菜鸟记所有篇章都是个人随手记,可能存在知识点遗漏,请多包涵。
之后篇章的菜鸟记 概念居多。
上篇落写了StringBuffer,本篇补充上
’
StringBuffer: 字符串的缓冲区 ,线程安全, 性能慢
是final 修饰的类 , 不能被继承;
构造器:
StringBuffer(String str);
StringBuffer(int capacity);
StringBuffer();
常用方法:
append();
charAt(int index);
capacity()
delete(int start, int end)
reverse(); 翻转输出
length();
insert(int offset, String str);
StringBuilder: 字符串缓冲区, 线程不安全 , 性能快
一、异常
1.异常体系:
Throwable: 类
Error:
VirtualMachineError: 虚拟机错误
StackOverflowError: 栈内存
OutOfMemoryError: 内存泄漏错误
Exception:
IOException: IO流异常
RuntimeException: 运行时异常
IndexOutOfBoundsException: 下标越界
StringIndexOutOfBoundsException:
ArrayIndexOutOfBoundsException:
数学异常
NullPointerEception:
ClassCastException
NumberFormatException
IllegalArgumentException: 非法参数异常
受检查异常(CheckedException)不是异常体系中,是编译器只能编译器Editplus自动帮我们检测的
java中处理异常的方式:
1.捕获异常:
try{
}catch(){
}finally{
}
try{
有可能出现异常的代码
}catch(NullPointerException | ClassCastException e ){
打印异常信息
}
try{
}finally{
}
finally块儿一定执行吗?
1)通常情况下会执行 ,但是 如果系统中出现了System.exit(0): 的代码时 就不执行
2)在没有进入到 try catch finally 代码块儿就已经出现了 异常
那么finally 块儿也不会执行
return 关键字的用法:
1.作为方法的返回值
return 需要返回的值;
2.作为 终止方法的关键字
return;
finally块儿中忌讳 使用return关键字
1.会将正常的返回值覆盖掉
2.会覆盖掉异常信息
所以finally块儿 中不可以使用 return 关键字
2.抛出异常:
throws 和 throw 区别:
throws 声明 异常类型
throw 抛出 new 异常类型();
自定义异常类型的时候:
throw new MyException();
二、集合框架
1.List
集合的作用:
- 变量只能存储单个数据
- java提供了数组容器:
1.数组长度一旦确定不可以改变
2.数组必须通过下标来获取元素
3.为了解决 数组的局限问题
集合框架: 容器
java提供的集合框架的体系:
Iterable:接口 / Iterator: 真正的迭代器
采用的是 单值存储
Collection: 接口
List:
ArrayList :实现类 线程不安全的 ,性能快
常用构造器:
rrayList();
ArrayList(int capacity); 容量
ArrayList(Collection e);
常用方法:
remove(int index); 根据下标删除
remove(Object obj); 根据对象删除
set(int index, E element)
**** subList(int fromIndex, int toIndex); 分页
toArray(); 将一个集合编程 对象数组
ArrayList: 使用对象数组实现的 Object[] 通过下标来获取元素
add(), remove(int index); remove(Object obj);
set(int index, Object obj); get(int index);
增 , 删 , 改 , 查 操作
indexOf(); 返回这个元素第一次出现的位置
lastIndexOf();
clear(); contains(); isEmpty(); subList(begin,end);
Set:
LinkedList :实现类
Vector: 实现类 (过时了) 线程安全的 ,性能慢
线程安全的类 : 有什么特点: 就是方法上多个一个 synchronized 单词
同步锁
java.util.concurrent.* 并发包 1.5
在并发情况下使用: 高并发
已有 一个 “用户” 操作这个集合是 单线程
多线程 多个 “用户” 来同时 获取
Vector的子类:
Stack存储数据原理:
常用方法:
empty(); 判断这个栈是否是空栈
peek(); 弹出;查看 但是 不删除
pop(); 弹出 , 查看, 删除
push(); 压栈
search(Object o); 检索
入栈顺序是: 1 , 2 , 3
出栈的顺序有几种?
