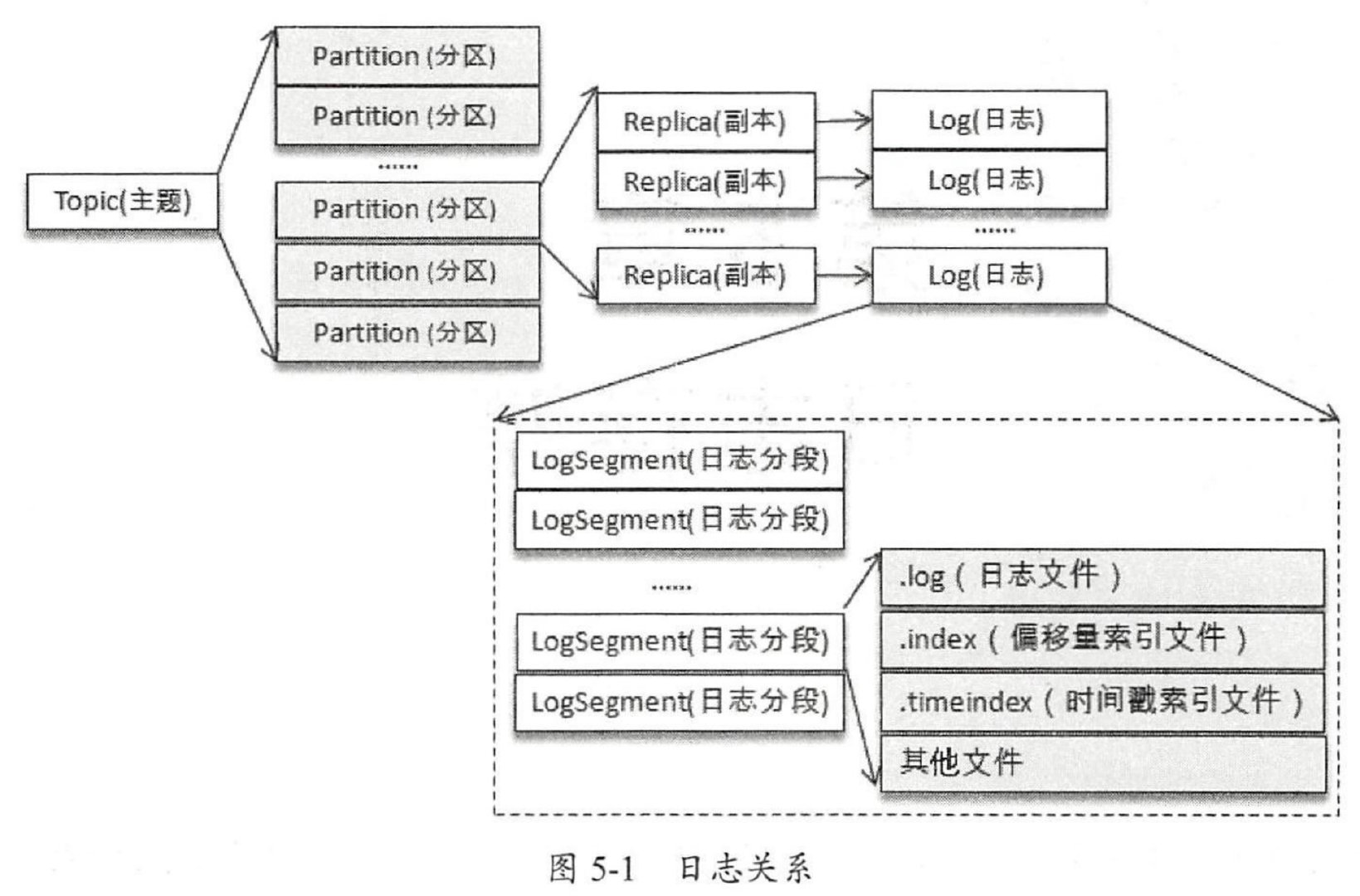
文件目录布局
日志格式演变
Kafka消息格式经过了3个版本的变化。
v0版本

v1版本

新增了一个timestamp字段。
启用压缩时,多个KV被压缩在value位置:
v2版本

v2版本使用RecordBatch代替了Message Set,引入可变长整数Varint、ZigZag编码。
日志索引
Kafka日志索引分为两种:
- 偏移量索引
- 时间戳索引
Kafka的索引是以稀疏索引构建的,因为Kafka的日志排列都是有序的(offset有序、时间戳有序),所以可以使用这种索引方式,在空间与时间之间的一种权衡方式。
稀疏索引通过MappedByteBuffer将索引文件映射到内存中,加快文件的访问。
偏移量索引

