技术栈:Canal+Kafka+Zookeeper
前言
当系统数据库连接数不够用、单表存储数据量超过特定量时候我们要考虑进行分库分表操作。
分库分表一时爽,如果没有足够的经验,分表后的数据满足不了业务查询等操作是个令人头疼的事,分表后的分页查询、出报表数据、出对账文件一系列问题确实让人头大,本篇文章我们对分表后的数据实现聚合,将分表后各个表中的数据再存储到一个表中,对总表进行分区处理,以供后期的一些查询操作。
本篇文章我们基于Alibaba的开源组件Canal进行搭建一套数据同步系统,将分表数据进行聚合。
针对Canal架构原理,前段时间在公司做这套数据同步系统时候总结过一篇水文Canal 架构解析水文 ,看热闹的看客可以移步去看下,作为开源的项目,个人还是建议看下源码,源码确实写的很不错的。
针对基础概念性的东西这里就不多说了,网上介绍基础概念以及搭建过程的东西还是很多的,以后有时间在介绍。
企业中经常canal做数据聚合,数据异构等,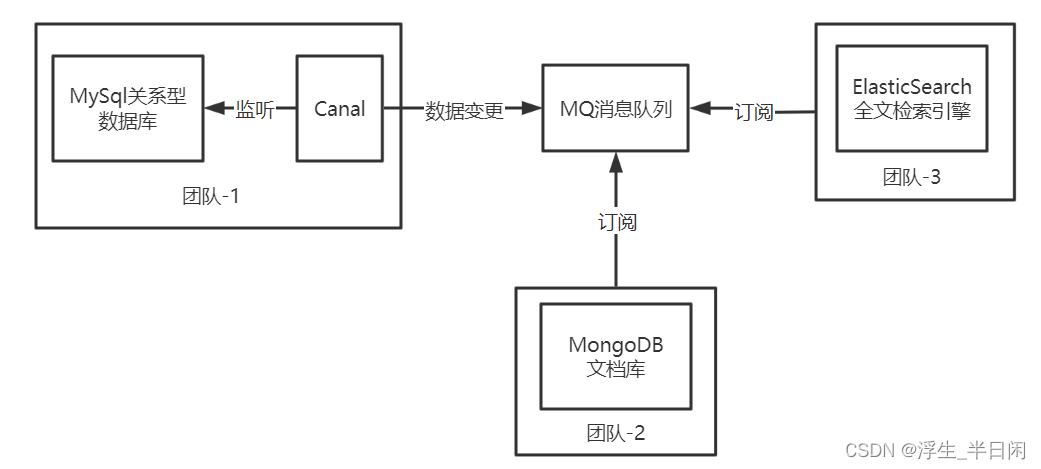
系统搭建
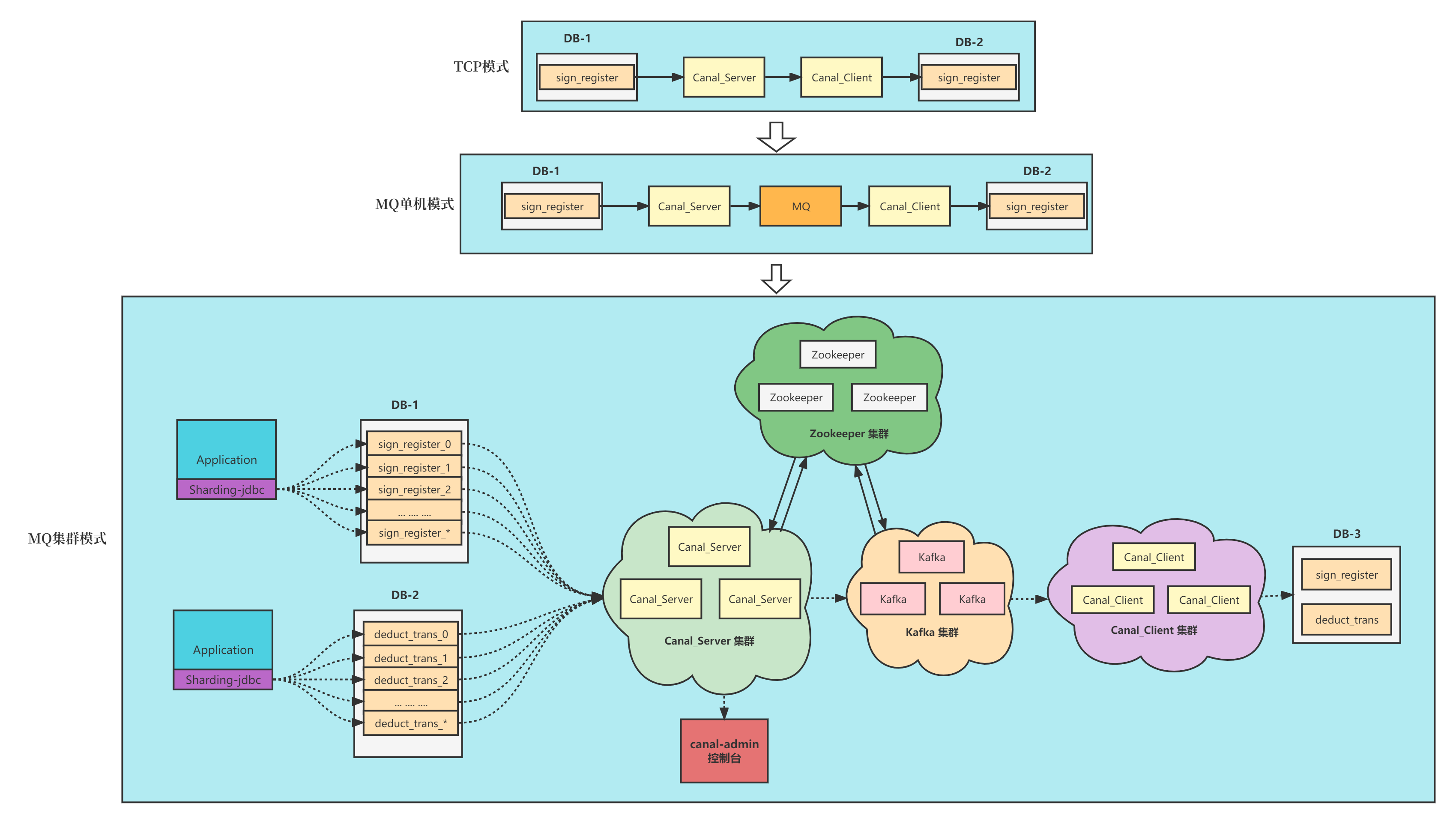
系统搭建一般也就这三种模式了,当然大神可以直接通过CanalServerWithEmbeded组件直接嵌入到自己的应用系统实现,这个对开发能力要求就比较高了,我们还是采用将server单独部署成一个应用使用方式吧。 一般自己玩玩的话就是使用前两种就行了,但是对于生产使用,一般是第三种模式了。
我们就直接从第三个部署方式 MQ集群模式介绍,首先从左往右看,最左边是我们应用集成了分表插件进行分表。然后Canal Server获取到日志流进行解析加工处理,投递到MQ,Canal Client 消费到消息后再加工处理下进行存储,这个是核心执行流程,Canal Admin用于管理配置Server配置信息,Zookeeper用于存储一些元数据信息,如:同步日志文件、偏移量,以及控制Instance启动节点等等。图中还少画了些系统,如prometheus,对Server进行监控。
1.源码结构
首先我们看下Canal项目源码结构 [官网跳转],我们下面部署的几个项目源码都来自这里。
1.1 admin模块
canal-admin设计上是为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。
1.2 client模块
canal的客户端源码,client主要是通过CanalConnector这个接口的实现类完成客户端的大部分功能,包括连接、订阅、数据获取等。如我们编写的stater通过如下代码链接到kafka。
public KafkaCanalClient build() {
KafkaCanalConnector connector = new KafkaCanalConnector(servers, topic, partition, groupId, batchSize, true);
KafkaCanalClient kafkaCanalClient = new KafkaCanalClient();
kafkaCanalClient.setMessageHandler(messageHandler);
kafkaCanalClient.setConnector(connector);
kafkaCanalClient.filter = this.filter;
kafkaCanalClient.unit = this.unit;
kafkaCanalClient.batchSize = this.batchSize;
kafkaCanalClient.timeout = this.timeout;
return kafkaCanalClient;
}
1.3 client-adapter模块
客户端适配器,展开模块的目录结构,从名字就能大概才出来它是干啥的了,客户端数据落地的适配及启动功能,。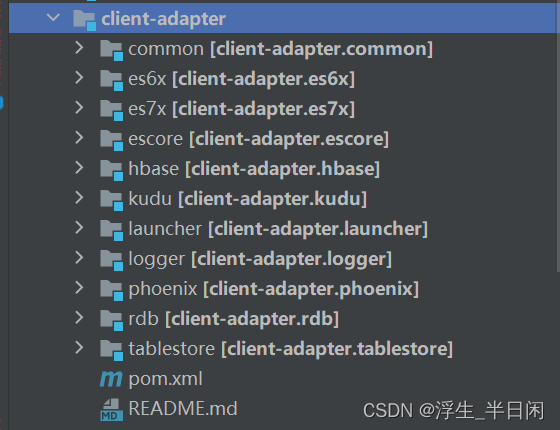
1.4 common模块
common模块主要是提供了一些公共的工具类和接口。
1.5 connector模块
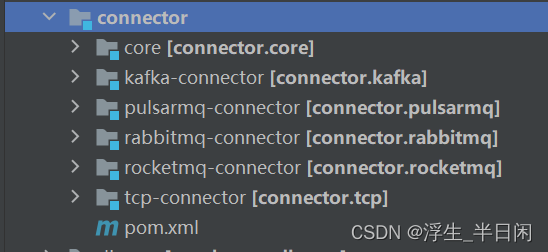
1.6 dbsync模块
