centos7上hadoop伪分布式集群配置
写在前面
云计算实验,hadoop完全式分布集群,没那么多服务器就搞了个伪分布式。
纯粹为了应付老师,教程是一边查一遍弄的,重复装了一次,整个实验的流程顺序很重要,步骤要是错了可能弄的东西一样但是结果不一样。其中遇到过很多错误,也并没有一一记录下来,只记录了改正后的内容。要是有跟着这个教程弄,代码或者配置没错的话,有报错可以先看参考链接里面有没有解决的方案,不行就百度吧。
教程里面那些路径,你把东西解压在哪装在哪就换成哪的路径就好,多试试就没问题了。
云服务器有个很重要的功能:快照,如果担心弄错又得重装,可以在安装完jdk
或者hadoop,还没到配置的时候就去控制台搞个快照,后面出了问题搞砸了也能回去恢复到刚装完软件那个状态重新来过。真是很有用的一个功能呢。
对于人的要求,会一点linux命令就可以了,不记得直接百度就好,没什么大问题。
xshell6安装指路:https://onlinedown.rbread04.cn/huajunsafe/Xshell6_onlinedown.exe
工具
- 阿里云轻量应用服务器,centos7
- xshell (windows自带的powershell也可以的)
链接ssh
ssh root@公网ip
新增用户
useradd -d /home/hadoop -m hadoop
usermod -a -G root hadoop
passwd hadoop
把用户加入sudo组
# 切换到root用户
su
# 输入密码
visudo
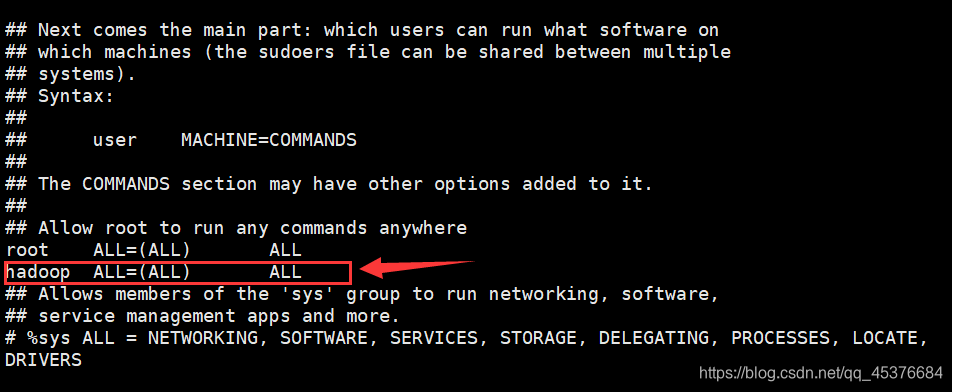
找到 root ALL=(ALL) ALL,在下面添加hadoop ALL=(ALL) ALL,保存退出
设置ssh免密登录
配置公钥和秘钥
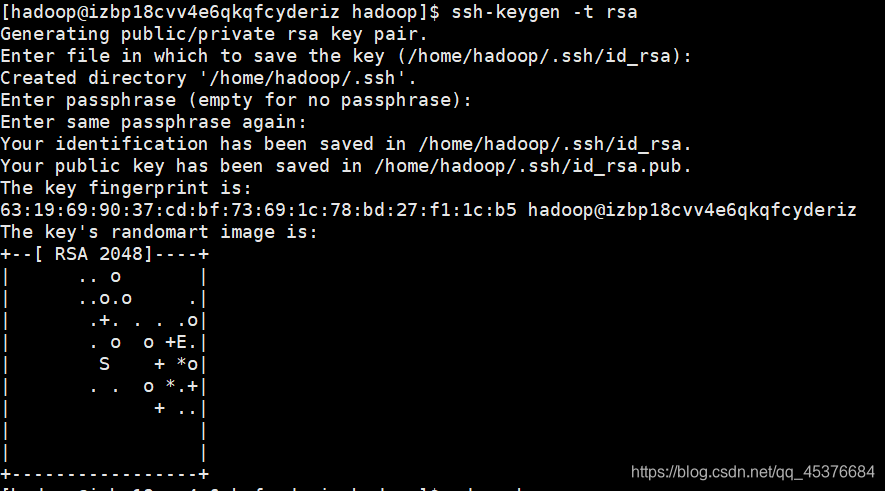
ssh-keygen -t rsa
一路enter ,配置完成后如图所示
创建authorized_keys文件,并修改权限
# .ssh文件目录与hadoop安装根目录同级
cd /home/hadoop/.ssh
touch authorized_keys
chmod 600 authorized_keys
将公钥追加到authorized_keys文件中
cat id_rsa.pub >> authorized_keys
检查是否配置成功:ssh localhost , 不用输入密码连接成功则表明免密成功
