主要思路参考:
Face verification VS Face recoginition
对于人脸验证,我们完全可以将之看作为一个二分类问题,但人脸识别发展到现在,我们依然用人脸识别的方法来解决。
Encoder
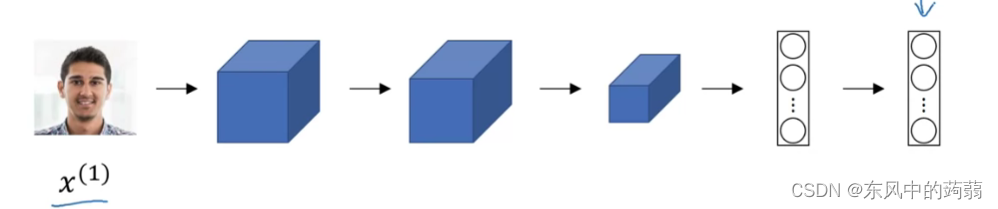

- 我们输入一张图片进入encoder,经过一系列网络,输出一串独特密码,这串密码就编译了这个人。
- 我们在进行比较的时候,将当前的图片经过encoder编码得到一串密码,将这串密码和数据库中所有的密码比较。如果f ( k e y , k e y i d a t a b a s e ) ≤ α f(key,key_{i_{database}}) \leq\alphaf(key,keyidatabase)≤α,我们就认为此人就是数据库中的这个人。
Triplet Loss
那问题来了:那我们如何训练这个网络呢(Encoder)?

我们将数据三个分为一组。
( A n c h o r , P o s i t i v e , N e g a t i v e ) A n c h o r 表 示 我 们 需 要 识 别 的 这 个 人 , P o s i t i v e 表 示 该 人 的 另 一 张 图 片 , N e g a t i v e 表 示 另 一 个 人 的 图 片 。 (Anchor,Positive,Negative)\\ Anchor表示我们需要识别的这个人,Positive表示该人的另一张图片\\,Negative表示另一个人的图片。(Anchor,Positive,Negative)Anchor表示我们需要识别的这个人,Positive表示该人的另一张图片,Negative表示另一个人的图片。
我 们 定 义 T r i p l e t L o s s : M a x ( ∣ ∣ ( k e y A n c h o r ) − ( k e y P o s i t i v e ) ∣ ∣ − ∣ ∣ ( k e y A n c h o r ) − ( k e y N e g a t i v e ) ∣ ∣ + α , 0 ) 我们定义Triplet Loss:\\ Max(||(key_{Anchor}) - (key_{Positive})|| -||(key_{Anchor})\\ - (key_{Negative})|| + \alpha ,0)我们定义TripletLoss:Max(∣∣(keyAnchor)−(keyPositive)∣∣−∣∣(keyAnchor)−(keyNegative)∣∣+α,0)
我们在优化Encoder的时候,我们需要同一个人的不同照片经过Encoder编译后的key差距尽可能小,同时希望不同人的图片经过编译后key差距尽可能大。
至于中间的神经网络,可以自行编写,甚至可以使用之前的图片分类的VGG或者ConvNet。