原始的binlog都是二进制流,需要解析成对应的binlog事件,这些binlog事件对象都定义在dbsync模块中。
1.7 deploy模块
deploy模块负责启动canal server以及canal instance。
启动入口如下,可从这里开始看源码: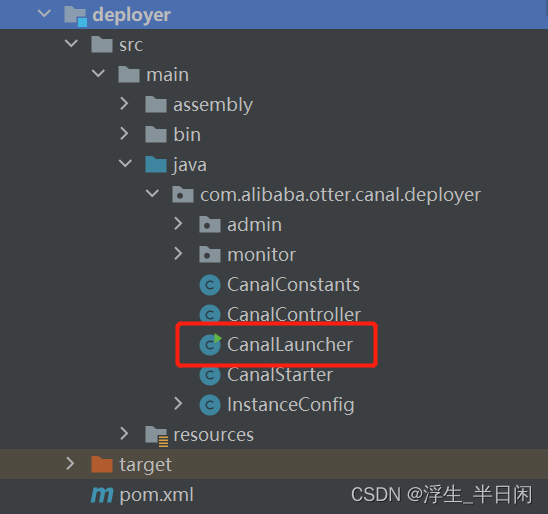
1.8 example模块
一些使用example的demo。
1.9 server模块
canal服务器端,对应canal整个服务实例,一个jvm实例只有一份server。核心接口为CanalServer,有两个实现:
CanalServerWithEmbedded
CanalServerWithNetty
这两个实现代表了canal的两种应用模式,CanalServerWithNetty在canal独立部署场景发挥作用,开发者只需要实现cient,不同的应用通过canal client与canal server进行通信,canal client的请求统一由CanalServerWithNetty接受进行处理。
而通过CanalServerWithEmbeded,可以不需要独立部署canal,而是把canal嵌入到我们自己的服务里,这种对开发者的要求就比较高。
2.0 instance模块
核心的模块之一。在一个 Canal 实例中只有启动 Instace,才能实现数据的同步。一个 Canal Server 实例中可以创建多个 Instance 实例。
instance模块有四个核心组成部分:parser模块、sink模块、store模块,meta模块。
2.1 parser模块
parser模块用来订阅binlog事件,然后通过sink投递到store。
2.2 sink模块
根据一定的规则,对binlog数据进行一定的过滤。另外还会做一些数据分发的工作。
2.3 store模块
用来执行最终的落库,数据存储。
2.4 prometheus模块
监控收集指标。
2.5 protocol模块
定义了client和server的通信协议。
包含两部分,一部分是进行binlog订阅时,binlog转换为我们所定义的Message。
第二部分是client与server进行传输的TCP协议。
2.部署配置
2.1 Canal Admin部署配置
在部署集群模式下,首先部署个Canal Admin 通过Admin 控制台配置Canal Server的一些参数。
下载 canal admin
此项目下载后 解压 修改下application.yml配置文件
vi conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306 //数据库地址
database: canal_manager //canal-admin使用的数据库
username: canal //用户名
password: canal // 密码
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
创建表sql此目录下。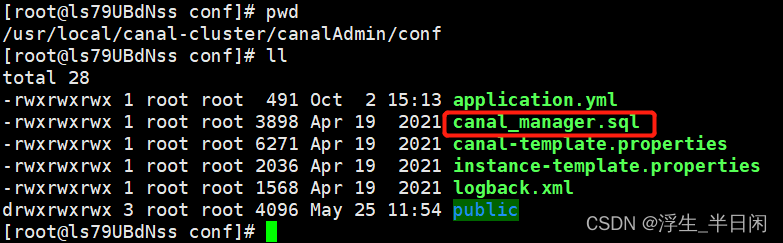
相关表如下:

过于简单不再展开了,主要是修改下端口、数据库信息,Canal Server 会调用(默认5s一次)Canal Admin提供的接口获取到相关参数,修改好配置后执行启动:
[root@ls79UBdNss bin]# ./startup.sh
登录
登录后创建集群:
导入模板,其他配置参考官网解说,因为我们此系统MQ使用的是Kafka所以此处修改mode为kafka。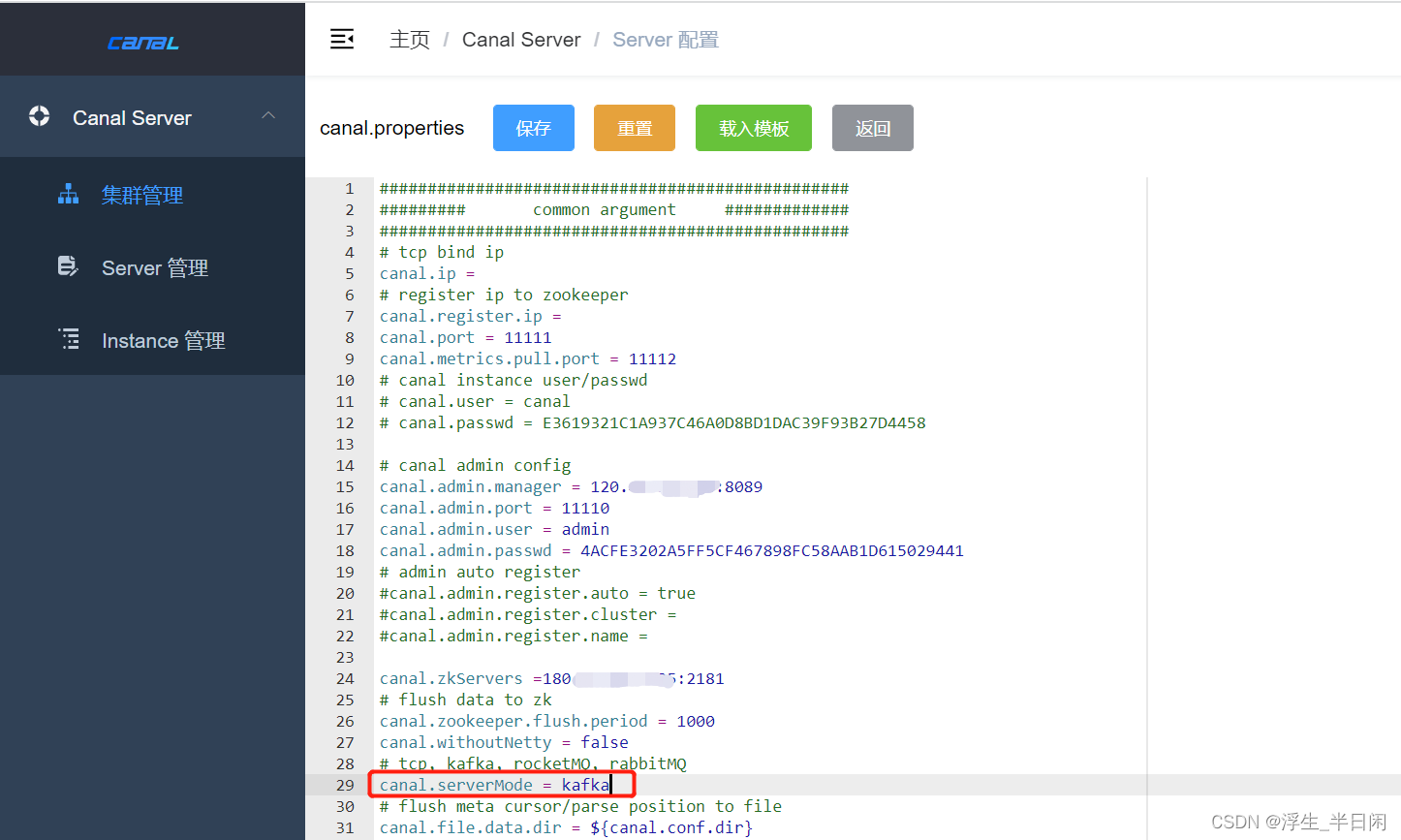
此时Canal Admin工作暂时告一段落,此时Server 管理中没有数据。
接下来安装启动Canal Server,完成后还会再来配置。
2.2 Canal Server部署配置
下载 canal adapter
canal adapter项目就是我们系统架构组成部分的canal server系统,这个是核心系统。
下载解压,然后修改对应的配置文件:
vi canal_local.properties
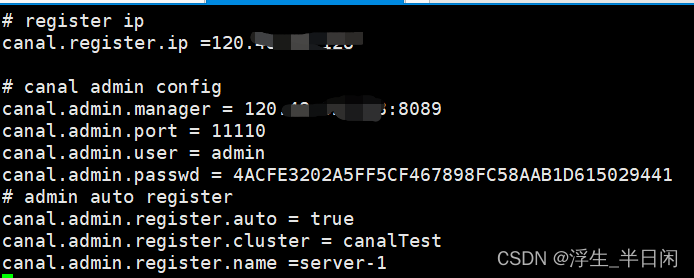
主要是修改连接Canal Admin的相关信息,注意这个配置项,是我们在Admin创建的集群的名称。
