2181 2888 3888
192.168.217.136 2181 2888 3888
其中 2181 是 zookeeper 默认的服务通信端口, 2888 和3888 是集群之间
节点通信的算口 和 节点选举使用的端口
分别上传 zk 的 压缩包 到zookeeper 用户的家目录下 解压 重命名

然后 分别在三台机器在 zk 的安装目录下 新建 data 目录 mkdir data
然后 data 中分别 添加 myid 文件 并在其中分别追加值 1 ,2, 3 这三个值对应下面将要配置集群信息的 server.x

然后修改 conf 文件下的 配置
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
然后 在三个机器都添加 如下配置
server.1=192.168.217.128:2888:3888
server.2=192.168.217.135:2888:3888
server.3=192.168.217.136:2888:3888
并且修改 默认的dataDir=/temp/data 为
dataDir=/home/zookeeper/zk3.6/data

分别启动 三个机器的 zk 服务
cd /home/zookeeper/zk3.6/bin
./zkServer.sh start 启动服务

./zkServer.sh status 查看服务和集群节点状态

创建节点进行实验 在 128 上进行节点创建 ,在 135 和136上获取系欸但数据


自此集群搭建完成
./zkServer.sh stop 关闭集群

2:给普通linux用户 添加su 切换权限
使用root 用户登录 为 新建的 zookeeper 用户添加 su 权限
执行如下命令:
cd root
visudo
切换到root用户下,cd root,运行visudo命令,visudo命令是用来编辑修改/etc/sudoers配置文件
找到如下图所示,标出红线的一行 并在这一行下添加
root ALL=(ALL) ALL
zookeeper ALL=(ALL) ALL

此时就可以切换了

如果想以后每次使用sudo的时候不再验证密码,可以在刚刚的sudoers文件做如下操作:

timestamp_timeout=-1 只需验证一次密码,以后系统自动记忆,runasp 需要root密码,如果不加默认是要输入普通账户的密码.
3:安装zk 4字命令需要配合使用的nc命令服务
yum install nc.x86_64 使用这个安装如果找不到
可以执行如下命令
yum erase nc
wget http://vault.centos.org/6.6/os/x86_64/Packages/nc-1.84-22.el6.x86_64.rpm
rpm -iUv nc-1.84-22.el6.x86_64.rpm
安装完成之后 使用nc --help 查看是否安装成功

4:基础命令学习
基本的增删改查 请自行查阅官网: ZooKeeper: Because Coordinating Distributed Systems is a Zoo
主要将一些 操作多一点的命令:
注册事件监听命令 ,老的版本 使用 在命令末尾 添加 watch 命令
在 3.5.9 版本之后 使用 -w 参数 来表示
例如注册是一个监听时间 ,然后在另外一个 会话中 修改这个节点 ,将会监听到 该事件的变化
![]()
修改该节点
![]()
事件监听

