由于工作的需要,最近对一些常见的评价指标重新温习了一下,其中对混淆矩阵、准确率、精确率、召回率、真正率、假正率、ROC/AUC、PRC等概念进行了重点的温习和理解,并结合自己的感悟,总结和梳理了一下。
首先说明一下,以上指标主要针对分类问题的,其中的根源和核心是二分类混淆矩阵。
1.混淆矩阵
下面展开说明都是以二分类混淆矩阵为基础,多分类可以将除目标类之外的其他类别当成一类(反例)。
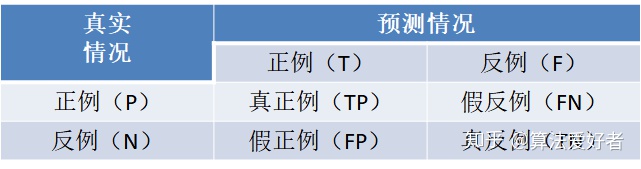
二分类混淆矩阵由2个维度组成,从样本原本的属性类别以及从预测结果类别。即预测是现象,原本属性是根本,预测越接近原本属性,模型越好,下面要介绍的指标都是从不同的维度/视角来刻画预测逼近原本属性的程度。
2.准确率
准确率是我们使用最常见的指标,是一个关于全局的指标,关注的是预测的效果。具体公式如下:
通常我们都会直接使用准确率作为模型的评价指标,但是在实际使用以及一些特定环境中,准确率作为模型的评价指标存在一定的局限性,比如当样本分布不均时,一种极端特殊的情况,当正样本比例为1%,负样本笔记为99%,那么只需要将所有的样本都判为负样本,准确率就高达99%,这显然是不合理的。因此为了更好的去评估模型,便有了下面就的评价指标。
3.精准率
精准率,又称查准率,关注的正样本,这符合实际的诉求,并且关注的是预测的效果,指在预测为正例中有多少为真正的正例,反应模型预估的精准程度,具体公式如下:
4.召回率
召回率,又称查全率,关注的是正样本,并且关注的是样本的原本属性,指的是数据集中的正样本有多少被识别出来,具体的公式如下:
从召回率字面的角度也很好理解,在实际问题中的关注的永远都是正样本,召回的目标肯定就是正样本,在目标正样本中有多少正样本被真正的召回识别。
5.真正率(真阳率)
真正率,True Positive Rate ,其实指上文介绍的召回率。
6.假正率(假阳率)
假正率,False Positive Rate,指的是原本为负样本中有多少被预测为正样本,关注的还是正样本,只不过从负样本的维度来观察,具体的公式为:
这里稍微总结一下真正率和假正率,两者关注的(目标)都是正样本,这符合实际问题的诉求,只不过两者关注的角度不同,真正率是从正样本的角度来看预测之后正样本,假正率是从负样本的角度来看预测之后的正样本。两者分开来看并最终综合起来,就能比较全面和合理评估预测模型。
7.ROC
ROC,Receiver Operating Characteristic,受试者工作特征曲线,是以假正率为横坐标,真正率为纵坐标,关注的是预测之后的正样本,并且从正负两个样本集合角度分析。在坐标系中的图形如下所示:
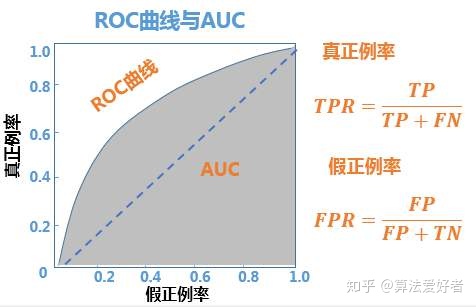
当确定一个阈值,对应这ROC曲线上的一个点,原点对应的模型设置的阈值为1,点(1,1)对应的模型设置的阈值为0,理想情况下,随着阈值设置的变小,ROC曲线的轨迹为先经过FPR=0这条直线而后经过TPR=1这条直线。下面来详细分析这条直线。
当系统阈值设置为1时,所有的样本都会被判为负样本,即TP/FP都为0,即为原点,随着阈值设置的变小,由于阈值总体还是比较大的,负样本都判为负样本,即FP为0,假正率为0,正样本慢慢更多的被判为正样本,即真正率慢慢变大,当假正率为0时,FP=0,负样本都预测为负样本,真正率为1时,FN=0,正样本都预测为正样本,表示一种理想状态,所有的样本都预测正确,同时也表名在概率预测高值部分,不同样本的预测概率值排序正确。当阈值进一步减小时,会经过FPR=1曲线,此时由于阈值相对较小,正例都预测为正例,负例慢慢被预测为正例,FP不再为了,并且会慢慢增大,当阈值为0时,所有的样本都会预测为正例,即FN/TN=0,没有样本预测为负例。
对交线对应者随机猜测的性能,也即是不经过模型预测,随着阈值的变化随机猜测之后的结果,这也ROC曲线对应的最差的结果。
8.AUC
AUC,Area Under Curve,曲线下面积,[0.5,1]之间,是基于ROC衍生的非常好的可量化的评价标准,ROC曲线是越陡约好,即AUC越大越好,理想情况下,面积为1。
AUC物理意义解读:正常分类模型只会设置一个阈值,即不存在面积的说法,ROC考虑所有的分类阈值的情况,可以解读为正样本排在负样本之前的概率。
ROC/AUC使用解读:
- ROC/AUC能够反应模型在一个数据集上的排序的准确程度;
- 同时考虑了模型对正例和负例的分类能力,在样本分布不均的情况下依然对模型做出合理的评估。
9.PRC
P-R曲线,Precision-Recall Curve,是以召回率为横坐标,以精准率为纵坐标,不同的阈值对应不同的P-R曲线上的点,P-R图像如下:
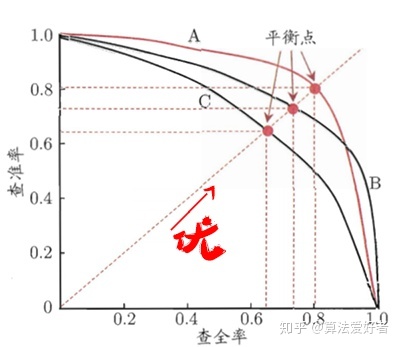
评价标准为一个曲线A将另一个曲线C完全包住,代表曲线A对应的分类模型效果更好,若曲线A并没有完全包住曲线B,则找两个曲线的平衡点(查全率=查准率),看谁大谁对应的模型好。