canal.admin.register.cluster = canalTest
使用命令启动。
[root@ls79UBdNss bin]# ./startup.sh local
然后从Canal Admin后天可以看到已经连接上来的Canal Server相关信息了,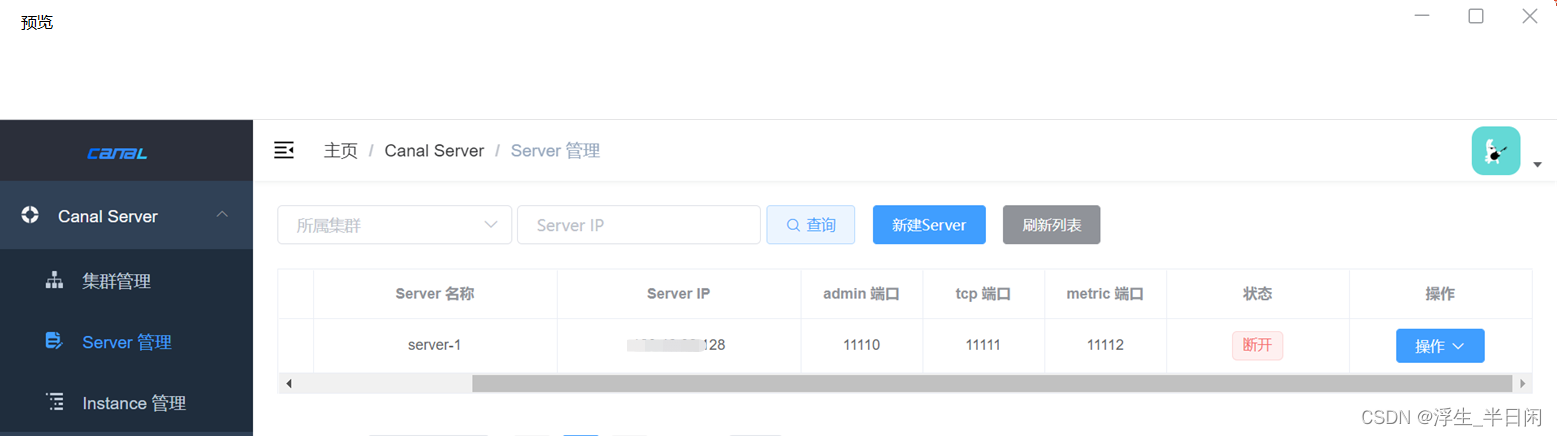
启动了,但是没有成功,表怕,这时候需要排查下了,查看日志:
报错信息: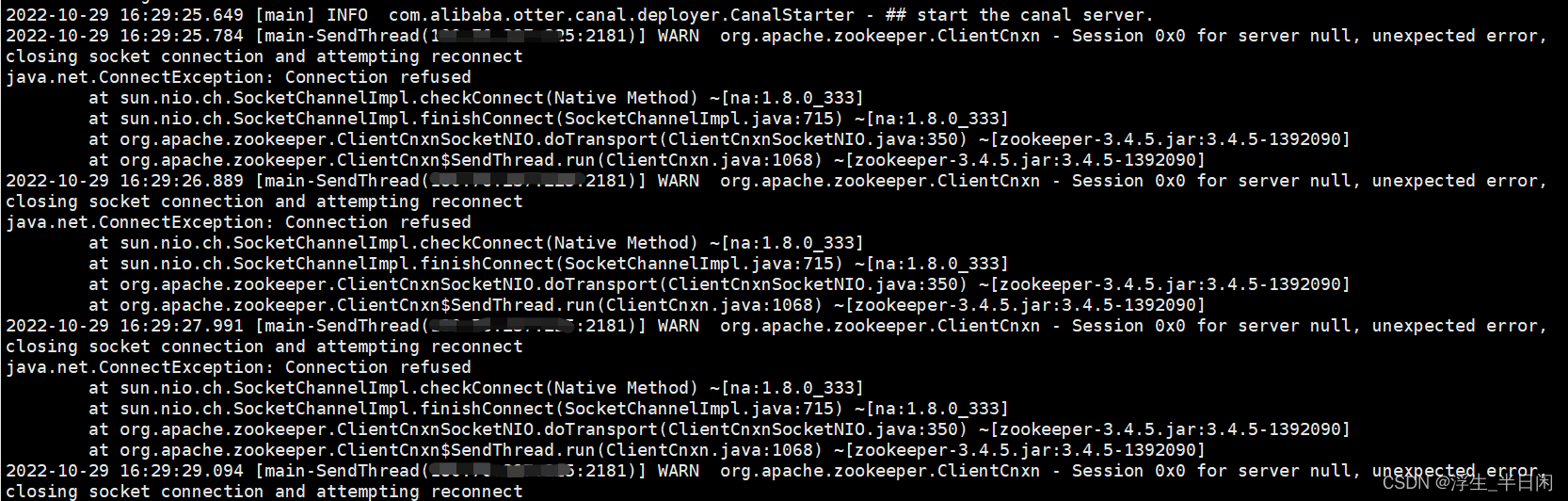
可以看到在连接Zookeeper时候出了问题,由于我的服务器刚重启了下,所以去重启下Zookeeper。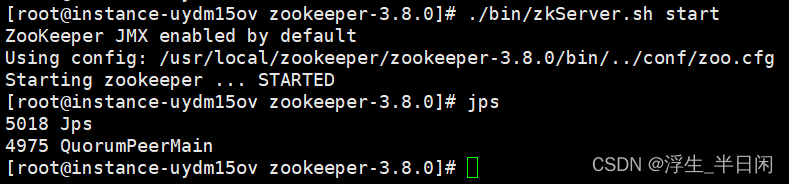
启动zookeeper后,再去重新启动下我们的Server。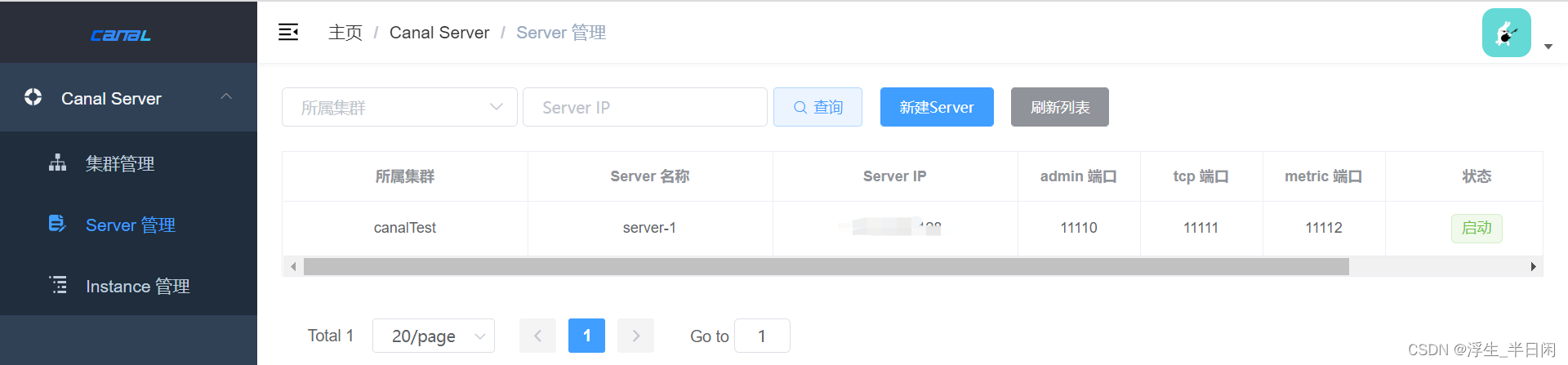
从上就可以看到我们的一个Server启动起来了,这时候我们在看下日志。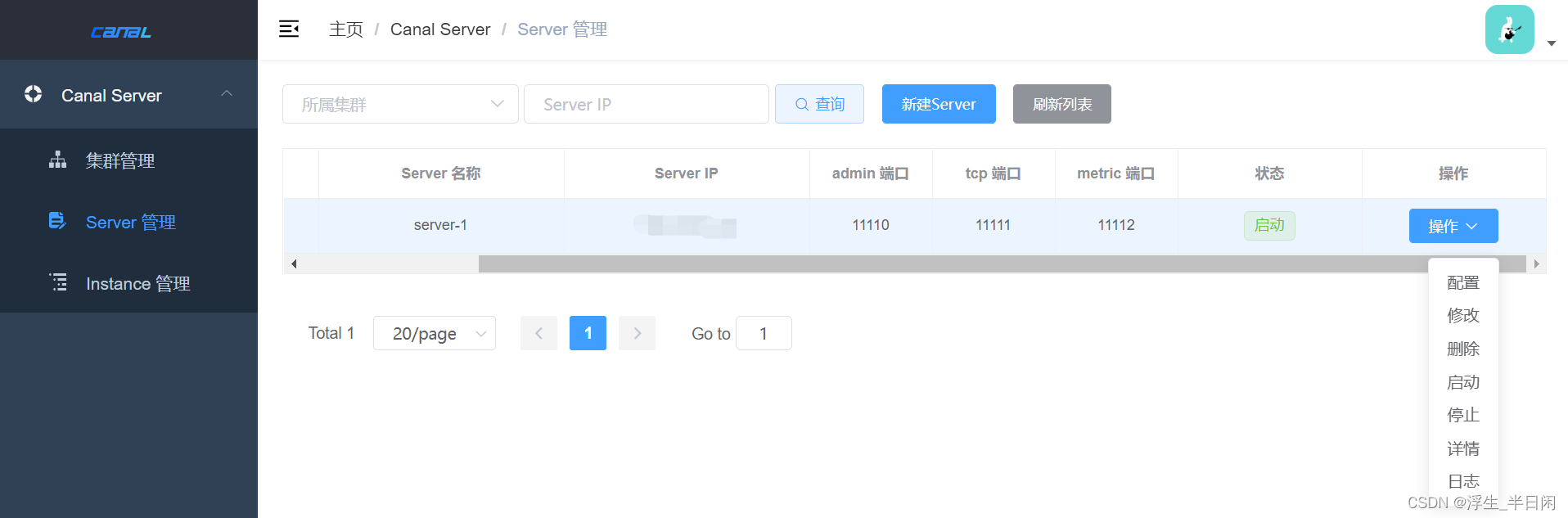
发现我们的kafaka链接不上,检查发现kafaka也需要启动: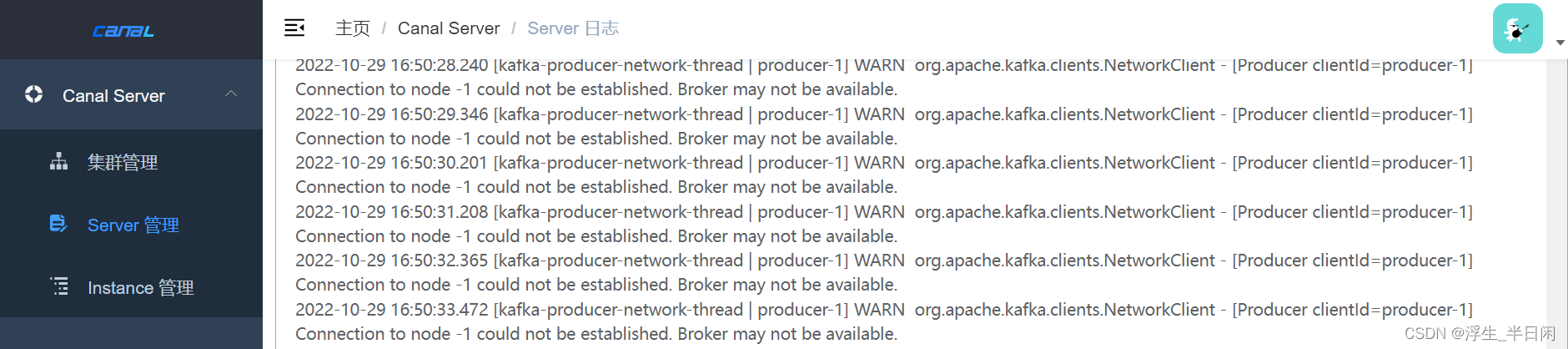
启动kafka
再去重启下Server
到此,我们的一个Server也已经启动了,一波三折。创建Instance,详细参考:Canal 架构解析水文,
接下来配置Instance
为了故事顺利进行,创建两个数据库canal_instance_1、canal_instance_2,再创建个user表,
Instance配置如下
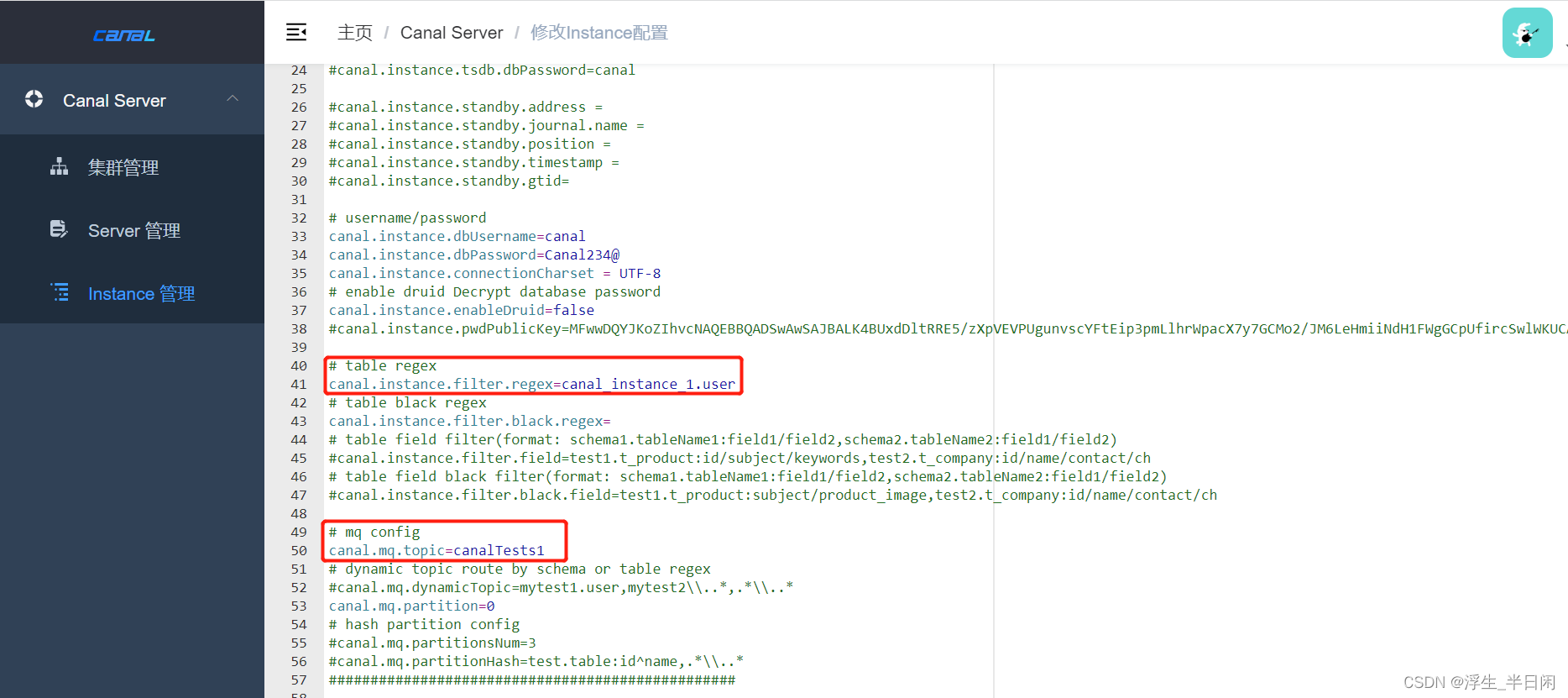
执行insert、update、delete语句 (canal.mq.flatMessage = true 模式下 canal.mq.flatMessage = false 模式暂不讨论)
INSERT INTO `canal_instance_1`.`user` (`id`, `user_name`, `gender`, `country_id`, `birthday`, `addr`, `create_time`) VALUES ('1', 'kkk', '18', '1', '2022-10-29', '北京市', '2022-10-29 17:42:29');
UPDATE `canal_instance_1`.`user` set addr='北京市朝阳区' WHERE id=1;
DELETE FROM `canal_instance_1`.`user` WHERE id=1;
启动消费者消费canalTests1队列,消费到的消息如下
[root@instance-uydm15ov kafka_2.12-2.1.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic canalTests1
{"data":[{"id":"1","user_name":"kkk","gender":"18","country_id":"1","birthday":"2022-10-29","addr":"北京市","create_time":"2022-10-29 17:42:29"}],"database":"canal_instance_1","es":1667037148000,"id":7,"isDdl":false,"mysqlType":{"id":"int(11)","user_name":"varchar(255)","gender":"tinyint(4)","country_id":"int(11)","birthday":"date","addr":"varchar(255)","create_time":"timestamp"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":4,"user_name":12,"gender":-6,"country_id":4,"birthday":91,"addr":12,"create_time":93},"table":"user","ts":1667037148598,"type":"INSERT"}