A: 1 ,2 ,3
B: 2 ,1, 3
C: 3, 2 ,1
D: 1, 3, 2
E: 3 ,1, 2
F: 2, 3, 1
LinkedList: 重要 双向链表实现的
数据结构: 线性表
数组:通过下标来 存取
链表:没有下标
链表;
单向链表: 向一个方向
双向链表: 双向 方向
循环链表: 头和尾巴可以向连
LinkedList:
构造器:
LinkedList();
常用方法:
add(Element e);
add(int index, Element e );
clear(); 清除
contains(Object o);
get(int index);
indexOf(Object o)
lastIndexOf(Object o)
remove(int index);
remove(Object obj);
set(int index, E element);
size();
toArray();
我们在使用集合存储数据后 ,进行 操作
添加,删除: 使用LinkedList
获取 比较多 使用ArrayList
List接口的特点:
有序的(存储顺序和 输出顺序一致),可重复的 , 允许null 存储
凡是 继承 , 或实现 Iterable 接口的 都是具有了 迭代能力:
但是真正的迭代功能是 Iterator 迭代器做的
Iterator 中 尽量不要调用多次 next方法
Collections 和 Collection 区别:
Collections:是操纵集合的工具类
shuffle(); 打乱顺序输出
sort(); 排序 只能从小到大 排序
采用双值存储
Map:接口
key - value
2队列
队列:
Queue: 接口 单向 链表
Deque: 子接口 双向链表
Queue: 一个方向进 ,另一个方向出
常用方法:
add(E e); 添加
element(); 检索,但不删除,这个队列的头。
如果队列为null 抛出异常 没有这个元素异常
offer(E e); 添加
peek(); 查看 如果多列为null 返回特殊值 null
poll(); 检索删除, 返回特殊值 null
remove(); 检索删除 ----> 抛异常
Deque:入口既 可以进 , 又可以出
双向队列
addFirst();
addLast();
getFirst();
getLast();
offerFirst(E e);
offerLast(E e)
peek();
peekFirst();
peekLast();
poll();
pollFirst();
pollLast()
pop()
push(E e);
线性表:
数组: 动态数组
链表:单链表, 双链表 , 循环链表
栈:
队列: 单向 , 双向
Collection:
List:
|-- ArrayList
|-- LinkedList
|-- Vector
|-- Stack
Queue:
|-- LinkedList
|-- Deque
|–LinkedList
3.Set集合
泛型:
数据类型参数化;
语法结构:
List<引用数据类型 >
泛型的出现帮助我们在编译期间 就 检测了 数据类型是否 合理
防止了程序在运行期间 出现 类型转换异常,让程序特具有健壮性
Set:
无序 , 不可重复的集合
hashCode() //哈希码
HashSet: 重点注意 存储 自定对象时要 重写 hashCode和 equals
由哈希表(散列表)实现 , 底层就是用 HashMap实现的
无序的(输入顺序和 输出顺序不一致) ,允许存储null 值
不可重复
常用构造器:
HashSet(); 默认长度为16
HashSet(int initialCapacity);
常用方法:
add();
clear();
contains(Object obj);
isEmpty();
iterator()
remove(Object o)
size()
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //0x223F 当前这个元素在哈希表中的位置
final K key; //元素本身
V value; new Object(); //对象, 补充位置
Node<K,V> next;
HashMap:
jdk1.7 和 jdk1.8的区别:
1.7 对象数组 + 链表形式
1.8 对象数组 + 链表 + 红黑树
Entry[]
负载因子 0.75 : 阈 yu 值 代表边界的意思
HashMap:存储原理
当我们向 HashMap中存储对象时,一定要经历两次操作(计算哈希值 ,equals比较内容)
1.我们必须通过计算 获取到当前对象的 hash值 —> 散列值
如果这个位置上没有内容,我们就直接存储,
如果这个位置上有值了 ,那么久比较内容,如果内容相等
就去重,如果不相等就以链表的形式向下存储,如果
链表的形式长度 > 7 就以红黑树的形式存储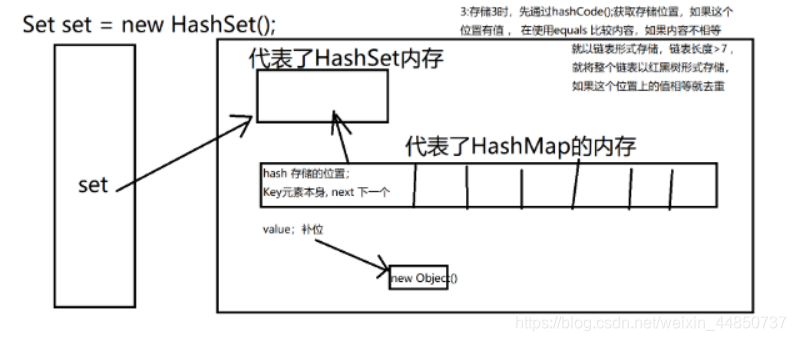
在使用HashSet存储对象时:
如果 equals 相等 ,hashCode 一定相等吗?
