1)Film_Recommend_Dataframe 为推荐系统的后端完整项目,目录结构为
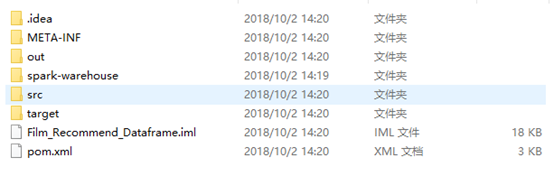
1.1)Out文件夹:
out\artifacts\Film_Recommend_Dataframe_jar\Film_Recommend_Dataframe.jar
Film_Recommend_Dataframe.jar包是将整个项目打包后得到的jar包
我们可以如下命令启动spark运行该jar包:
./bin/spark-submit --class recommend.MovieLensALS
~/IdeaProjects/Film_Recommend_Dataframe/out/artifacts/Film_Recommend_Dataframe_jar/Film_Recommend_Dataframe.jar /input_spark 1
效果和在idea运行程序相同
1.2)Src文件夹:
src\main\recommend目录下为项目的所有代码
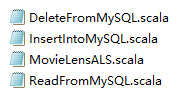
推荐算法主程序为:
![]()
1.3)Pom.xml :为maven的配置文件
1.4)其他文件是自动生成的文件
2)movierecommendapp 为推荐系统的前端代码
2.1)views目录下是前端界面文件
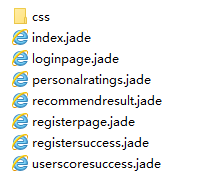
Index.jade: 首页
Loginpage.jade :登录界面
Personalratings.jade:评分界面
Recommendresult.jade: 推荐界面
Registerpage.jade: 注册界面
Registersuccess.jade:提示注册成功界面
Userscoresuccess.jade:提示评分成功界面
Css:样式优化
2.2)movierecommend.js :实现跳转、操作数据库和调用后端jar包
3)数据库
含有四个表
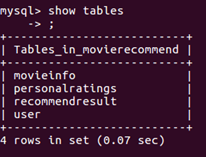
Movieinfo: 存储电影信息
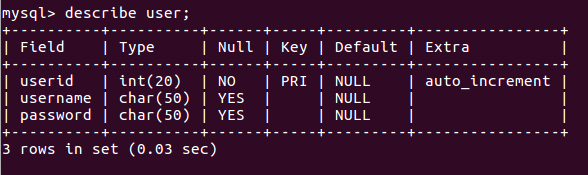
User:存储用户信息
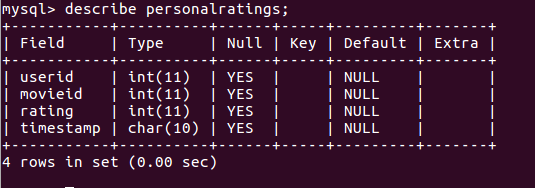
Personalratings:存储用户的评分信息
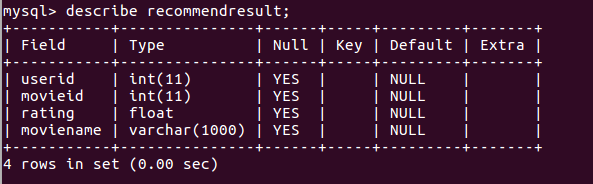
Recomendresult:存储推荐结果
每个表的设计结构:

4)总体流程
4.1)通过命令行 cd 到前端文件夹movierecommendapp的目录下
4.2)通过执行 node movierecommend.js 启动http服务器
4.3)在浏览器中输入localhost:3000 进入到首页
4.4)在前端进行操作(登录、注册、评分等)
点击相关按钮,node movierecommend.js会执行相应的跳转、数据库操作(查询、插入等)、启动spark执行Film_Recommend_Dataframe.jar包得到推荐结果并插入数据库