{"data":[{"id":"1","user_name":"kkk","gender":"18","country_id":"1","birthday":"2022-10-29","addr":"北京市朝阳区","create_time":"2022-10-29 17:42:29"}],"database":"canal_instance_1","es":1667037148000,"id":7,"isDdl":false,"mysqlType":{"id":"int(11)","user_name":"varchar(255)","gender":"tinyint(4)","country_id":"int(11)","birthday":"date","addr":"varchar(255)","create_time":"timestamp"},"old":[{"addr":"北京市"}],"pkNames":["id"],"sql":"","sqlType":{"id":4,"user_name":12,"gender":-6,"country_id":4,"birthday":91,"addr":12,"create_time":93},"table":"user","ts":1667037148598,"type":"UPDATE"}
{"data":[{"id":"1","user_name":"kkk","gender":"18","country_id":"1","birthday":"2022-10-29","addr":"北京市朝阳区","create_time":"2022-10-29 17:42:29"}],"database":"canal_instance_1","es":1667037148000,"id":7,"isDdl":false,"mysqlType":{"id":"int(11)","user_name":"varchar(255)","gender":"tinyint(4)","country_id":"int(11)","birthday":"date","addr":"varchar(255)","create_time":"timestamp"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":4,"user_name":12,"gender":-6,"country_id":4,"birthday":91,"addr":12,"create_time":93},"table":"user","ts":1667037148598,"type":"DELETE"}
消费端可以正常消费到,说明我们系统搭建前部分是成功的了,接下来就是编写Canal Client 客户端消费kafka队列的消息进行具体业务开发了,是对数据进行异构,还是仅仅是对分表数据进行聚合,这里我们是对数据进行聚合。
2.3 Kafka部署
略
2.4 Zookeeper部署
略
2.5 Canal Client部署
在整个数据同步项目中,工作量也主要在这块了,这个需要我们自己写了,也就是我们的应用项目了,需要从Kafka消费数据然后加工处理下存储到对应数据库表中。
源码中 example 模块也给出了很多demo,代码拿过来加工下。
在自己企业项目中是将消费处理逻辑封装为一个stater,因为数据同步了多个库,消费端也是多个项目,所以就封装为一个starter,以供项目中使用,避免了相同业务逻辑又是写很多份。对外提供了一个接口,具体项目实现接口进行数据存储就行了。
/**
* @author Kkk
*/
public interface EntryHandler<T> {
default void insert(T t) {}
default void update(T before, T after) {}
default void delete(T t) {}
}
具体实现的一种方式如下:
2.5.1 引入依赖
<dependency>
<groupId>com.kkk</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
2.5.2 实现接口
