机器学习—SVM分类
机器学习—SVM分类
一 SVM简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;它分类的思想是,给定给一个包含正例和反例的样本集合,SVM的目的是寻找一个超平面来对样本根据正例和反例进行分割。各种资料对它评价甚高,说“它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中”;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的学习算法就是求解凸二次规划的最优化算法。
关于SVM学习,推荐两本书:统计学习方法(李航)和机器学习实战,二者结合,可以帮助我们理解SVM算法。
二 SVM应用
(1)线性支持向量机

求解线性支持向量机的过程是凸二次规划问题,所谓凸二次规划问题,就是目标函数是凸的二次可微函数,约束函数为仿射函数(满足f(x)=a*x+b,a,x均为n为向量)。而我们说求解凸二次规划问题可以利用对偶算法--即引入拉格朗日算子,利用拉格朗日对偶性将原始问题的最优解问题转化为拉格朗日对偶问题,这样就将求w*,b的原始问题的极小问题转化为求alpha*(alpha>=0)的对偶问题的极大问题,即求出alpha*,在通过KKT条件求出对应的参数w*,b,从而找到这样的间隔最大化超平面,进而利用该平面完成样本分类
(2)近似线性支持向量机
当数据集并不是严格线性可分时,即满足绝不部分样本点是线性可分,存在极少部分异常点;这里也就是说存在部分样本不能满足约束条件,此时我们可以引入松弛因子,这样这些样本点到超平面的函数距离加上松弛因子,就能保证被超平面分隔开来;当然,添加了松弛因子sigma,我们也会添加对应的代价项,使得alpha满足0=
(3)非线性支持向量机
显然,当数据集不是线性可分的,即我们不能通过前面的线性模型来对数据集进行分类。此时,我们必须想办法将这些样本特征符合线性模型,才能通过线性模型对这些样本进行分类。这就要用到核函数,核函数的功能就是将低维的特征空间映射到高维的特征空间,而在高维的特征空间中,这些样本进过转化后,变成了线性可分的情况,这样,在高维空间中,我们就能够利用线性模型来解决数据集分类问题
如果想要透彻理解SVM建议还是要看看上面的书和博客文章,篇幅有限,我这里的中心在于凸二次规划的优化算法--SMO(序列最小最优化算法)
(4)SMO算法
SMO是一种用于训练SVM的强大算法,它将大的优化问题分解为多个小的优化问题来进行求解。而这些小优化问题往往很容易求解,并且对它们进行顺序求解和对整体求解结果是一致的。在结果一致的情况下,显然SMO算法的求解时间要短很多,这样当数据集容量很大时,SMO就是一致十分高效的算法
SMO算法的目标是找到一系列alpha和b,而求出这些alpha,我们就能求出权重w,这样就能得到分隔超平面,从而完成分类任务
SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到一对合适的alpha,那么就增大其中一个而减少另外一个。这里的"合适",意味着在选择alpha对时必须满足一定的条件,条件之一是这两个alpha不满足最优化问题的kkt条件,另外一个条件是这两个alpha还没有进行区间化处理
(5)SVM多类分类
SVM本身是一种典型的二分类器,那如何处理现实中的多分类问题呢?