这种事件监听是一次性的
对于节点的权限 使用 setAcl 和getAcl 来实现 ,如

ACL 权限控制,使用:schema:id:permission 来标识,主要 3 个部分组成:
- 权限模式(Schema):鉴权的策略
- 授权对象(ID)
- 权限(Permission)
ZooKeeper的权限控制是基于每个znode节点的,需要对每个节点设置权限
每个znode支持设置多种权限控制方案和多个权限
子节点不会继承父节点的权限,客户端无权访问某节点,但可能可以访问它的子节点
schema 主要有以下几种:
| world | 只有一个用户:anyone,代表所有人(默认) |
| ip | 使用IP地址认证 |
| auth | 使用已添加认证的用户认证 |
| digest | 使用“用户名:密码”方式认证 |
- world: 它下面只有一个id anyone, world:anyone代表任何人,zookeeper中对所有人有权限的结点就是属于world:anyone的
- auth: 它不需要id, 只要是通过authentication的user都有权限(zookeeper支持通过kerberos来进行authencation, 也支持username/password形式的authentication)
- digest: 它对应的id为username:BASE64(SHA1(password)),它需要先通过username:password形式的authentication
- ip: 它对应的id为客户机的IP地址,设置的时候可以设置一个ip段,比如ip:192.168.1.0/16, 表示匹配前16个bit的IP段
- super: 在这种scheme情况下,对应的id拥有超级权限,可以做任何事情(cdrwa)
permission: zookeeper目前支持下面一些权限:
- CREATE(c): 创建权限,可以在在当前node下创建child node
- DELETE(d): 删除权限,可以删除当前的node
- READ(r): 读权限,可以获取当前node的数据,可以list当前node所有的child nodes
- WRITE(w): 写权限,可以向当前node写数据
- ADMIN(a): 管理权限,可以设置当前node的permission
权限相关命令
| getAcl | getAcl <path> | 读取ACL权限 |
| setAcl | setAcl <path> <acl> | 设置ACL权限 |
| addauth | addauth <scheme> <auth> | 添加认证用户 |
world方式 :
命令语法 : setAcl <path> world:anyone:<acl>
[zk: localhost:2181(CONNECTED) 0] create /node1 1
Created /node1
[zk: localhost:2181(CONNECTED) 1] getAcl /node1
'world,'anyone #默认为world方案
: cdrwa #任何人都拥有所有权限
#可以用以下方式设置:
[zk: localhost:2181(CONNECTED) 2] setAcl /node1 world:anyone:cdrwa
cZxid = 0x19000002a1
ctime = Thu May 11 22:00:00 CST 2017
...
ip 方式 : 语法 setAcl <path> ip:<ip>:<acl>
[zk: localhost:2181(CONNECTED) 0] create /node2 1
Created /node2
[zk: localhost:2181(CONNECTED) 1] setAcl /node2 ip:192.168.217.128:cdrwa #设置IP:192.168.100.1 拥有所有权限
cZxid = 0x1900000239
[zk: localhost:2181(CONNECTED) 2] getAcl /node2
'ip,'192.168.100.1
: cdrwa
#使用IP非 192.168.217.129 的机器
[zk: localhost:2181(CONNECTED) 0] get /node2
Authentication is not valid : /node2 #没有权限
[zk: localhost:2181(CONNECTED) 1] delete /node2 #删除成功(因为设置DELETE权限仅对下一级子节点有效,并不包含此节点)
Auth 方式:
addauth digest <user>:<password> #添加认证用户
setAcl <path> auth:<user>:<acl>
[zk: localhost:2181(CONNECTED) 0] create /node3 1
Created /node3
[zk: localhost:2181(CONNECTED) 1] addauth digest tester:123456 #添加认证用户
[zk: localhost:2181(CONNECTED) 2] setAcl /node3 auth: tester:cdrwa
cZxid = 0x19000002b8
ctime = Thu May 11 22:00:00 CST 2017
[zk: localhost:2181(CONNECTED) 3] getAcl /node3
'digest,'yoonper:UvJWhBril5yzpEiA2eV7bwwhfLs=
: cdrwa
[zk: localhost:2181(CONNECTED) 4] get /node3
1 #刚才已经添加认证用户,可以直接读取数据,断开会话重连需要重新addauth添加认证用户
cZxid = 0x1900000418
ctime = Thu May 11 22:00:00 CST 2017
Digest 方式:
先将密码做成密文的
echo -n <user>:<password> | openssl dgst -binary -sha1 | openssl base64
然后添加到命令中
setAcl <path> digest:<user>:<password>:<acl>
echo -n tester:123456 | openssl dgst -binary -sha1 | openssl base64
UvJWhBril5yzpEiA2eV7bwwhfLs=
[zk: localhost:2181(CONNECTED) 0] create /node4 1
Created /node4
#使用是上面算好的密文密码添加权限:
[zk: localhost:2181(CONNECTED) 1] setAcl /node4 digest:tester:UvJWhBril5yzpEiA2eV7bwwhfLs=:cdrwa
cZxid = 0x19000002e3
ctime = Thu May 11 22:00:00 CST 2017
mZxid = 0x19000002e3
[zk: localhost:2181(CONNECTED) 2] getAcl /node4
'digest,'tester:UvJWhBril5yzpEiA2eV7bwwhfLs=
: cdrwa
直接读取 获取不到
[zk: localhost:2181(CONNECTED) 3] get /node4
Authentication is not valid : /node4 #没有权限
注册权限之后,再获取
[zk: localhost:2181(CONNECTED) 4] addauth digest tester:123456 #添加认证用户
[zk: localhost:2181(CONNECTED) 5] get /node4
1 #成功读取数据
cZxid = 0x1900000420
ctime = Thu May 11 22:00:00 CST 2017
mZxid = 0x1900000420
acl命令行super超级管理员
修改 zkServer.sh
vim zkServer.sh # 找到nohup那一行,加入以下内容
"-Dzookeeper.DigestAuthenticationProvider.superDigest=user:HYGa7IZRm2PUBFiFFu8xY2pPP/s="