为了后期扩展我们使用jOOQ进行数据持久化,后期即使新增同步表也不会对代码进行修改。
/**
* @author Kkk
*/
@CanalTable
@Component
public class DefaultEntryHandler implements EntryHandler<Map<String, String>> {
@Resource
private DSLContext dsl;
private Logger logger = LoggerFactory.getLogger(DefaultEntryHandler.class);
@Override
public void insert(Map<String, String> map) {
logger.info("增加 {}", map);
String table = CanalContext.getModel().getTable();
List<Field<Object>> fields = map.keySet().stream().map(DSL::field).collect(Collectors.toList());
List<Param<String>> values = map.values().stream().map(DSL::value).collect(Collectors.toList());
int execute = dsl.insertInto(table(table)).columns(fields).values(values).execute();
logger.info("执行结果 {}", execute);
}
@Override
public void update(Map<String, String> before, Map<String, String> after) {
logger.info("修改 before {}", before);
logger.info("修改 after {}", after);
String table = CanalContext.getModel().getTable();
Map<Field<Object>, String> map = after.entrySet().stream().filter(entry -> before.containsKey(entry.getKey()))
.collect(Collectors.toMap(entry -> field(entry.getKey()), Map.Entry::getValue));
dsl.update(table(table)).set(map).where(field("id").eq(after.get("id"))).execute();
}
@Override
public void delete(Map<String, String> map) {
logger.info("删除 {}", map);
String table = CanalContext.getModel().getTable();
dsl.delete(table(table)).where(field("id").eq(map.get("id"))).execute();
}
}
只需要上面两步就完成了Canal Client 的编写了,然后启动应用:执行insert,我们可以看到
2022-10-29 18:31:47.968 INFO 79732 --- [l-client-thread] com.kkk.canal.client.KafkaCanalClient : 获取消息 [FlatMessage [id=3, database=canal_instance_1, table=user, isDdl=false, type=INSERT, es=1667039509000, ts=1667039509370, sql=, sqlType={birthday=91, gender=-6, create_time=93, user_name=12, id=4, addr=12, country_id=4}, mysqlType={birthday=date, gender=tinyint(4), create_time=timestamp, user_name=varchar(255), id=int(11), addr=varchar(255), country_id=int(11)}, data=[{birthday=2022-10-29, gender=18, create_time=2022-10-29 17:42:29, user_name=kkk, id=1, addr=北京市, country_id=1}], old=null]]