下载安装
JDK8
安装jdk
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel -y
配置java环境变量
vim /etc/profile
添加以下变量
# set java environment
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-1.el7_9.x86_64
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME CLASSPATH PATH
按esc,输入 :wq保存退出,执行以下命令使环境变量生效
source /etc/profile
检查配置是否正确且生效
java -version
$JAVA_HOME/bin/java -version
两条命令输出结果一致则表示JDK环境已正确配置
Hadoop
下载安装
cd ~
wger https://downloads.apache.org/hadoop/core/hadoop-3.2.1/hadoop-3.2.1.tar.gz
# 链接太慢下不下来,就使用本地下载上传服务器的方式,需要安装rzsz
yum install -y lrzsz
rz
# rz传输还是太慢了,用scp
scp c:\Users\Vcc\Downloads\Compressed\hadoop-3.2.1.tar.gz
# scp传不上去,再换一个
root@101.37.159.40:/home/hadoop/hadoop-3.2.1.tar.gz
解压到/home/hadoop目录下,并改名文件夹为hadoop
tar -zxvf hadoop-2.9.2.tar.gz -C /home/hadoop
mv ./hadoop-2.9.2/ ./hadoop
# 检查hadoop是否正确安装
/home/hadoop/hadoop/bin/hadoop version
若成功安装则会输出版本信息
设置hadoop环境变量
vim /etc/profile
# 添加以下内容
# set hadoop environment
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_DATANODE_USER=hadoop
export HDFS_DATANODE_SECURE_USER=hadoop
