课程介绍
•Python语言基础及Python3.x新特性
•使用NumPy和SciPy进行科学计算
•数据分析建模理论基础
•实战案例:科技工作者心理健康数据分析
什么是数据分析?
Analysis of data is a process of inspecting, cleansing, transforming, and modelingdata with the goal of discovering useful information, suggesting conclusions, and supporting decision-making.
Jupyter notebook
- Anaconda自带,无需单独安装
- 记录思考过程,实时查看运行过程
- 基于web的在线编辑器(本地)
- .ipynb文件分享
- 可交互式
- 记录历史运行结果
- 支持Markdown, Latex
使用NumPy和SciPy进行科学计算:
NumPy
•高性能科学计算和数据分析的基础包
•ndarray,多维数组(矩阵),具有矢量运算能力,快速、节省空间
•矩阵运算,无需循环,可完成类似Matlab中的矢量运算
•线性代数、随机数生成
•import numpyas np
SciPy
•在NumPy库的基础上增加了众多的数学、科学及工程常用的库函数
•线性代数、常微分方程求解、信号处理、图像处理、稀疏矩阵等
•import scipyas sp
生成多维数组:
1> data=np.arange(12).reshape(3,4)
2> data1=np.random.rand(3,3)
3> data=np.random.randn(3,3)
4> #list嵌套序列转换为ndarray
l2=[range(10),range(10)]
data2=np.array(l2)
5> data3=np.array([[1,2,3],
[4,5,6]])
数据分析建模理论基础
建模基础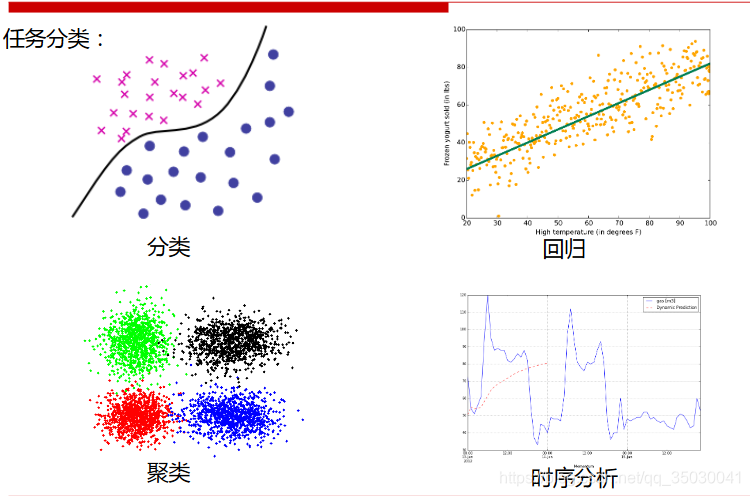
分类与回归
•应用:信用卡申请人风险评估、预测公司业务增长量、预测房价等
•原理:
分类,将数据映射到预先定义的群组或类。算法要求基于数据属性值(特征值)来定义类别,把具有某些特征的数据项映射到给定的某个类别上。
回归,用属性的历史数据预测未来趋势。算法首先假设一些已知类型的函数可以拟合目标数据,然后利用某种误差分析确定一个与目标数据拟合程度最好的函数。
•区别:分类模型采用离散预测值,回归模型采用连续的预测值。
聚类
•应用:根据症状归纳特定疾病、发现信用卡高级用户、根据上网行为对客户分群从而进行精确营销等
•原理:在没有给定划分类的情况下,根据信息相似度进行信息聚类。
聚类的输入是一组未被标记的数据,根据样本特征的距离或相似度进行划分。划分原则是保持最大的组内相似性和最小的组间相似性。
时序模型
•应用:
下个季度的商品销量或库存量是多少?明天用电量是多少?
•原理:
描述基于时间或其他序列的经常发生的规律或趋势,并对其建模。
与回归一样,用已知的数据预测未来的值,但这些数据的区别是变量所处时间的不同。重点考察数据之间在时间维度上的关联性。
•实战案例:科技工作者心理健康数据分析
项目任务:
统计各国家男性、女性心理健康数据分布
# -*- coding: utf-8 -*-
"""
项目名称:科技工作者心理健康数据分析 (Mental Health in Tech Survey)
项目任务:统计各国家男性、女性心理健康数据分布
"""
import csv
# 数据集路径
data_path = './survey.csv'
def run_main():
"""
主函数
"""
male_set = {'male', 'm'} # “男性”可能的取值
female_set = {'female', 'f'} # “女性”可能的取值
# 构造统计结果的数据结构 result_dict
# 其中每个元素是键值对,“键”是国家名称,“值”是列表结构,
# 列表的第一个数为该国家女性统计数据,第二个数为该国家男性统计数据
# 如 {'United States': [20, 50], 'Canada': [30, 40]}
# 思考:这里的“值”为什么用列表(list)而不用元组(tuple)
result_dict = {}
with open(data_path, 'r', newline='') as csvfile:
# 加载数据
rows = csv.reader(csvfile)
for i, row in enumerate(rows): #enumerate可以拿到循环的次数,返回一个元组(i,data)
if i == 0:
# 跳过第一行表头数据
continue
if i % 50 == 0:
print('正在处理第{}行数据...'.format(i))
# 性别,国家数据
gender_val = row[2]
country_val = row[3]
# 去掉可能存在的空格
gender_val = gender_val.replace(' ', '')
# 转换为小写
gender_val = gender_val.lower()
# 判断“国家”是否已经存在
if country_val not in result_dict:
# 如果不存在,初始化数据
result_dict[country_val] = [0, 0] #往字典里加入新的键值对
# 判断性别
if gender_val in female_set:
# 女性
result_dict[country_val][0] += 1 #字典操作
elif gender_val in male_set:
# 男性
result_dict[country_val][1] += 1
else:
# 噪声数据,不做处理
pass
# 将结果写入文件
with open('gender_country.csv', 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',') #自定义分隔符
# 写入表头
csvwriter.writerow(['国家', '男性', '女性'])
# 写入统计结果
for k, v in list(result_dict.items()):
csvwriter.writerow([k, v[0], v[1]])
if __name__ == '__main__':
run_main()