2022-10-29 18:31:47.968 INFO 79732 --- [l-client-thread] c.k.c.h.impl.AbstractFlatMessageHandler : 解析消息 FlatMessage [id=3, database=canal_instance_1, table=user, isDdl=false, type=INSERT, es=1667039509000, ts=1667039509370, sql=, sqlType={birthday=91, gender=-6, create_time=93, user_name=12, id=4, addr=12, country_id=4}, mysqlType={birthday=date, gender=tinyint(4), create_time=timestamp, user_name=varchar(255), id=int(11), addr=varchar(255), country_id=int(11)}, data=[{birthday=2022-10-29, gender=18, create_time=2022-10-29 17:42:29, user_name=kkk, id=1, addr=北京市, country_id=1}], old=null]
2022-10-29 18:31:47.968 INFO 79732 --- [l-client-thread] c.k.c.h.impl.AbstractFlatMessageHandler : 消息处理器 com.kkk.canal.study.handler.DefaultEntryHandler@60e3c26e
2022-10-29 18:31:47.968 INFO 79732 --- [l-client-thread] c.k.c.h.impl.AbstractFlatMessageHandler : 消息发送至行处理 [{birthday=2022-10-29, gender=18, create_time=2022-10-29 17:42:29, user_name=kkk, id=1, addr=北京市, country_id=1}] INSERT
2022-10-29 18:31:47.968 INFO 79732 --- [l-client-thread] c.k.c.h.impl.MapRowDataHandlerImpl : 处理消息 [{birthday=2022-10-29, gender=18, create_time=2022-10-29 17:42:29, user_name=kkk, id=1, addr=北京市, country_id=1}]
2022-10-29 18:31:47.968 INFO 79732 --- [l-client-thread] c.k.c.study.handler.DefaultEntryHandler : 增加 {birthday=2022-10-29, gender=18, create_time=2022-10-29 17:42:29, user_name=kkk, id=1, addr=北京市, country_id=1}
2022-10-29 18:31:47.995 INFO 79732 --- [l-client-thread] c.k.c.study.handler.DefaultEntryHandler : 执行结果 1
查看canal_instance_2库中user表,数据已经同步过来了。
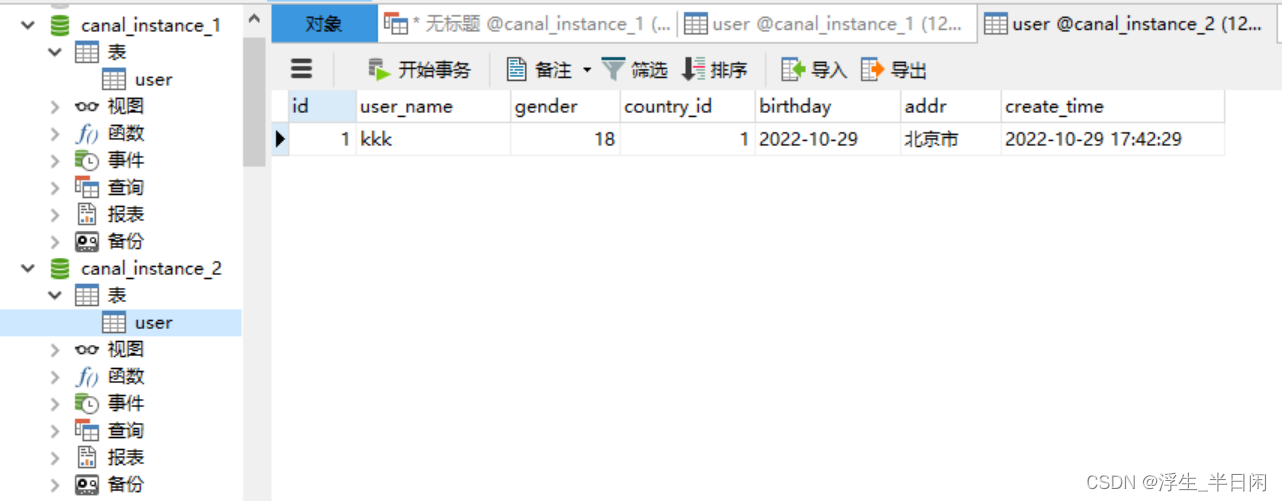
到此整体核心流程已经搭建完成了,对于多表聚合如:从canal_instance_1 库中表user_1、user_2…user_n—>canal_instance_2 库中user表,无非就是调整下配置,然后再client转换下要插入的表。