user是用户名,后面那一大串是加密后的密文密码
修改完之后,需要重启zookeeper服务才能生效 ./zkServer.sh restart
# zkCli.sh
[zk: localhost:2181(CONNECTED) 9] ls /hadoop # ls一个无权限的节点
Authentication is not valid # 权限不够
[zk: localhost:2181(CONNECTED) 10] addauth digest user:123456 # 登录超级管理员用户,这里登录用的是明文密码
[zk: localhost:2181(CONNECTED) 11] ls /hadoop # 然后再次ls
hadoop # 这次就可以ls到了
====================================================
zookeeper 其他4 字命令:
stat

配合 nc 命令来执行 ,需要加入ip白名单 到 zoo.cfg 中
![]()
在需要被远程 使用4 字命令的机器上.修改 zoo.cfg 在末尾添加 4lw.commands.whitelist=*
[root@study-01 ~]# echo wchc |nc 192.168.135.129 2181
wchc is not executed because it is not in the whitelist. # 可以看到,提示这是不在白名单列表里的命令
cd /usr/local/zk3.6/conf/
vim zoo.cfg # 在文件末尾添加如下内容
4lw.commands.whitelist=*
./zkServer.sh restart # 重启zk服务
echo wchc |nc 192.168.217.135 2181 # 这时就可以使用了

