“历史遗留”的学习记录
Cifar10数据集—tensorflow2—VGG16网络—tensorboard可视化查看
(PS:时隔久远,但还是能运行)
- 子程序包括:数据集加载处理、VGG16网络搭建、变学习率训练
- 对数据集进行VGG16模型训练
- 保存运行日志在文件夹中
- 可设置数据增强
import tensorflow as tf
import numpy as np
import pickle as p
from tensorflow.keras import datasets, layers, Sequential, metrics
import datetime
from matplotlib import pyplot as plt
import io
import os
from tensorflow.keras import models, optimizers, regularizers
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
from tensorflow import keras
# os.environ['CUDA_VISIBLE_DEVICES'] = '0'
weight_decay = 5e-4
batch_size = 128
learning_rate = 1e-2
dropout_rate = 0.5
epoch_num = 10
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb')as f:
datadict = p.load(f, encoding='iso-8859-1')
X = datadict['data']
Y = datadict['labels']
X = X.reshape(10000, 3, 32, 32)
Y = np.array(Y)
return X, Y
def load_CIFAR(Foldername):
train_data = np.zeros([50000, 32, 32, 3], dtype=np.float32)
train_label = np.zeros([50000, 10], dtype=np.float32)
test_data = np.zeros([10000, 32, 32, 3], dtype=np.float32)
test_label = np.zeros([10000, 10], dtype=np.float32)
for sample in range(5):
X, Y = load_CIFAR_batch(Foldername + "/data_batch_" + str(sample + 1))
for i in range(3):
train_data[10000 * sample:10000 * (sample + 1), :, :, i] = X[:, i, :, :]
for i in range(10000):
train_label[i + 10000 * sample][Y[i]] = 1
X, Y = load_CIFAR_batch(Foldername + "/test_batch")
for i in range(3):
test_data[:, :, :, i] = X[:, i, :, :]
for i in range(10000):
test_label[i][Y[i]] = 1
return train_data, train_label, test_data, test_label
def VGG16(): #13个卷积层和3个全连接层
model = models.Sequential()
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3),
kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same', kernel_regularizer=regularizers.l2(weight_decay)))
model.add(Flatten()) # 2*2*512
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def scheduler(epoch):
if epoch < epoch_num * 0.4:
return learning_rate
if epoch < epoch_num * 0.8:
return learning_rate * 0.1
return learning_rate * 0.01
if __name__ == '__main__':
# load data
train_images, train_labels, test_images, test_labels = load_CIFAR('C:/Users/Administrator/.keras/datasets/cifar-10-batches-py')
print('train_images.shape', train_images.shape) # (50000, 32, 32, 3)
print('train_labels.shape', train_labels.shape) # (50000, 10)
print('test_images.shape', test_images.shape) # (10000, 32, 32, 3)
print('test_labels.shape', test_labels.shape) # (10000, 10)
# get model
model = VGG16()