# table regex
canal.instance.filter.regex=canal_instance_1.user
具体规则匹配表达式见官网吧。
2.5.3 源码分析
扣下stater中核心处理代码如下:
@Override
public void handleMessage(FlatMessage flatMessage) {
log.info("解析消息 {}", flatMessage);
List<Map<String, String>> data = flatMessage.getData();
if (data != null && data.size() > 0) {
for (int i = 0; i < data.size(); i++) {
CanalEntry.EventType eventType = CanalEntry.EventType.valueOf(flatMessage.getType());
List<Map<String, String>> maps;
if (eventType.equals(CanalEntry.EventType.UPDATE)) {
Map<String, String> map = data.get(i);
Map<String, String> oldMap = flatMessage.getOld().get(i);
maps = Stream.of(map, oldMap).collect(Collectors.toList());
} else {
maps = Stream.of(data.get(i)).collect(Collectors.toList());
}
try {
log.info("消息处理器 {}", entryHandler);
if (entryHandler != null) {
CanalModel model = CanalModel.Builder.builder().id(flatMessage.getId()).table(flatMessage.getTable())
.executeTime(flatMessage.getEs()).database(flatMessage.getDatabase()).createTime(flatMessage.getTs()).build();
CanalContext.setModel(model);
log.info("消息发送至行处理 {} {}", maps, eventType);
rowDataHandler.handlerRowData(maps, entryHandler, eventType);
}
} catch (Exception e) {
log.error("消息处理异常 ", e);
throw new RuntimeException("parse event has an error , data:" + data.toString(), e);
} finally {
CanalContext.removeModel();
}
}
}
}
首先看下FlatMessage 对象:
public class FlatMessage implements Serializable {
private static final long serialVersionUID = -3386650678735860050L;
private long id;
private String database;
private String table;
private List<String> pkNames;
private Boolean isDdl;
private String type;
private Long es;
private Long ts;
private String sql;
private Map<String, Integer> sqlType;
private Map<String, String> mysqlType;
private List<Map<String, String>> data;
private List<Map<String, String>> old;
.... ....