偏移量索引使用<offset, position>进行定位。
- 通过跳跃表通过偏移量找到对应的索引文件;
- 再通过二分查找找到对应的
offset,若没有找到对应的offset,则返回对应的不大于该offset的索引对应的position; - 再到具体的日志文件中,从对应的物理偏移量
position开始,进行查找定位。
时间戳索引

时间戳索引则使用<timestamp, relativeOffset>的方式。
通过将每个时间戳索引文件中的最大时间戳与当前要查找的时间戳进行比对,直到找到比当前时间戳大的时间戳索引文件;
通过二分查找查处对应的小于等于当前时间戳
<=的relativeOffset;再到同名的偏移量索引文件中,进行查找到对应的
position,再到日志文件中找到不大于当前时间戳的日志消息。
日志清理
Kafka将日志存储在磁盘中,为了应对磁盘占用空间越来越多的问题,就要对日志文件进行清理,Kafka中分为两种方式:
- 日志删除
- 日志压缩
日志删除
在Kafka的日志管理器中,有一个专门的日志删除任务来周期性地检测和删除不符合条件的日志分段文件。
当前日志分段的保留策略有三种:
- 基于时间的保留策略
- 找到最后一条数据的时间戳,进行相关时间区间日志的保留;
- 若所有的日志分段都过期,会先切分出一个
activeSegment来保证新的数据能够被写入,再进行删除; - 删除日志时,首先从Log对象维护的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作,将需要删除的日志分段及其索引文件添加上
.deleted后缀,后由一个延迟任务进行删除。
- 基于日志大小的保留策略
- 日志删除任务会检查当前日志的大小是否超过设定的阈值来寻找可以删除的日志分段集合;
- 后面的步骤与上面的基本一致。
- 基于日志的起始偏移量的保留策略
- 检查某一个日志分段的下一个日志分段的起始偏移量
baseOffset是否小于等于logStartOffset,满足条件则加入deletebleSegments; - 收集完,则可以使用与上述步骤一致的方式进行删除。
- 检查某一个日志分段的下一个日志分段的起始偏移量
日志压缩(Log Compaction)

这里的日志压缩(compact)不同于日志压缩(compress),是Kafka提供的一种对过期数据整理的策略,会保持Kafka中同一个Key的数据只保持最新的版本。
在Log Compaction执行前后,每条日志的偏移量保持不变,生成新的日志文件,日志的物理地址会重新进行组织,且日志的偏移量不再连续。
这两种策略可以类比Redis中的AOF与RDB,若一个系统使用Kafka进行系统状态的记录(Key固定,Value变化),若系统需要恢复状态,使用日志删除(类似AOF),则需要把最新的数据读取出来,当状态量变化较多次的情况,数据量仍然巨大;那如果使用日志压缩(类似RDB)的方式,则一读到对应的Key则就是最新的状态。
在每个日志目录下都有一个文件cleaner-offset-checkpoint,这个文件是用来记录每个主题每个分区已经清理的偏移量。通过这个偏移量可以分成两个部分,一个已经清理过的clean部分,和一个未清理过的dirty部分。在日志清理过程中,客户端也可以读取文件,clean部分是断续的,dirty部分是连续的(基于每个分区进行清理,offset在topic中不保证有序,分区有序)。

activeSegment不会参与Log Compaction的执行,默认情况下 firstUncleanableOffset 等于 activeSegment的baseOffset。
Log Compaction是针对Key进行的,所以需要注意Key值不要为null。优先选择污浊率(dirtyRatio = dirtyBytes *I* (cleanBytes + dirtyBytes))最高的进行清理。为了 防止不必要的频繁清理,Kafka 还使用了参数 log.cleaner.min.cleanable.ratio (默认值为 0.5 )来限定可进行清理操作的最小污浊率。
Kafka 中用于保存消费者消费位移的主题_consumer_offsets 使用 就是 Log Compaction 策略。
Kafka每一个用于日志清理的线程都会使用一个名为SkimpyOffsetMap的对象来构建Key和Offset的映射关系的哈希表。日志清理需要遍历两次日志文件:第一次是用于记录每一个Key最后出现的Offset到哈希表中;第二次是只保留最后一个位置的Offset的值,在该Offset前的所有的K-V均清理。
Kafka提供了一个墓碑消息的概念:如果一条消息的key不为null ,但是其 value为null,那么此消息就是墓碑消息。
日志清理线程发现墓碑信息会进行常规的清理,并保留墓碑消息一段时间。
Log Compaction对日志进行压缩之后,日志是比原来的文件要小的,为了防止出现太多的小文件,Kafka在实际的清理过程中,并不对单个的日志文件进行单独清理,而是根据日志分段大小及日志索引大小分为若干组,每一组的日志分段最终只会生成一个新的日志分段。
在日志压缩的过程中,会将同一组的日志文件都复制到每一组的第一个日志文件同名的日志文件并加以.clean后缀,之后改名为.swap后缀,最后完成清理后,才删除.swap后缀。
磁盘存储
Kafka利用磁盘存储,是如何做到高性能的?
Kafka是使用的线性写入磁盘的方式,但是也不仅限于此。

