前言
这两事务日志用来保证事务原子性、持久性的,undo log(回滚日志)提供回滚操作,保证原子性,redo log(重做日志)提供前滚操作,保证持久性。
先聊聊undo log
什么时候会用到undo log回滚?
- 用户调用ROLLBACK主动回滚
- 事务出错
- 辅助redo log实现事务持久性
undo log如何保证原子性?
数据修改前,undo log会备份保存修改前的数据记录,然后把undo log写磁盘,数据修改并写磁盘,然后事务提交。如下有A=1、B=2两数据
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录B=2到undo log.
E.修改B=4.
F.将undo log写到磁盘。
G.将数据写到磁盘。
H.事务提交
所谓的原子性是事务中系列操作要么都执行成功,要么都失败回滚。看上面这个过程,如果G、H间系统出现故障,根据磁盘中undo log回滚到原始状态;如果A-F间出现故障 ,因为数据还没有更新持久化到磁盘,自然是原始状态。(这里面也有隐含的持久性意思)
缺点?
数据和undo log都会写磁盘,无疑增加了磁盘I/O次数,降低了性能。
再聊聊redo log
上文的undo log隐含中有实现持久性的意思,但是就是因为增加了大量磁盘I/O会降低性能,所以引入了redo log。redo log记录数据修改后新数据的备份、冗杂的undo log、未提交的事务和回滚的事务,数据缓存到内存中,只是在事务提交前将redo log持久化到磁盘
如何使用undo log+redo log来保证持久性?
所谓持久化,即事务一旦提交,那么数据一定会被写入到数据库中并持久存储起来,事务也无法回滚
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录A=3到redo log.
E.记录B=2到undo log.
F.修改B=4.
G.记录B=4到redo log.
H.将redo log写入磁盘。
I.事务提交
记录undo日志,修改数据,记录redo log,持久化redo log,事务提交。
redo log先于数据持久化,数据不会在事务提交前写磁盘而是缓存起来。
如果发生错误,数据库系统在重启时会加载redo log找出未被更新到数据库磁盘中的日志重新执行以满足事务的持久性(即对所有已提交的事务重做)
缺点?
虽然免去了数据写磁盘的IO,但是又增加了redo log的磁盘开销。
InnoDB为了解决redo log磁盘开销的问题提出了以下几点:
- 尽量保证redo log存储在连续的一段磁盘空间上,顺序的追加方式记录redo log
- redo log分为两部分——redo log缓冲区和磁盘上的redo log文件,所以redo log并不是直接写入文件,而是先写入redo log buffer。当需要将日志刷新到磁盘时(如事务提交),将许多日志一起写入磁盘

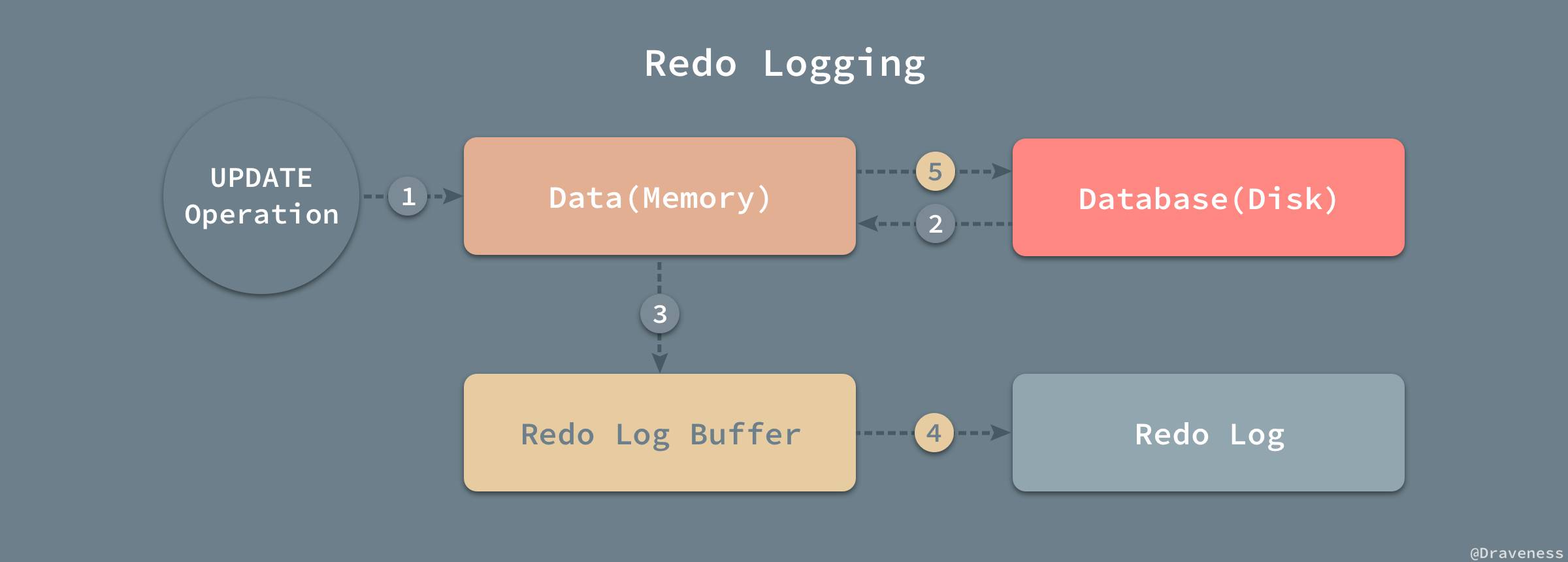
如图,根据update操作从磁盘上数据库中读取数据到内存,写如redo日志缓存,批量写到redo log文件,事务提交,数据写回数据库持久化保存。图片引自:https://img.draveness.me/2019-02-21-Redo-Logging.jpg
{kind=link}
- Redo Log上只进行顺序追加的操作,当一个事务需要回滚时,它的Redo Log记录也不会从Redo Log中删除掉
- 并发的事务共享Redo Log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起,以减少日志占用的空间
如何利用undo log和redo log异常恢复?
今天看到说是有两种策略,之前以为就一种。因为redo log会保存未提交的事务和回滚的事务,所以有:
- 策略一:根据redo log只重做已提交的事务
- 策略二:根据redo log重做包含未提交和回滚在内的事务,再根据undo log回滚那些未提交的事务
- InnoDB采用这种策略
- 该策略必须将undo log优先于redo log持久化到磁盘,但InnoDB为了降低复杂度把undo log看作数据写入记录在redo log中缓存起来,就免去了undo log的磁盘IO
而且不管数据库上次是正常关闭还是异常关闭,总是会进行恢复操作
参考文章
还有几篇文章可以看看
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lzw2016/article/details/89420391