export HDFS_NAMENODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
按esc,输入:wq保存退出
使hadoop环境变量生效
source /etc/profile
修改hadoop配置文件
配置文件目录:安装目录的/etc/hadoop目录下
cd /home/hadoop/hadoop/etc/hadoop
配置hadoop-env.sh
vim hadoop-env.sh # 修改JAVA_HOME为JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-1.el7_9.x86_64

- 配置core-site.xml
vim core-site.xml
<configuration>
<!--分布式集群中主节点的地址:指定端口号-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhose:9000</value>
</property>
<!--指定hadoop进程运行中产生的数据存放的工作目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
- 配置hdfs-site.xml
vim hdfs-site.xml
<configuration>
<!--hdf的副本数,因为是伪分布式所以写1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
</configuration>
问题:hadoop/下并没有tmp目录
解决:创建目录
# /home/hadoop/hadoop/
mkdir tmp
cd tmp
mkdir namenode
mkdir datanode
- 配置mapred-site.xml
vim mapred-site.xml
<configuration>
<!--指定MapReduce程序放在yarn资源调度集群上运行-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
可能一开始目录下没有这个文件,新建保存就行
- 配置yarn-site.xml
vim yarn-site.xml
<!--指定yarn集群中主节点地址(本机)-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!--配置yarn集群中的重节点,指定map产生的中间结果传递给reduce采用的机制是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
关闭防火墙
# 查看防火墙状态
sudo firewall-cmd --state

# 若未关闭,则关闭防火墙(需要监听端口,内网,全关掉不要紧)
sudo systemctl stop firewalld.service
# 禁止防火墙开机自启
sudo systemctl disable firewalld.service
开启端口
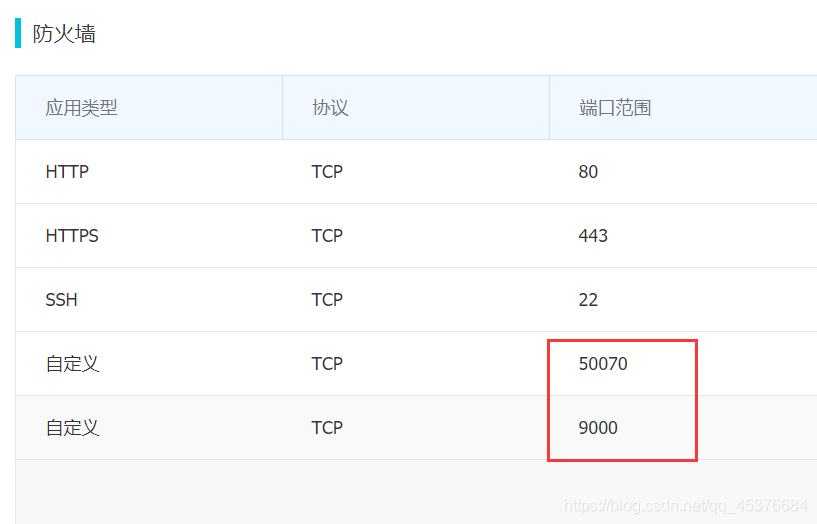
阿里云服务器控制台>>防火墙默认开启的端口只有 80, 443, 22 三个端口,需要手动开启 50070 端口
目录格式化
namenode目录格式化(只需要第一次启动时格式化)
hadoop namenode -format

启动进程
输入jps 可以查看已成功启动的进程

start-dfs.sh
start-yarn.sh
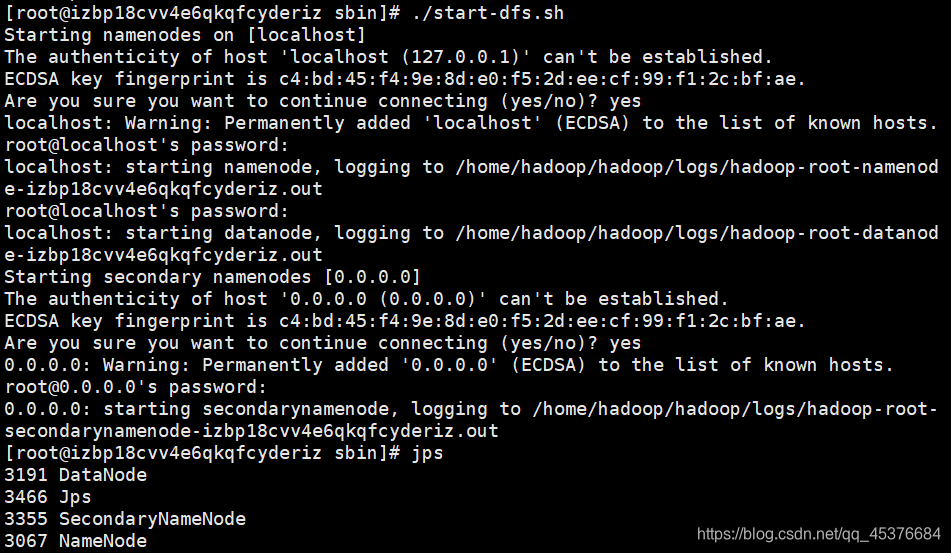
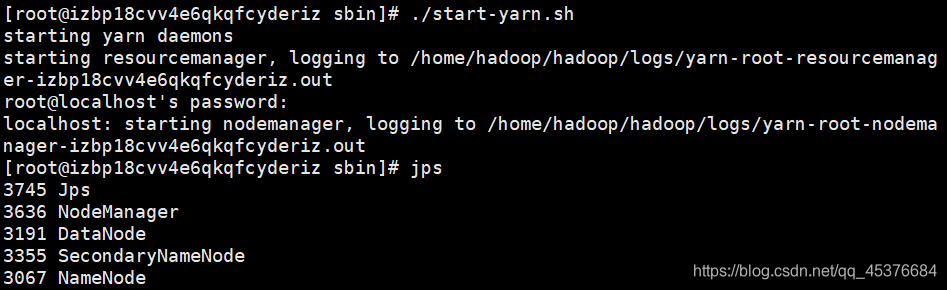
存在问题:许多教程表示输入jps输出6个进程才是成功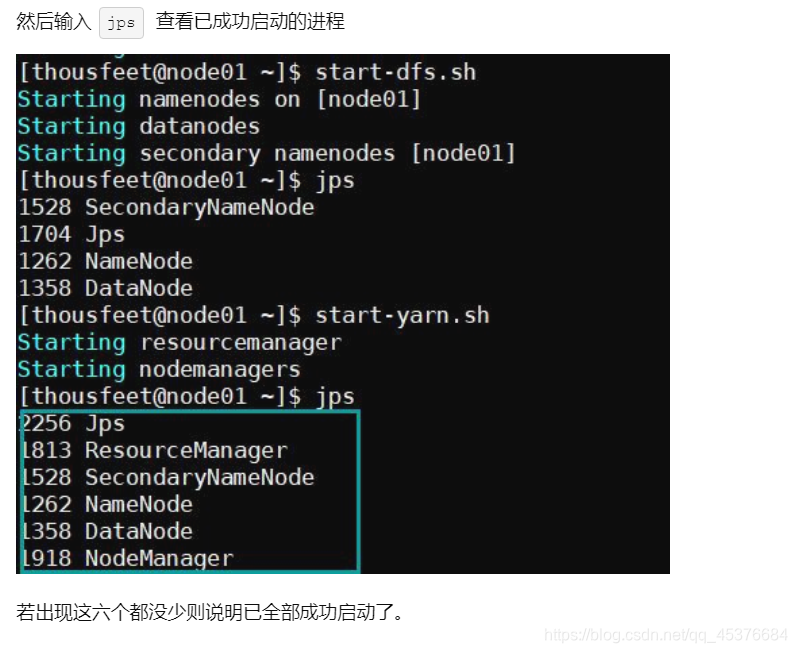
而我的没有出现ResourceManager,但问题不大,启动了就好
查看hadoop
通过webUI查看hadoop集群是否启动完全成功
在浏览器中输入 公网ip:50070 , 跳转到dfs页面
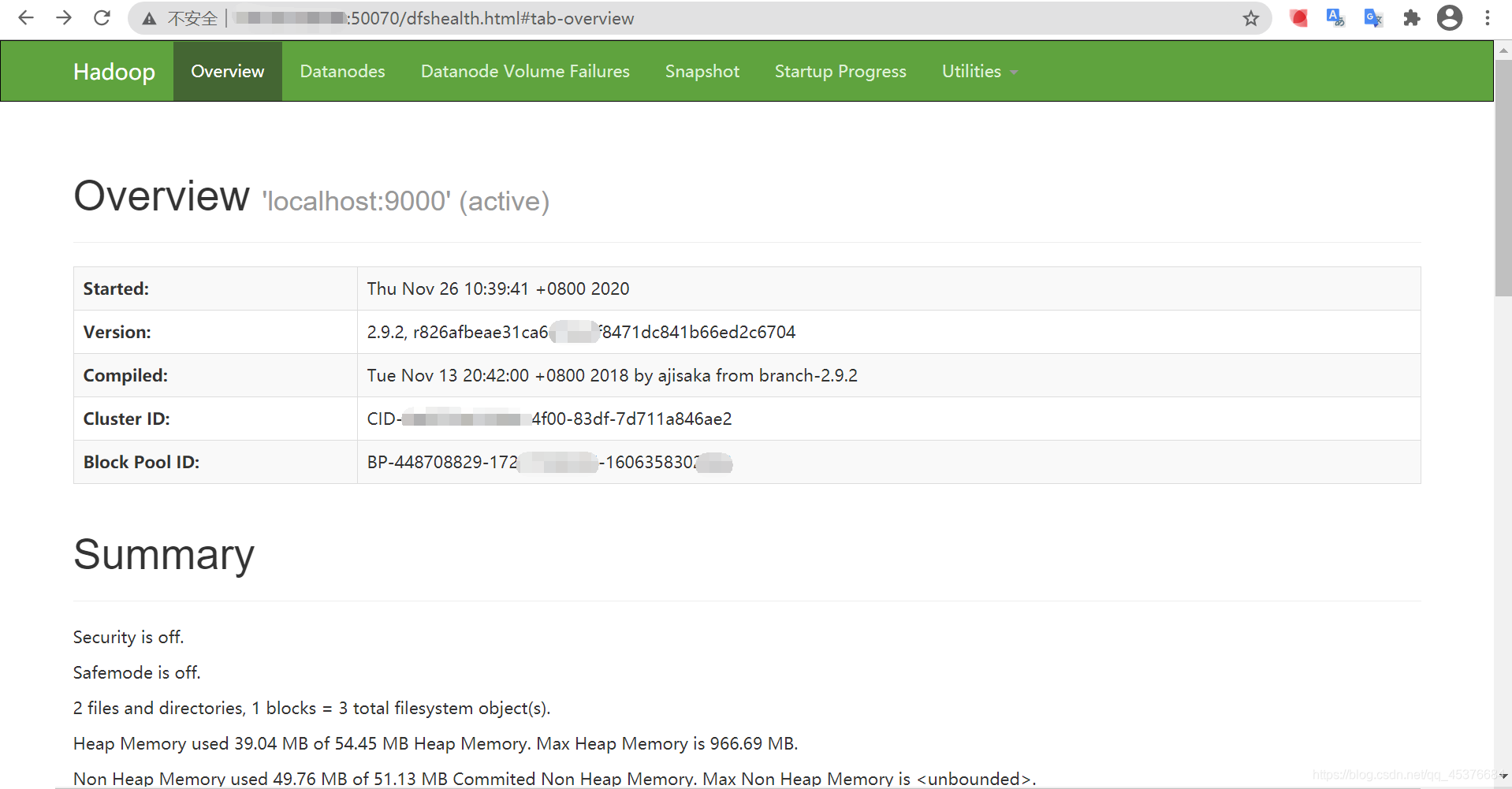
文件上传尝试

没问题,说明hadoop伪分布式集群的搭建,是成了。
参考教程
CentOS7.0安装Hadoop伪分布集群_定格我的天空的博客-CSDN博客
阿里云服务器centos7.2下搭建hadoop伪分布式环境_feng_zhiyu的博客-CSDN博客_阿里云服务器搭建hadoop环境
阿里云服务器centos7.3下搭建hadoop伪分布式环境 - StarZhai - 博客园 (cnblogs.com)
阿里云体验实验室 教你如何《搭建Hadoop环境》 - 知乎 (zhihu.com)
阿里云(轻量级Ubuntu 16.04 )服务器搭建Hadoop伪分布式集群及实现pi值的计算_MuuuuYi的博客-CSDN博客