页缓存
由于内存和磁盘的IO速率存在较大差异,在现代操作系统中,普遍使用页缓存的方式来加快对磁盘IO的操作:是读取磁盘数据时,首先从pagecache中去找对应的页缓存数据,若不存在,则从磁盘中加载到pagecache中;若是对磁盘数据进行修改时,也是一个加载到pagecache后,对缓存中的数据进行操作,并修改其值,使其成为脏页,操作系统pdflush线程会去定期检查脏页的情况,根据参数配置(脏页面数量达到多少值),然后进行刷盘操作,将页缓存中的数据刷到磁盘中。
磁盘IO过程
从编程层面来看磁盘IO可以分为以下4个种方式:
使用C库进行I / O
应用程序Buffer
->C库Buffer->文件系统页缓存->具体文件系统调用文件I / O
应用程序Buffer
->文件系统页缓存->具体文件系统使用
O_DIRECT绕过系统页缓存用户使用类似 dd 工具,并使用 direct 参数,绕过系统 cache 与文件系统直接写磁盘。
写操作
这里举例最长链路的写操作。
用户调用fwrite函数,将数据写到C库缓冲区后即返回,即写操作通常是异步操作;数据写入C库IOBuffer后,不会立即刷新磁盘,会将多次小数据量相邻写操作先缓存起来合并,最终调用write操作,一次性写入页缓存,或者将一个大块数据分为多次write,写入缓存;写入缓存后,页缓存中的数据也不会马上通过文件系统写到磁盘中,而是通过pdflush线程扫描,定期进行刷新操作。
读操作
这里举例最长链路的读操作。
用户调用fread函数,到C库缓冲区访问对应的数据,存在即返回,不存在则继续到页缓存中访问,若在页缓存中存在,则返回,不存在则通过文件系统进行磁盘读取,读取数据后返回,缓存到页缓存和C库缓冲区后返回,可以看出读操作是同步操作。
读写请求操作
通用块层根据I / O请求构造一个或多个BIO结构并提交给调度层;调度层将BIO结构进行排序和合并组织成队列确保读写情况经可能理想:尽量将多个读写操作进行合并,将随机读写变为顺序读写,加快访问速度,读应该尽量优先满足,写也不能等太久。

I / O 调度策略
针对不同的应用场景,不同的I / O调度策略也会对磁盘I / O读写性能有所影响:
NOOP
No Operation,维护了一个FIFO队列,大致使用了先来先服务的形式,之所以是“大致”,是其也做了一些优化,有些相邻的请求会被其合并。
CFQ(Linux默认)
按照I / O请求地址进行排序,而不是按照先来先服务的顺序进行响应。对于通用的服务器来说,CFQ是最好的选择。它试图均匀分布 I / O 带宽的访问,CFQ为每一个进程单独创建一个队列来管理该进程产生的所有请求,也就是说,每一个进程一个队列,各个进程之间的调度,使用时间片进行调度,以此来保证每个进程都能被很好地分配到 I / O 带宽,每个CFQ队列是按照 I / O 地址进行排序的,以尽量少的磁盘旋转次数,来确保处理尽可能多的 I / O 请求。在CFQ算法下,处理 I / O 的吞吐量提升了,但是可能会出现先来的 I / O 请求不一定会被处理,出现“饿死”的情况。
DEADLINE
DEADLINE是在CFQ的基础上,解决了“饿死”的极端情况,除了CFQ队列之外,DEADLINE在此之外还使用了FIFO队列来分别存储读写请求,读 I / O 队列的最大等待时间500ms,写 I / O 队列的最大等待时间5s。
他们的优先级为:
FIFO(read) > FIFO(write) > CFQ
ANTICIPATORY
CFQ和DEADLINE都是考虑了零散的 I / O 请求,而对于顺序的访问并没有做相关优化,ANTICIPATORY在DEADLINE的基础上,为每个读 I / O 都设置了6ms的等待窗口,在等待窗口期间,如果有相邻的 I / O 请求,就立马进行处理,ANTICIPATORY通过增加等待时间来获得更高的性能,这个原理通过延迟,将随机 I / O 请求转顺序 I / O 请求,通过延迟的读写 I / O 来换取更大的 I / O 吞吐量。适用于大多数环境,特别是 I / O 较多的环境。
在具体的使用场景中,还是需要通过分析不同的业务需求,通过具体的测试,来选择合适的调度算法。
Zero Copy
假设我们现在要从Kafka集群中拿出一条数据,若不使用零拷贝,则需要的数据流动过程大概是:
- 从磁盘中读取信息至
kernel - read buffer - 将
kernel - read buffer读取到application buffer(内核态 -> 用户态) application buffer复制到kernel - socket buffer(用户态 -> 内核态)kernel - socket buffer使用DMA的方式通过网卡将数据发送至客户端

