使用Structured Streaming处理数据的知识积累。
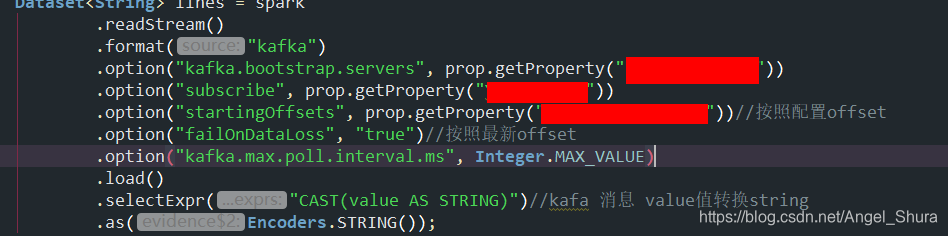
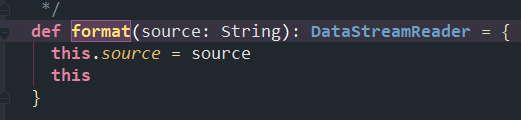
1、Structured Streaming 在做读取数据的时候,format()首先会判断加载的数据源是什么(Kafka、MySQL ···),
2、读取Kafka数据的时候,KafkaSourceProvider 类中的createMicroBatchReader 函数体中有对option() 中设置的Kafka参数进行校验及设置默认参数,
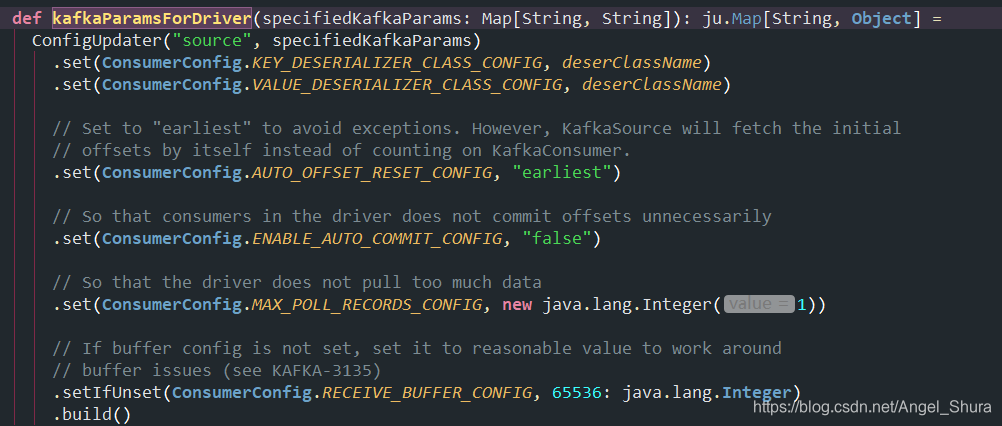
对必填参数duisubscribe,startingOffsets,failOnDataLoss进行判断。![]()
3、如果要对默认参数进行修改或者添加新的配置,通过 option("Kafka.xx","") 进行设置。由于在KafkaSourceProvider 类对Kafka设置的参数做了过滤处理 因此,设置Kafka参数时,必须以kafka. 前缀开始

切记!不是所有的Kafka参数都可以设置!
Kafka特定配置
Kafka自己的配置可以通过设置DataStreamReader.option与kafka.前缀,例如 stream.option("kafka.bootstrap.servers", "host:port")。有关可能的kafka参数,请参阅 Kafka使用者配置文档以获取与读取数据相关的参数,以及Kafka生产者配置文档 以获取与写入数据相关的参数。
请注意,无法设置以下Kafka参数,并且Kafka源或接收器将引发异常:
- group.id:Kafka源将自动为每个查询创建一个唯一的组ID。
- auto.offset.reset:设置源选项
startingOffsets以指定从何处开始。结构化流管理在内部管理哪些偏移量,而不是依靠kafka使用者来执行此操作。这将确保在动态订阅新主题/分区时不会丢失任何数据。请注意,startingOffsets仅在启动新的流查询时适用,并且恢复将始终从查询中断的地方开始。 - key.deserializer:始终使用ByteArrayDeserializer将键反序列化为字节数组。使用DataFrame操作显式反序列化键。
- value.deserializer:始终使用ByteArrayDeserializer将值反序列化为字节数组。使用DataFrame操作显式反序列化值。
- key.serializer:密钥始终使用ByteArraySerializer或StringSerializer进行序列化。使用DataFrame操作可以将键显式序列化为字符串或字节数组。
- value.serializer:值始终使用ByteArraySerializer或StringSerializer进行序列化。使用DataFrame操作可以将值显式序列化为字符串或字节数组。
- enable.auto.commit:Kafka源不提交任何偏移量。
- Interceptor.classes:Kafka源始终将键和值读取为字节数组。使用ConsumerInterceptor是不安全的,因为它可能会中断查询。
版权声明:本文为Angel_Shura原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。