常用的有三种方法:
一对多
也就是“一对其余”(One-against-All) 的方式,就是每次仍然解一个两类分类的问题。这样对于n个样本会得到n个分类器。但是这种方式可能会出现分类重叠现象或者不可分类现象而且由于“其余”的数据集过大,这样其实就人为造成了“数据偏斜”的问题
一对一
每次选择一个类作为正样本,负样本只用选其余的一个类,这样就避免了数据偏斜的问题。很明显可以看出这种方法训练出的分类个数是k*(k-1)/2,虽然分类器的个数比上面多了,但是训练阶段所用的总时间却比“一类对其余”方法少很多。这种方法可能使多个分类器指向同一个类别,所以可以采用“投票”的方式确定哪个类别:哪个分类器获得的票数多就是哪个分类器。这种方式也会有分类重叠的现象,但是不会有不可分类的情况,因为不可能所有类别的票数都是0。但是也很容易发现这种方法是分类器的数目呈平方级上升。
DAG-SVM
假设有1、2、3、4、5五个类,那么可以按照如下方式训练分类器(这是一个有向无环图,因此这种方法也叫做DAG-SVM)这种方式减少了分类器的数量,分类速度飞快,而且也没有分类重叠和不可分类现象。但是假如一开始的分类器回答错误,那么后面的分类器没有办法纠正,错误会一直向下累积。为了减少这种错误累积,根节点的选取至关重要。
三 建模步骤
使用SVM的一般步骤为:
(1)读取数据,将原始数据转化为SVM算法软件或包所能识别的数据格式;
(2)将数据标准化;(防止样本中不同特征数值大小相差较大影响分类器性能)
(3)选择核函数,在不清楚何种核函数最佳时,推荐尝试RBF
(4)利用交叉验证网格搜索寻找最优参数(C, γ);(交叉验证防止过拟合,再利用网格搜索在指定范围内寻找最优参数)
(5)使用最优参数来训练模型;
(6)测试得到的分类器。
四 推导
关于支持向量机的推导,无论是书上还是很多很优秀的博客都写的非常清楚,大家有兴趣可以看上面推荐的统计与学习方法书,写的浅显易懂,或者看这几篇博客
http://blog.csdn.net/app_12062011/article/details/50536369
http://blog.csdn.net/zouxy09/article/details/16955347
http://blog.csdn.net/zouxy09/article/details/17291543
http://blog.csdn.net/zouxy09/article/details/17291805
http://blog.csdn.net/zouxy09/article/details/17292011
五 代码
Python版本(鸢尾花分类)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
iris = datasets.load_iris()
# 为简单起见,选取前两个特征作为分类的输入特征,以便在二维空间画出决策曲线
X = iris.data[:, :2]
y = iris.target
#设置分类器为LinearSVC,penalty指惩罚项,C为松弛变量,利用fit函数拟合输入数据,得到所需的分类器利用LinearSVC分类
svc = svm.LinearSVC(penalty='l2', C=0.5).fit(X, y)
#使用SVC实现线性分类,运行结果如下所示。
#svc=svm.SVC(kernel='linear',C=1,gamma='auto').fit(X, y)
# 设置分类器SVC,核函数为rbf,gamma设置为自动调整
#svc=svm.SVC(kernel="rbf",C=1,gamma="auto").fit(X, y)
# 绘图参数
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min) / 100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1)
# 利用已有分类器进行预测
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制等高线并填充轮廓
plt.contourf(xx,yy,Z,cmap=plt.cm.Paired,alpha=0.8)
plt.scatter(X[:,0],X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
# 限制x的取值范围,便于显示
plt.xlim(xx.min(), xx.max())
plt.title('LinearSVC test result')
plt.show()
使用sklearn中的高斯核函数RBF核
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
x,y=datasets.make_moons(n_samples=1000,noise=0.25, random_state=2020) # 生成1000个数据样本
plt.figure()
plt.scatter(x[y == 0, 0], x[y == 0, 1], color="r")
plt.scatter(x[y == 1, 0], x[y == 1, 1], color="g")
plt.show()
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=2020)
# 绘制边界曲线
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1) )
x_new = np.c_[x0.ravel(), x1.ravel()]
y_pre = model.predict(x_new)