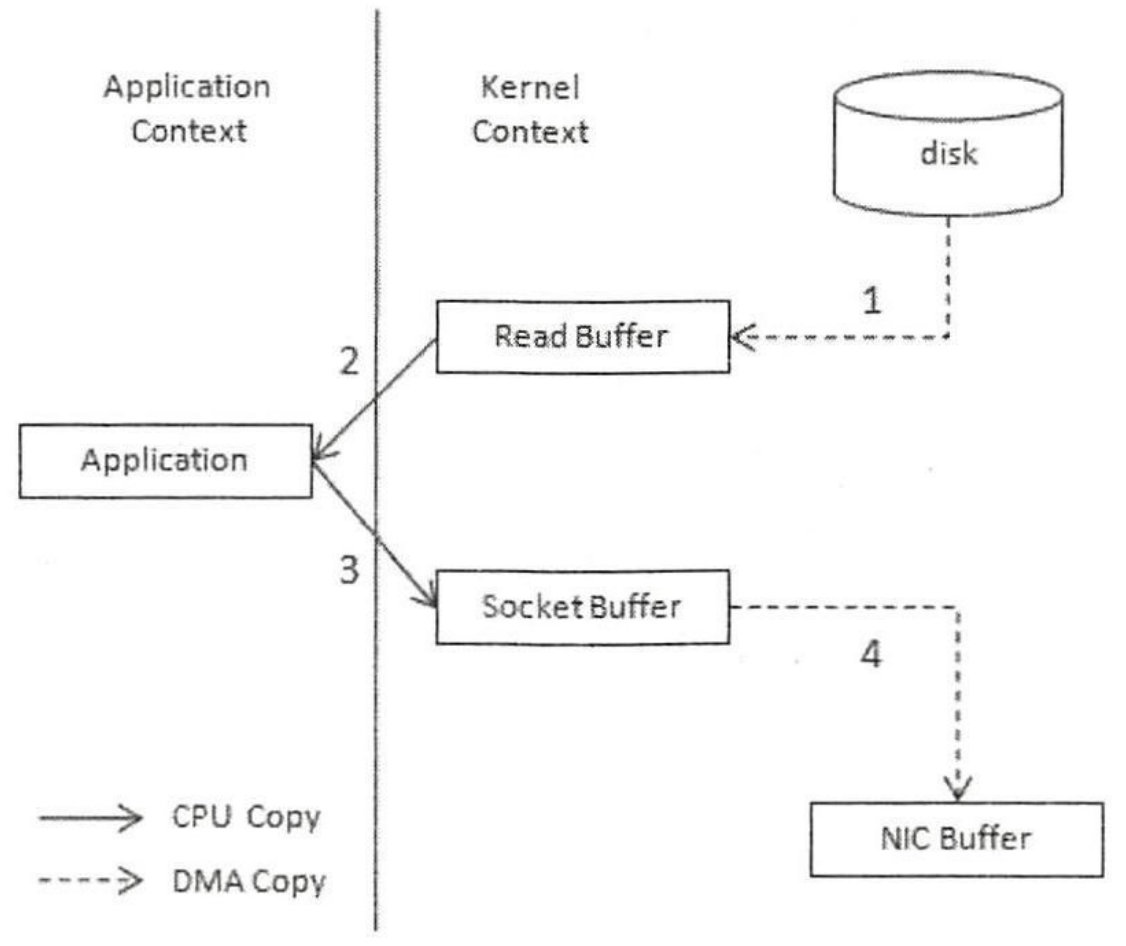
这里需要4次的数据拷贝。从内核空间到用户空间,再从用户空间到内核空间,是冗余的一次操作。
但是Kafka使用了Zero Copy技术,避免了数据的额外拷贝。拷贝过程:
- 从磁盘中读取信息至
kernel - read buffer kernel - read buffer到kernel - socket buffer拷贝(这里也可以使用Scatter/Gather DMA的方式,将不连续的read buffer写到描述符链表中,减少一次拷贝)- 通过DMA将
kernel - socket buffer中的数据写出,或者使用Scatter/Gather DMA进行写出