此时 验证 在 128 的机器 去使用 4字命令 + nc 获取 节点状态

 其他四字命令用法也一样
其他四字命令用法也一样
四字命令列表和用法请参考官网:
ZooKeeper: Because Coordinating Distributed Systems is a Zoo
5: zookeeper java api 和分布式锁
代码: java api 链接zk 集群
public static void main(String[] args) {
try {
final CountDownLatch countDownLatch=new CountDownLatch(1);
ZooKeeper zooKeeper=
new ZooKeeper("192.168.217.135:2181," +
"192.168.217.128:2181,192.168.217.136:2181",
5000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if(Event.KeeperState.SyncConnected==event.getState()){
//如果收到了服务端的响应事件,连接成功
countDownLatch.countDown();
}
}
});
countDownLatch.await();
//CONNECTED
System.out.println(zooKeeper.getState());
}
}
其他代码:
GitHub - wanglei111000/zkOriginalJavaApi
5.1: 分布式锁实现
zk 实现分布式锁 主要是利用了 zk 的临时有序结点的特性 以及 watcher 监听机制
主要有以下几个方面要实现
(1)一把分布式锁通常使用一个Znode节点表示;如果锁对应的Znode节点不存在,首先创建Znode节点。这里假设为“/locks”,代表了一把需要创建的分布式锁。当一个客户端成功创建一个节点,另外一个客户端是无法创建同名的节点(达到互斥的效果)
(2)抢占锁的所有客户端,使用锁的Znode节点的子节点列表来表示;如果某个客户端需要占用锁,则在“locks”下创建一个临时有序的子节点。所有临时有序子节点,尽量共用一个有意义的子节点前缀。比如,如果子节点的前缀为“/locks/seq-”,则第一次抢锁对应的子节点为“/locks/seq-000000000”,第二次抢锁对应的子节点为“/locks/seq-000000001”,以此类推
(3)判定客户端是否占有锁
客户端创建子节点后,需要进行判断:自己创建的子节点,是否为当前子节点列表中序号最小的子节点。如果是,则认为加锁成功;如果不是,则监听前一个Znode子节点变更消息,等待前一个节点释放锁。
(4)一旦队列中的后面的节点,获得前一个子节点变更通知,则开始进行判断,判断自己是否为当前子节点列表中序号最小的子节点,如果是,则认为加锁成功;如果不是,则持续监听,一直到获得锁。
(5)获取锁后,开始处理业务流程。完成业务流程后,删除自己的对应的子节点,完成释放锁的工作,以方面后继节点能捕获到节点变更通知,获得分布式锁。
代码实现 https://github.com/wanglei111000/zkLockNew
6:curator 封装的java api
Curator 是 Netflix 公司开源的一套 zookeeper 客户端框架,解决了很多 Zookeeper 客户端非常底层的细节开发工作,包括连接重连、反复注册 Watcher 和 NodeExistsException 异常等。
Curator 包含了几个包:
- curator-framework:对 zookeeper 的底层 api 的一些封装。
- curator-client:提供一些客户端的操作,例如重试策略等。
- curator-recipes:封装了一些高级特性,如:Cache 事件监听、选举、分布式锁、分布式计数器、分布式 Barrier 等
ZKClientBindings - Apache ZooKeeper - Apache Software Foundation
Curator 的官方 文档
代码案例 :
依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>

