介绍
前面几个章节对Druid的整体架构做了简单的说明,本文主要描述如何部署Druid的环境
Imply提供了一套完整的部署方式,包括依赖库,Druid,图形化的数据展示页面,SQL查询组件等。本文将基于Imply套件进行说明
单机部署
依赖
- Java 8 or better
- Node.js 4.5.x or better
- Linux, Mac OS X, or other Unix-like OS (Windows is not supported)
- At least 4GB of RAM
下载与安装
- 从https://imply.io/get-started 下载最新版本安装包
- tar -xzf imply-2.3.9.tar.gz
- cd imply-2.3.9
目录说明如下:
- bin/ - run scripts for included software.
- conf/ - template configurations for a clustered setup.
- conf-quickstart/* - configurations for the single-machine quickstart.
- dist/ - all included software.
- quickstart/ - files related to the single-machine quickstart.
启动服务
bin/supervise -c conf/supervise/quickstart.conf安装验证
导入测试数据
安装包中包含一些测试的数据,可以通过执行预先定义好的数据说明文件进行导入
bin/post-index-task --file quickstart/wikiticker-index.json可视化控制台
- overlord 控制页面:http://localhost:8090/console.html.
- druid集群页面:http://localhost:8081
- 数据可视化页面:http://localhost:9095
数据展示与查询
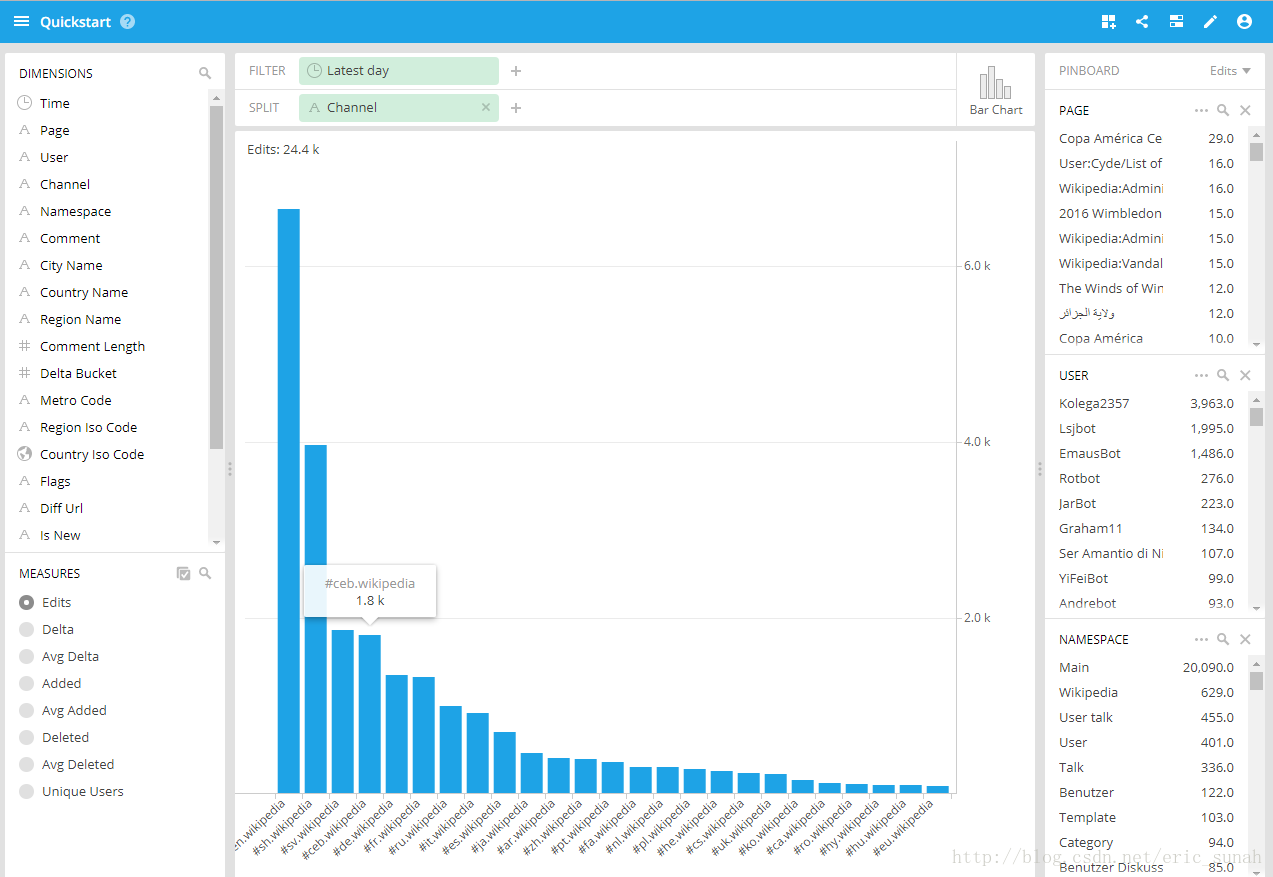
- 数据展示:对渠道进行统计的柱状图
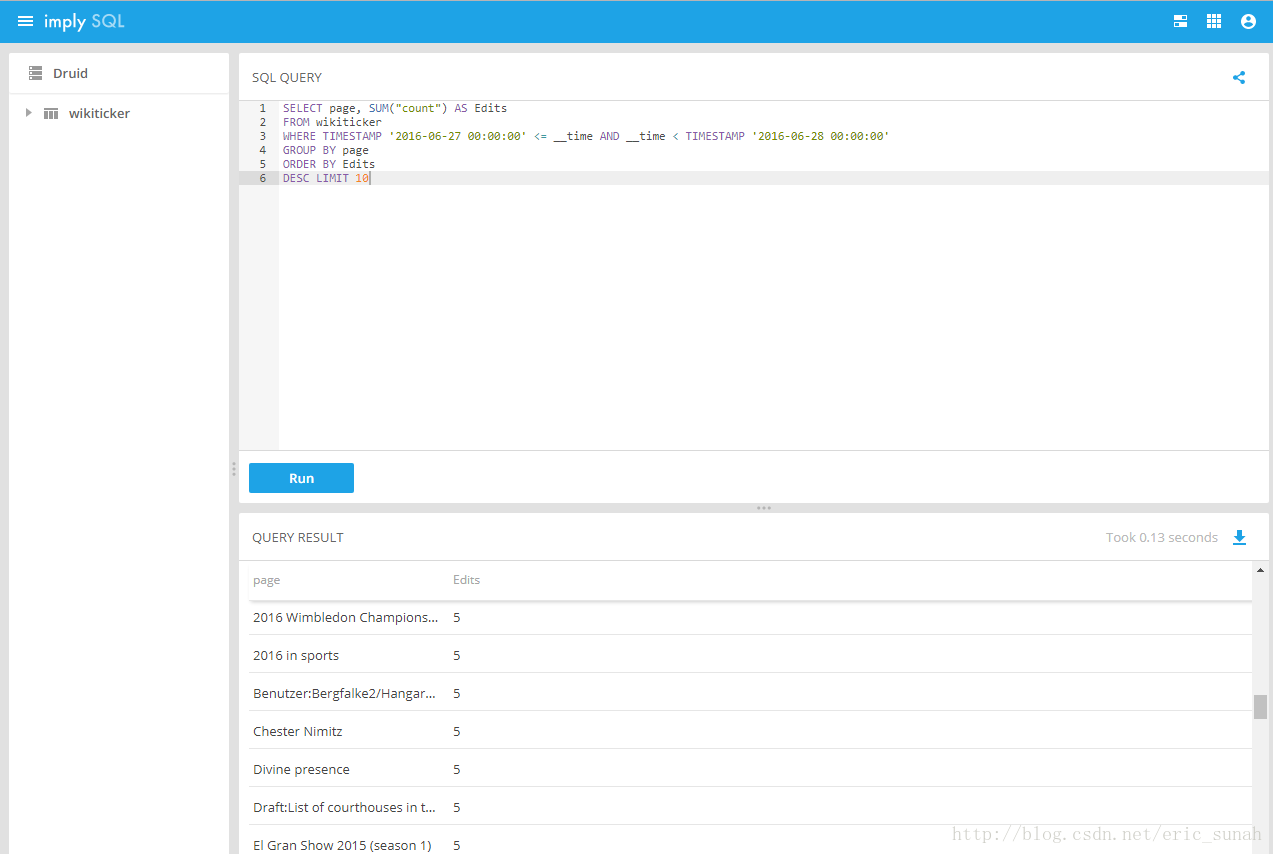
- SQL数据查询:使用sql查询编辑次数最多的10个page
- HTTP POST数据查询
命令:curl -L -H’Content-Type: application/json’ -XPOST –data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2?pretty
结果:
[ {
"timestamp" : "2016-06-27T00:00:11.080Z",
"result" : [ {
"edits" : 29,
"page" : "Copa América Centenario"
}, {
"edits" : 16,
"page" : "User:Cyde/List of candidates for speedy deletion/Subpage"
},
..........