zz = y_pre.reshape(x0.shape)
# 设置颜色
cus = ListedColormap(["#BA55D3", "#FF69B4", "#FFE4C4"])
plt.contourf(x0, x1, zz, cmap=cus)
def RBFkernelSVC(gamma):
return Pipeline([ ("std", StandardScaler()),
("svc", SVC(kernel="rbf", gamma=gamma))
])
sv = RBFkernelSVC(gamma=1)
sv.fit(x_train, y_train)
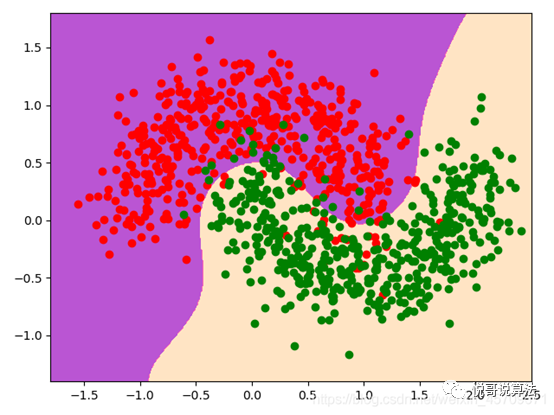
plot_decision_boundary(sv, axis=([-1.8, 2.5, -1.4, 1.8]))
plt.scatter(x[y == 0, 0], x[y == 0, 1], color="r")
plt.scatter(x[y == 1, 0], x[y == 1, 1], color="g")
plt.show()
# 打印出分数
print(sv.score(x_test, y_test))
d = datasets.load_iris()
x = d.data
y = d.target
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=2020)
sv = RBFkernelSVC(gamma=10)
sv.fit(x_train, y_train)
# 打印出分数
print(sv.score(x_test, y_test))
matlab版本
%% I. 清空环境变量
clear all
clc
%% II. 导入数据
load BreastTissue_data.mat
%%
% 1. 随机产生训练集和测试集
n = randperm(size(matrix,1));
%%
% 2. 训练集——80个样本
train_matrix = matrix(n(1:80),:);
train_label = label(n(1:80),:);
%%
% 3. 测试集——26个样本
test_matrix = matrix(n(81:end),:);
test_label = label(n(81:end),:);
%% III. 数据归一化
[Train_matrix,PS] = mapminmax(train_matrix');
Train_matrix = Train_matrix';
Test_matrix = mapminmax('apply',test_matrix',PS);
Test_matrix = Test_matrix';
%% IV. SVM创建/训练(RBF核函数)
%%
% 1. 寻找最佳c/g参数——交叉验证方法
[c,g] = meshgrid(-10:0.2:10,-10:0.2:10);
[m,n] = size(c);
cg = zeros(m,n);
eps = 10^(-4);
v = 5;
bestc = 1;
bestg = 0.1;
bestacc = 0;
for i = 1:m
for j = 1:n
cmd = ['-v ',num2str(v),' -t 2',' -c ',num2str(2^c(i,j)),' -g ',num2str(2^g(i,j))];
cg(i,j) = svmtrain(train_label,Train_matrix,cmd);
if cg(i,j) > bestacc
bestacc = cg(i,j);
bestc = 2^c(i,j);
bestg = 2^g(i,j);
end
if abs( cg(i,j)-bestacc )<=eps && bestc > 2^c(i,j)
bestacc = cg(i,j);
bestc = 2^c(i,j);
bestg = 2^g(i,j);
end
end
end
cmd = [' -t 2',' -c ',num2str(bestc),' -g ',num2str(bestg)];
%%
% 2. 创建/训练SVM模型
model = svmtrain(train_label,Train_matrix,cmd);
%% V. SVM仿真测试
[predict_label_1,accuracy_1] = svmpredict(train_label,Train_matrix,model);
[predict_label_2,accuracy_2] = svmpredict(test_label,Test_matrix,model);
result_1 = [train_label predict_label_1];
result_2 = [test_label predict_label_2];
%% VI. 绘图
figure
plot(1:length(test_label),test_label,'r-*')
hold on
plot(1:length(test_label),predict_label_2,'b:o')
grid on
legend('真实类别','预测类别')
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'测试集SVM预测结果对比(RBF核函数)';
['accuracy = ' num2str(accuracy_2(1)) '%']};
title(string)
文字 | 原创
图片 | 可商用

一个分享AI学习的公众号
动动小手,长按订阅,一起学习,一起交流