所以 一定相等现有的 hashCode 在有equals
如果hashCode值相等, equals一定相等吗?
我们管 这种 hashCode相等的 情况 叫 哈希碰撞 (哈希冲突)
什么是哈希冲突?(考虑下在什么场景下回发生哈希冲突)
TreeSet: 有序的set 集合
Comparable: 可以比较的
和
Comparator: 自定义比较器
区别:
它是让当前 需要排序的对象 具有 比较的能力,
实现这个接口后 重写 compartTo方法,是jvm 默认的比较规则
单一 , 会"污染"当前类的结构
Comparator被称为 自定义比较器:
使用人员可以自行 定义多个 比较器 ,实现比较规则,并重写compare方法
相比Comparable 更加灵活 ,并且不会"污染" 实现比较功能的类
提供了匿名内部类的方式:
例如:
Set<Student> set = new TreeSet<>(new Comparator(){
@Override
public int compare(Student s1,Student s2){
reutrn 0;
}
});
4.Map集合
Map集合:
存储方式 使用 键值对儿 存储的
key - value
HashMap:
特点:key 是 不允许重复的 ,而且value 会被 覆盖掉
无序的
map在存储时 是根据 key 来判断的,跟value 无关
常用方法:
1.clear();
2.put(key,value); 向map 集合添加元素
3.containsKey(); 判断是否包含 键
4.containsValue(); 判断是否包含 值
5.String remove(Object obj);
6.boolean remove(Object obj,Object value);
7.V replace(K key, V value);
8.boolean replace(K key, V oldValue, V newValue);
9.size(); 返回map 集合中元素的个数
10.isEmpty(); 判断是否为 空
*** 11.entrySet(); 遍历 整个 map 集合
要同时获取 key 和 value
12.values(); 只获取 map 集合中的所有value 值
13.keySet(); 只获取 map 集合中的所有key 值
14.get(Object key); 根据键 找 值
TreeMap:
这是有序的map 集合 但是,这个排序 是根据 key 值排序的,
如果存储String ,Integer 类型 根本不需要我们考虑其他的
但是如果存储自定义对象时 ,并且 自定义对象 还做了 key值 ,就必须实现 比较器
但是这么做有没有什么意思; 如果自定义对象做了 value 值,排序规则
是根据key来定义的,跟 value 没关系
**** TreeMap 的key 是不允许存储 null 值的
因为 需要根据key 来排序
Hashtable:
是线程安全的, 性能慢, 采用的是 独占锁
Hashtable中 的键和值 都不可以 存储null 值
Enumration elements();
Enumration keys();
================================================
高并发的场景:
选择线程安全的 容器;
Hashtable : 性能慢
jdk1.5 : 并发包 concurrent。
java.util.concurrent.concurrentHashMap :synchroized
分段锁机制