{
"edits" : 8,
"page" : "World Deaf Championships"
} ]
} ]集群部署
集群配置的规划需要根据需求来定制,下面以一个开发环境机器搭建为例,描述如何搭建一个有HA特性的Druid集群.
集群部署有以下几点需要说明
1. 为了保证HA,主节点部署两台
2. 管理节点与查询节点可以考虑多核大内存的机器
部署规划
| 角色 | 机器 | 配置 | 集群角色 |
|---|---|---|---|
| 主节点 | 10.5.24.137 | 8C16G | Coordinator,Overlord |
| 主节点 | 10.5.24.138 | 8C16G | Coordinator,Overlord |
| 数据节点,查询节点 | 10.5.24.139 | 8C16G | Historical, MiddleManager, Tranquility,Broker,Pivot Web |
| 数据节点,查询节点 | 10.5.24.140 | 8C16G | Historical, MiddleManager, Tranquility,(数据节点,查询节点)Broker |
部署步骤
公共配置
编辑conf/druid/_common/common.runtime.properties 文件内容
1. loadList配置:==此处需要统一在一个位置统一定义,否则会出现extension加载的问题==
druid.extensions.loadList=["mysql-metadata-storage","druid-hdfs-storage"]- Zookeeper
#
# Zookeeper
#
druid.zk.service.host=native-lufanfeng-2-5-24-138:2181,native-lufanfeng-3-5-24-139:2181,native-lufanfeng-4-5-24-140:2181
druid.zk.paths.base=/druid
- MetaData:使用Mysql
# For MySQL:
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://10.5.24.151:3306/druid
druid.metadata.storage.connector.user=root
druid.metadata.storage.connector.password=123456- Deepstorage:使用HDFS
#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
druid.storage.type=hdfs
druid.storage.storageDirectory=hdfs://10.5.24.137:9000/druid/segments
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=hdfs://10.5.24.137:9000/druid/indexing-logs
主节点配置
- 创建配置文件:cp conf/supervise/master-no-zk.conf conf/supervise/master.conf
- 编辑master.conf 内容如下:
:verify bin/verify-java
:verify bin/verify-version-check
coordinator bin/run-druid coordinator conf
!p80 overlord bin/run-druid overlord conf
- 目前的版本中,mysql-metadata-storage没有包含在默认的安装包中,如果使用mysql存储元数据,需要单独安装下对应的扩展,是用下列命令在两个master节点上对需要用到的扩展进行安装:
root@native-lufanfeng-1-5-24-137:~/imply-2.3.8# java -classpath "dist/druid/lib/*" -Ddruid.extensions.directory="dist/druid/extensions" io.druid.cli.Main tools pull-deps -c io.druid.extensions:mysql-metadata-storage:0.10.1 -c io.druid.extensions.contrib:druid-rabbitmq:0.10.1 -h org.apache.hadoop:hadoop-client:2.7.0==默认mysql-metadata-storage带的mysql驱动是针对Mysql 5.1的,如果使用Mysql的版本是5.5 或是其他版本,可能会出现”Communications link failure”的错误,此时需要更新Mysql的驱动。==
- 在10.5.24.137/138上启动master相关服务:nohup bin/supervise -c conf/supervise/master.conf > master.log &
数据节点与查询节点配置
- 安装NodeJS:apt-get install nodejs
- 创建配置文件:vim conf/supervise/data-with-query.conf
- 编辑data-with-query.conf 内容如下:
:verify bin/verify-java
:verify bin/verify-node
:verify bin/verify-version-check
broker bin/run-druid broker conf
imply-ui bin/run-imply-ui conf
historical bin/run-druid historical conf
middleManager bin/run-druid middleManager conf
# Uncomment to use Tranquility Server
#!p95 tranquility-server bin/tranquility server -configFile conf/tranquility/server.json
# Uncomment to use Tranquility Kafka
#!p95 tranquility-kafka bin/tranquility kafka -configFile conf/tranquility/kafka.json
- 对于集群模式,pivot的配置文件必须调整为mysql,sqllite会导致无法查看datasource,修改conf/pivot/config.xml文件
settingsLocation:
location: mysql
uri: 'mysql://root:123456@10.5.24.151:3306/druid'
table: 'pivot_state'
initialSettings:
clusters:
- name: druid
type: druid
host: localhost:8082
- 在10.5.24.139/140两台机器上分别执行:nohup bin/supervise -c conf/supervise/data-with-query.conf > data-with-query.log &
验证
可视化控制台
- overlord 控制页面:http://10.5.24.138:8090/console.html.
- druid集群页面:http://10.5.24.138:8081
- 数据可视化页面:http://10.5.24.139:9095