# show
model.summary()
# train
sgd = optimizers.SGD(lr=learning_rate, momentum=0.9, nesterov=True)
change_lr = LearningRateScheduler(scheduler)
# Tensorboard
import time
from tensorflow.keras.callbacks import TensorBoard
# 获取当前时间,用于生成文件夹名以及路径,最后一句是实现保存日志这个动作
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S") # strftime() 用来格式化datetime 对象
log_dir = 'cifar_logs/' + current_time
summary_writer = tf.summary.create_file_writer(log_dir) # 创建并返回一个 SummaryWriter对象,
# 生成的日志将储存到logdir指定的路径中
# 从训练集中拿出图像集x,再取图像集中的第一张图像用来显示
sample_img = train_images[8]
sample_img = tf.reshape(sample_img, [1, 32, 32, 3]) # [batch_size,height, width, channels]
with summary_writer.as_default():
tf.summary.image("Training sample:", sample_img, step=0)
# model.save('Cifar10_model.h5')
#
data_augmentation = False # False
if not data_augmentation:
print('Not using data augmentation')
# 不进行数据扩充
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.fit(train_images, train_labels,
batch_size=batch_size,
epochs=epoch_num,
callbacks=[change_lr],
validation_data=(test_images, test_labels))
else:
print('Using real-time data augmentation') # 实时数据增强
## tensorflow2.0 数据增强
train_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255,
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=False,
fill_mode='nearest')
train_datagen.fit(train_images)
# 测试集不需要进行数据处理
test_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255) # 不增强验证数据
# test_datagen.fit(test_images)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
t = model.fit(train_datagen.flow(train_images, train_labels, batch_size=25), # flows是实时
steps_per_epoch=train_images.shape[0] // batch_size, # steps_per_epoch: 每个epoch所需的steps,不能少
epochs=200, #200原来是,10epoch精确度只有0.1,但第二次测试又有达到0.95了
callbacks=[change_lr],
validation_data=test_datagen.flow(test_images, test_labels, batch_size=128),
# validation_data = (test_images, test_labels),
validation_steps=test_images.shape[0] // batch_size, # 这个也是不能少
# callbacks=[tensorboard]
)
epochs = 3
tl = t.history['loss']
print("train_loss:", tl[1])
for i in epochs:
step = i*100
with summary_writer.as_default():
tf.summary.scalar('train-loss', float(tl[i]), step=step) # summary.scalar(tags,values)
#%%
model.save('Cifar10_model.h5')
Step1. 配置好环境后运行程序
Step2. cmd窗口切换路径至cifar_logs文件夹根目录处,输入tensorboard --logdir=./cifar_logs
**Step3. 打开浏览器,地址栏输入:[http://localhost:6006/]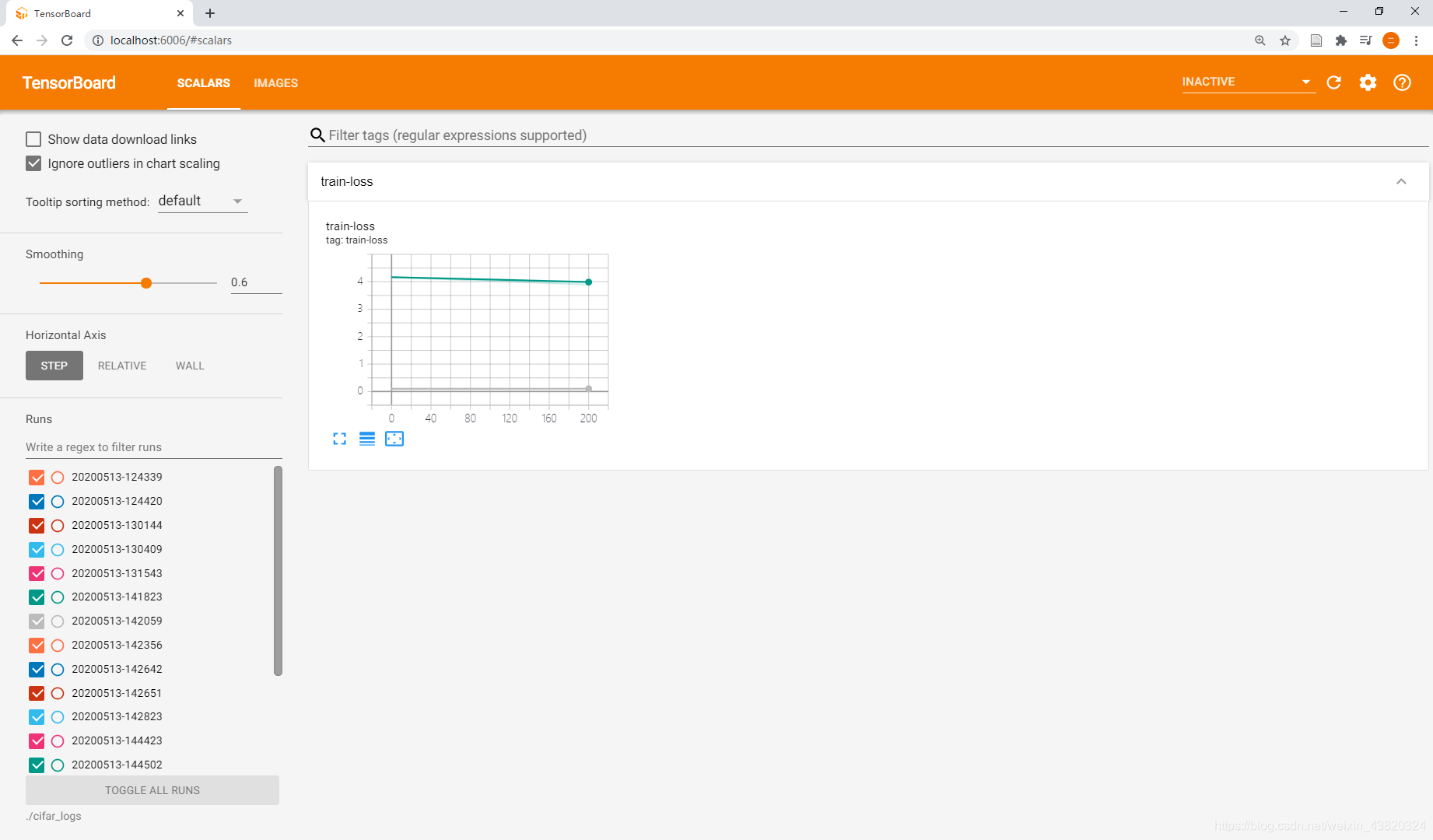
PS:碰到相应的问题学会百度
版权声明:本文为weixin_43820324原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。