1. partition by函数 | |
select deptno, ename, sal, sum (sal) over(partition by deptno order by ename) 部门连续求和, --各部门的薪水 "连续" 求和 sum (sal) over(partition by deptno) 部门总和, -- 部门统计的总和,同一部门总和不变 100 * round(sal / sum (sal) over(partition by deptno), 4 ) "部门份额(%)" , sum (sal) over( order by deptno, ename) 连续求和, --所有部门的薪水 "连续" 求和 sum (sal) over() 总和, -- 此处 sum (sal) over () 等同于 sum (sal),所有员工的薪水总和 100 * round(sal / sum (sal) over(), 4 ) "总份额(%)" from emp 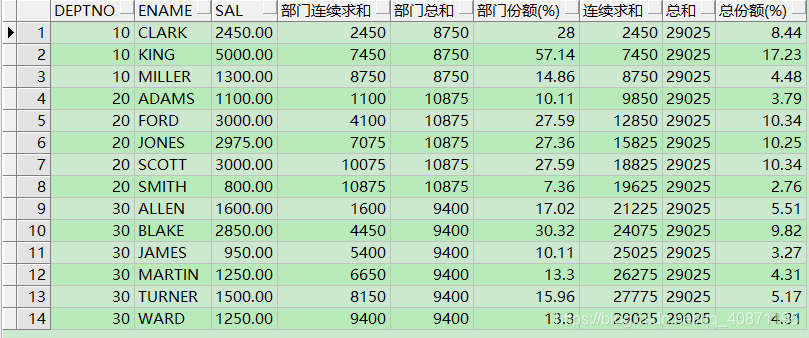 1. group by是分组函数,partition by是分析函数(然后像sum()等是聚合函数); 2. 在执行顺序上, 以下是常用sql关键字的优先级 from > where > group by > having > order by 而partition by应用在以上关键字之后,实际上就是在执行完select之后,在所得结果集之上进行partition。 3. partition by相比较于group by,能够在保留全部数据的基础上,只对其中某些字段做分组排序(类似excel中的操作),而group by则只保留参与分组的字段和聚合函数的结果(类似excel中的pivot)。 | |
| 2、rank over() 函数 | |
rank () over ( [query_partition_clause] order_by_clause ) dense_rank () over ( [query_partition_clause] order_by_clause ) 【功能】聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。 【参数】dense_rank与rank()用法相当 【区别】dence_rank在并列关系是,相关等级不会跳过。rank则跳过.
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内) dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。 | |
3. row_number()函数 | |
语法【语法】 ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2)
【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的) row_number() 返回的主要是“行”的信息,并没有排名. 【参数】 【说明】Oracle分析函数 【主要功能】:用于取前几名,或者最后几名等 | |
4.lag( )和lead( )函数 | |
这两个函数是偏移量函数,可以查出一个字段的上一个值或者下一个值,配合over来使用。
lead函数,这个函数是向上偏移. lag函数是向下偏移一位. 语法【语法】 lag(EXPR, < OFFSET > , < DEFAULT > ) LEAD(EXPR, < OFFSET > , < DEFAULT > ) 【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的) lead () 下一个值 lag() 上一个值 【参数】 EXPR是从其他行返回的表达式 OFFSET是缺省为1 的正数,表示相对行数。希望检索的当前行分区的偏移量 DEFAULT是在OFFSET表示的数目超出了分组的范围时返回的值。
expr 是要做对比的字段 offset 是expr字段的偏移量 比如说 offset 为2 则拿expr的第一行和第三行对比,第二行和第四行,依次类推,offset的默认值为1! | |
5、with ... as函数 | |
当在sql查询时需要对有规律的一批数据进行分析处理而又不想将这批数据存入实体表时,我们可以使用with关键字临时构建一个虚拟的数据集,以便对其进行与实体表相似的sql操作,如:  (注:with关键字构造的虚拟数据集临时存放于用户的临时表空间中) | |
6、 exists/in及not exists/not in | |
仅从语法上来讲,在大多数情况下exists与in及not exists与not in可相互转换使用,但其各自的适用场景略有不同,执行效率也有差异。当子查询数据量较小时应使用in或not in,反之则使用exists或not exist比较合适,因为使用in时,Oracle查询是执行顺序是由内而外的,但如果使用exist的话Oracle则会“先外后内”,查询开销相对较大,现举例如下: 查询所有绑定了部门ID的用户(适合用in的场景)  适合用in的场景 查询未被账户绑定的部门(适合用not exists的场景)  | |
7、union与union all | |
union,查询返回多表去重后的结果集:  union,查询结果去重 union all,查询返回多表未重的结果集:  union all并集查询,不去重 | |
8、 nvl与decode | |
select ename ,sal+comm total from emp; //nvl处理null,nvl(列名称|具体的值,默认值) select ename, sal+nvl(comm, 0) total from emp; 查询所有的员工信息,显示员工的中文职位 CLERK=办事人员,SALESMAN=销售人员,PRESIDENT=董事长,MANAGER=部门经理,ANALYST=分析人员 方法1: select ename, case when job='CLERK' then '办事人员' when job='SALESMAN' then '销售人员' when job='PRESIDENT' then '董事长' when job='MANAGER' then '部门经理' else '分析人员' end from emp; 方法2: select ename,decode(job,'CLERK','办事人员','SALESMAN','销售人员','PRESIDENT','董事长','MANAGER','部门经理','ANALYST','分析师') from emp;  | |
9、start with函数 | |
SELECT ... FROM + 表名 [START WITH + 条件1] CONNECT BY PRIOR + 条件2 WHERE + 条件3 条件1:是根节点的限定语句,当然可以放宽限定条件,以取得多个根节点,也就是多棵树;在连接关系中,除了可以使用列明外,还允许使用列表达式。 START WITH 子句为可选项,用来标识哪个节点作为查找树形结构的根节点。 若该子句省略,则表示所有满足查询条件的行作为根节点。 条件2:是连接条件,其中用PRIOR表示上一条记录,例如CONNECT BY PRIOR STUDENT_ID = GRADE_ID,意思就是上一条记录的STUDENT_ID是本条记录的GRADE_ID,即本记录的父亲是上一条记录。CONNECT BY子句说明每行数据将是按照层次顺序检索,并规定将表中的数据连入树形结构的关系中。 PRIOR运算符必须放置在连接关系的2列中某一个的前面。对于节点间的父子关系 ,PRIOR运算符在一侧表示父节点,在另一侧表示子节点,从而确定查找树结构的顺序是自顶向下,还是自底向上。 条件3:是过滤条件,用于对返回的记录进行过滤。 | |
| 10、rollup函数 | |
rollup()是group by的一个扩展函数,初步的感觉是,可以多个列进行group by,然后分别进行统计。 示例: 1. 证券池配置表,按池子类型统计:
跟普通的group by相比,就是最后多了一个总的统计 | |
10、grouping函数 | |
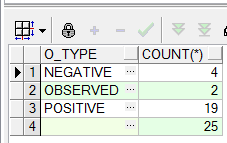
grouping(columnA):当前行如果是由rollup汇总产生的,那么columnA这个字段值为1否则为0 元数据: sql:
通过grouping查询后的数据: |


版权声明:本文为qq_40871196原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。