}
类FlatMessage中属性每个什么意思,最直观的就看下我们从kafaka消费到的数据长什么样子。
{
"data": [{
"id": "1",
"user_name": "kkk",
"gender": "18",
"country_id": "1",
"birthday": "2022-10-29",
"addr": "北京市",
"create_time": "2022-10-29 17:42:29"
}],
"database": "canal_instance_1",
"es": 1667037148000,
"id": 7,
"isDdl": false,
"mysqlType": {
"id": "int(11)",
"user_name": "varchar(255)",
"gender": "tinyint(4)",
"country_id": "int(11)",
"birthday": "date",
"addr": "varchar(255)",
"create_time": "timestamp"
},
"old": null,
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": 4,
"user_name": 12,
"gender": -6,
"country_id": 4,
"birthday": 91,
"addr": 12,
"create_time": 93
},
"table": "user",
"ts": 1667037148598,
"type": "INSERT"
}
属性解析:
private List<Map<String, String>> data;
data属性为甚是List?对于我们上面的insert操作,可以看到list
.size()=0,在代码中也是循环处理的,是为了我们批量操作数据,如下sql的FlatMessage是什么样的。
INSERT INTO `canal_instance_1`.`user` (`id`, `user_name`, `gender`, `country_id`, `birthday`, `addr`, `create_time`) VALUES ('1', 'kkk', '18', '1', '2022-10-29', '北京市', '2022-10-29 17:42:29'),('2', 'yyy', '20', '1', '2022-10-29', '北京市', '2022-10-29 17:42:29');
{
"data": [{
"id": "1",
"user_name": "kkk",
"gender": "18",
"country_id": "1",
"birthday": "2022-10-29",
"addr": "北京市",
"create_time": "2022-10-29 17:42:29"
}, {
"id": "2",
"user_name": "yyy",
"gender": "20",
"country_id": "1",
"birthday": "2022-10-29",
"addr": "北京市",
"create_time": "2022-10-29 17:42:29"
}],
"database": "canal_instance_1",
"es": 1667041473000,
"id": 13,
"isDdl": false,
"mysqlType": {
"id": "int(11)",
"user_name": "varchar(255)",
"gender": "tinyint(4)",
"country_id": "int(11)",
"birthday": "date",
"addr": "varchar(255)",
"create_time": "timestamp"
},
"old": null,
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": 4,
"user_name": 12,
"gender": -6,
"country_id": 4,
"birthday": 91,
"addr": 12,
"create_time": 93
},
"table": "user",
"ts": 1667041473647,
"type": "INSERT"
}
可以看到List.size()=2了,所以在handleMessage进行for循环处理,当我们执行如下sql时候看下有什么不同。
UPDATE `canal_instance_1`.`user` set addr='北京市朝阳区' WHERE id in (1,2);
FlatMessage如下:
{
"data": [{
"id": "1",
"user_name": "kkk",
"gender": "18",
"country_id": "1",
"birthday": "2022-10-29",
"addr": "北京市朝阳区",
"create_time": "2022-10-29 17:42:29"
}, {
"id": "2",
"user_name": "yyy",
"gender": "20",
"country_id": "1",
"birthday": "2022-10-29",
"addr": "北京市朝阳区",
"create_time": "2022-10-29 17:42:29"
}],
"database": "canal_instance_1",
"es": 1667041936000,
"id": 14,
"isDdl": false,
"mysqlType": {
"id": "int(11)",
"user_name": "varchar(255)",
"gender": "tinyint(4)",
"country_id": "int(11)",
"birthday": "date",
"addr": "varchar(255)",
"create_time": "timestamp"
},
"old": [{
"addr": "北京市"
}, {
"addr": "北京市"
}],
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": 4,
"user_name": 12,
"gender": -6,
"country_id": 4,
"birthday": 91,
"addr": 12,
"create_time": 93
},
"table": "user",
"ts": 1667041936930,
"type": "UPDATE"
}
从上可以看到old的size()=2了,这也验证了我么处理代码逻辑为什么要这么写了,其他的也没啥好介绍的了。
3.踩到的坑
3.1 column size is not match
这个是踩到的第一个坑,还好是在测试环境先踩到的,赶紧到生产环境禁用tsdb功能。
canal.instance.tsdb.enable=false
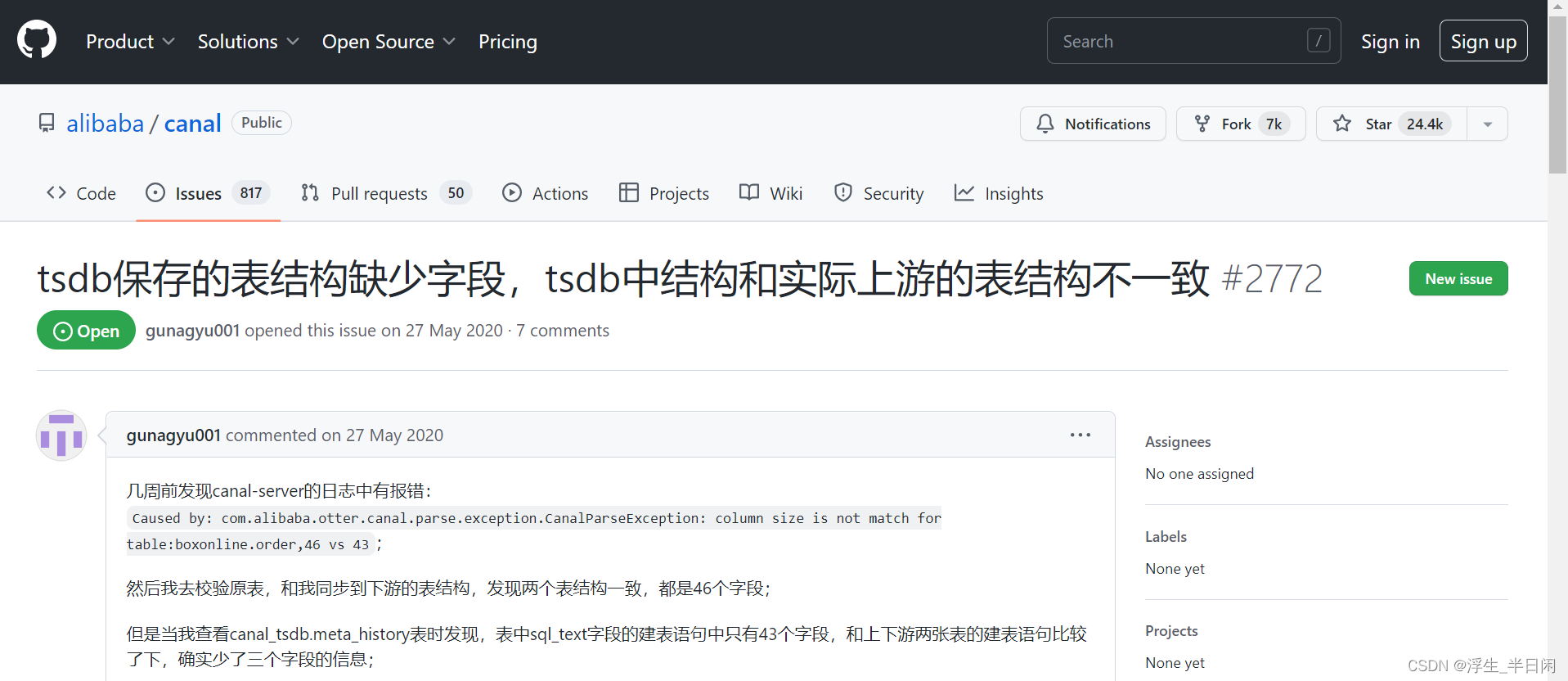
很多使用者都踩到过此雷,并且还是很严重的问题,想重现此问题,但是修改了上游表结构后还是没有触发这个问题,让人很郁闷,看来需要扒下源码了。
关于TableMetaTSDB设计思想参考:https://github.com/alibaba/canal/wiki/TableMetaTSDB
3.2 todo
总结
做个使用总结吧~~