
这篇文章总结了在一系列金融分析应用中,在企业中大规模开发和部署机器学习模型的经验教训。作者用反模式(反例)的形式呈现的,并且归纳了有几个有意思的词语方便记忆,比如Grade-your-own-Exam/Tuning-under-the-carpet。听说作者都是该领域的专家。由于是金融领域,有一部分的关注点是时间序列的预测,这里仅对一些有意思的观点作整理。

简单总结如下:
建模
Data Leakage 测试集信息被不小心泄露
Tuning under the carpet 对一千个参数做了优化,但没有细节
模型评价
PEST 结果符合预期于是声称模型好
Bad Credit Assignment 好的结果都归功于模型更优秀
Grade your own exam 又当运动员又当裁判
Data Leakage
Peek-a-Boo
第一眼看到这个词的时候总会有一些奇怪的联想,它其实是躲猫猫的意思。许多时间序列数据集是基于滞后的数据,比如就业市场的数据,一般都是在下个月生成。建模者可能没有意识到所用的数据其实是滞后数据,不知不觉中在模型中错误地使用了这些数据。

Temporal Leakage
当通过抽样构建训练和测试数据集时,会导致leakage,从而导致训练和测试集不是独立的。特别是在预测问题中,当训练和测试的分割不按顺序进行时,就会发生Temporal Leakage。

Oversampling Leakage
类别不平衡问题,即数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题。例如logistic回归在欺诈检测问题中,因为绝大多数样本都为正常样本,欺诈样本很少,模型会倾向于把大多数样本判定为正常样本,这样能达到很高的准确率,但显然这样的结果不是我们想要的。
上采样(过采样)和下采样(负采样)策略是解决类别不平衡问题的基本方法之一。上采样即增加少数类样本的数量,下采样即减少多数类样本以获取相对平衡的数据集。最简单的上采样方法可以直接将少数类样本复制几份后添加到样本集中,最简单的下采样则可以直接只取一定百分比的多数类样本作为训练集。
如果在把数据分割成训练集和测试集之前进行过度取样,那么就有可能出现信息泄露。

Metrics-from-Beyond
这种类型也可以被看作是预处理或超参数leakage。很多时候,由于预处理数据时的粗心大意,训练数据集和测试数据集被一起做标准化,导致测试数据的泄漏。例如,如果测试数据集和训练数据集一起归一化,那么用于测试数据的样本均值和方差就会出现leakage。还比如使用全部数据确定某个参数,也会发生leakage。
Tuning-under-the-Carpet
调参在建模中起着如此重要的作用,以至于有可能整个研究工作都是寻找有效的超参数。即使是一个简单的分类模型,比如决策树,超参数有树的最大深度、最小数量等。另一个常用的分类器SVM,需要调参来确定核的类型及损失函数。还有最近很火的深度学习,需要确定中间层的隐藏大小,在网络结构中采用的单元类型,网络结构(全连接、递归、卷积), 激活函数的类型(TanH,ReLU,Sigmoid)等。一个专门的研究领域称之为神经结构搜索,专门研究神经网络的调参问题。
例如kaggle神器xgboost调参比不调参在F1分数上提升了3.5%。
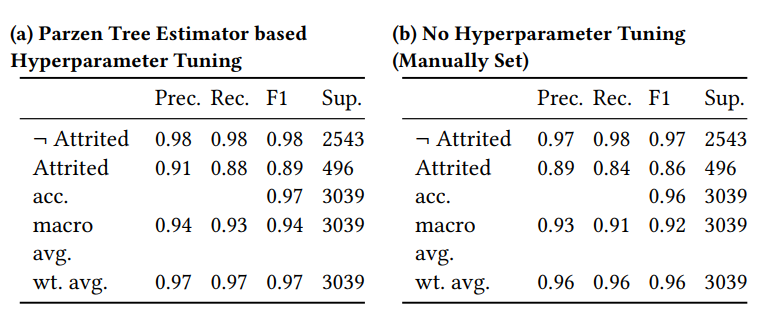
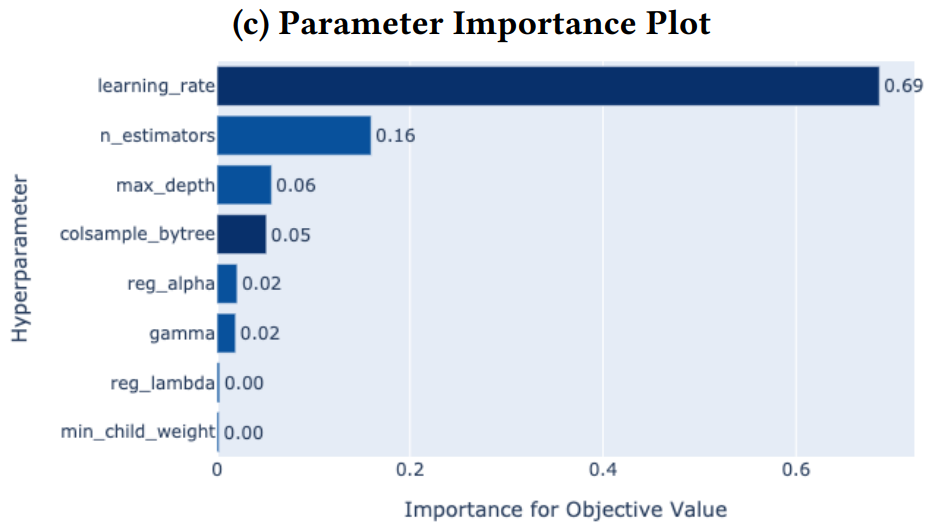
几个超参数的重要程度也不一致,因此需要详尽地记录调参的过程以提高可重复性。
PEST
应用机器学习的目的可能包括 (i) 验证以前未被验证的理论;(ii)产生新的理论;(iii)对现有理论/模型的提升。无论哪一种都需要对所提出的方法进行科学地评估,并与之前提出的方法进行对比。然而,对新方法的验证经常都不充分。所获得的验证往往都是 "感知经验优势"(Perceived Empirical SuperioriTy-PEST)。大概可理解为,不进行严格的检验,结果符合预期就认为方法上没问题。
Bad Credit Assignment
由于同行评审更鼓励技术上的创新,很多时候,研究工作的重点便是提出更好更复杂的模型结构。可是很多时候,模型表现的提高却是因为有更巧妙的问题表述(formulations),数据预处理,调参,或者将现有的成熟方法运用到新颖的领域。因此需要对新模型的每个部分的性能增益进行评估。
Grade-your-own-Exam
在实践中,模型开发者有机会接触到最终的测试集,并通过反复的测试和评估,相应地修改模型,以提高在已知检验集上的性能。这种做法被Gencoglu等人(2019)称之为HARKing(Hypothesizing After Results are Known)。解决方案除了Kaggle类似的数据建模竞赛外,作者提出的一个解决方案是:建立数据库,并通过API获取数据,并设置日期戳以确定最后测试数据获取的时间。
至于模型的部署和维护部分,了解即可。
Act Now, Reflect Never 模型没有检测系统
Set & Forget 不根据实际数据更新模型
Communicate with Ambivalence 只产生预测结果,忽略其他指标
Data Crisis as a Service 缺乏推广性好的特征工程

问:你的模型是怎么调参的
答:在地毯下面调的
