引入依赖:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
WordCount程序:
package com.spark.core.wc
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// ToDo 建立和Spark框架的连接
val conf = new SparkConf() // Spark的基础配置对象
conf.setMaster("local")
conf.setAppName("WordCount")
val sc = new SparkContext(conf) // Spark的上下文环境对象
// ToDo 执行业务操作
// 1. 读取文件,获取每行数据 => hello world, hello world
val lines = sc.textFile("datas")
// 2. 将每行数据根据分隔符进行分词,获取每个单词 => hello, world, hello, world
val words = lines.flatMap(line => line.split(" "))
// 3. 将数据根据单词进行分组,便于统计 => (hello, hello), (world, world)
val wordGroup = words.groupBy(word => word)
// 4. 对分组后的数据进行转换 => (hello, 2), (world, 2)
val wordCount = wordGroup.map({
case (word, list) => (word, list.size) // 模式匹配
})
// 5. 将转换结果采集到控制台打印出来
val array = wordCount.collect()
array.foreach(println)
// ToDo 关闭连接
sc.stop()
}
}
执行程序: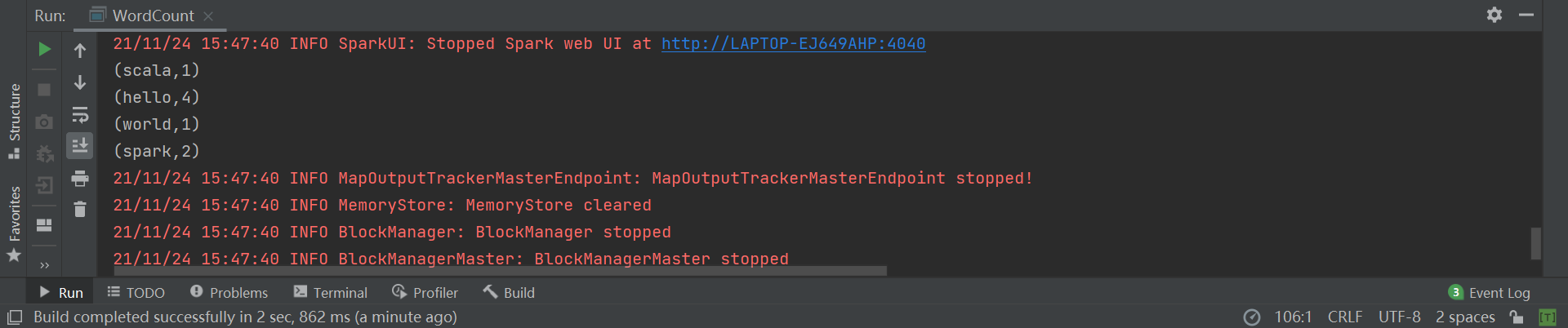
修改和简化WordCount程序:
package com.spark.core.wc
import org.apache.spark.{SparkConf, SparkContext}
object WordCount03 {
def main(args: Array[String]): Unit = {
// ToDo 建立和Spark框架的连接
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
// ToDo 执行业务操作
val wordCount = sc
.textFile("datas") // 获取每行数据
.flatMap(_.split(" ")) // 根据分隔符进行分词
.map((_, 1)) // 设置单词数量为1
// reduceByKey:相同的key的数据,可以对value进行reduce聚合
.reduceByKey(_+_) // 根据单词进行分组,对单词数量进行聚合
val array = wordCount.collect()
array.foreach(println) // 打印
// ToDo 关闭连接
sc.stop()
}
}
版权声明:本文为weixin_45034316原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。