package org.zk.curator;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.cache.PathChildrenCache;
import org.apache.curator.framework.recipes.cache.PathChildrenCacheEvent;
import org.apache.curator.framework.recipes.cache.PathChildrenCacheListener;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
public class App
{
public static void main( String[] args ) throws Exception{
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.connectString("192.168.217.128:2181,192.168.217.135:2181,192.168.217.136:2181").
sessionTimeoutMs(4000)
.retryPolicy(new ExponentialBackoffRetry(1000,3))
//重试策略每个一秒重试一次 总共从试3次
//如果制定了命名空间 namespace 则所有的动作都在该链接下, 这里可以用作区分不同项目组的数据
.namespace("").build();
curatorFramework.start();
//创建监听
PathChildrenCache cache=new PathChildrenCache(curatorFramework,"/top",true);
cache.start();
cache.rebuild();
cache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework framwork, PathChildrenCacheEvent event) throws Exception {
System.err.println("节点发生变化:"+event.getType());
}
});
Stat stat = new Stat();
//查询节点数据
byte[] bytes = curatorFramework.getData().storingStatIn(stat).forPath("/hadoop");
System.out.println(new String(bytes));
System.out.println("准备创建【/top/ni】");
curatorFramework.create().withMode(CreateMode.PERSISTENT)
.forPath("/top/ni", "李小龙".getBytes());
System.out.println("节点【/top/ni】创建成功");
stat = curatorFramework.checkExists().forPath("/top/ni");
if(stat!= null){
System.out.println("【/top/ni】节点存在,直接删除");
curatorFramework.delete().forPath("/top/ni");
}
byte[] bs=curatorFramework.getData().forPath("/hadoop");
System.out.println("数据:"+new String(bs));
curatorFramework.close();
}
}
GitHub - wanglei111000/zkCurator
6.1: curator 实现zk 分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式
排他锁(Exclusive Locks),又被称为写锁或独占锁,如果事务T1对数据对象O1加上排他锁,那么整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能进行读或写
实现方式:
利用 zookeeper 的同级节点的唯一性特性,在需要获取排他锁时,所有的客户端试图通过调用 create() 接口,在 /exclusive_lock 节点下创建临时子节点 /exclusive_lock/lock,最终只有一个客户端能创建成功,那么此客户端就获得了分布式锁。同时,所有没有获取到锁的客户端可以在 /exclusive_lock 节点上注册一个子节点变更的 watcher 监听事件,以便重新争取获得锁
共享锁(Shared Locks),又称读锁。如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都释放
实现方式:
1、客户端调用 create 方法创建类似定义锁方式的临时顺序节点。
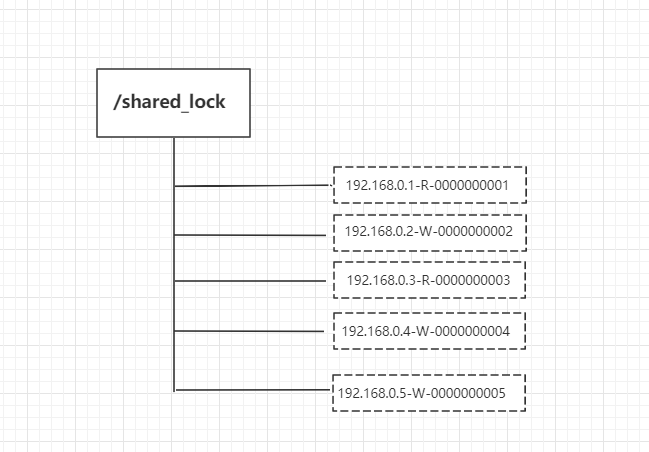
2、客户端调用 getChildren 接口来获取所有已创建的子节点列表。
3、判断是否获得锁,对于读请求如果所有比自己小的子节点都是读请求或者没有比自己序号小的子节点,表明已经成功获取共享锁,同时开始执行度逻辑。对于写请求,如果自己不是序号最小的子节点,那么就进入等待。
4、如果没有获取到共享锁,读请求向比自己序号小的最后一个写请求节点注册 watcher 监听,写请求向比自己序号小的最后一个节点注册watcher 监听。
实际开发过程中,可以 curator 工具包封装的API帮助我们实现分布式锁。
curator 的几种锁方案 :
- 1、InterProcessMutex:分布式可重入排它锁
- 2、InterProcessSemaphoreMutex:分布式排它锁
- 3、InterProcessReadWriteLock:分布式读写锁
模拟 30 个线程使用重入排它锁 InterProcessMutex 同时争抢锁:
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.dslock</groupId>
<artifactId>zk_curator_dslock</artifactId>
<version>1.0-SNAPSHOT</version>
<name>zk_curator_dslock</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
主要代码:
package org.dslock;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class App
{
public static void main( String[] args )
{
CuratorFramework zkClient = getZkClient();
String lockPath = "/lock";
InterProcessMutex lock = new InterProcessMutex(zkClient, lockPath);
//模拟50个线程抢锁
for (int i = 0; i < 15; i++) {
new Thread(new TestDsLockThread(i, lock)).start();
}
}
static class TestDsLockThread implements Runnable {
private Integer threadFlag;
private InterProcessMutex lock;
public TestDsLockThread(Integer threadFlag, InterProcessMutex lock) {
this.threadFlag = threadFlag;
this.lock = lock;
}
@Override
public void run() {
try {
lock.acquire();
System.out.println("第"+threadFlag+"线程获取到了锁");
//等到1秒后释放锁
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
private static CuratorFramework getZkClient() {
String zkServerAddress = "192.168.217.128:2181,192.168.217.135:2181,192.168.217.136:2181";
ExponentialBackoffRetry retryPolicy = new ExponentialBackoffRetry(1000, 3, 5000);
CuratorFramework zkClient = CuratorFrameworkFactory.builder()
.connectString(zkServerAddress)
.sessionTimeoutMs(5000)
.connectionTimeoutMs(5000)
.retryPolicy(retryPolicy)
.build();
zkClient.start();
return zkClient;
}
}
