技术背景
GraphQL主要解决了复杂多变的业务场景下BFF层进行数据聚合的问题,GraphQL作为查询引擎解决包含了元数据的定义,数据层的查询与编排,元数据驱动的DSL API查询等问题。对于前端来说,可以自助取数进行数据映射;对于服务端而言,以实体与字段的形式进行数据服务的复用。
举一个例子,当运营需要搭建一个活动页面的时候,传统的开发模式如下,这种开发模式在出现几百几千的类似需求的场景,数据服务跨度大的时候,明显人力不能支撑并且API的生命周期非常短,业务代码复用度低。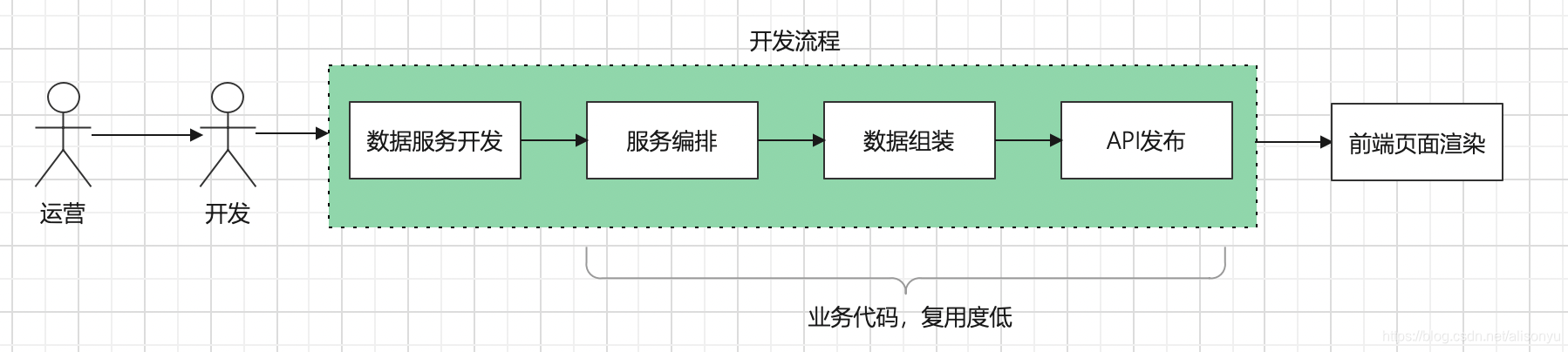
如果使用GraphQL构建数据服务,会发现将服务编排,组装等数据都统一下沉到GraphQL层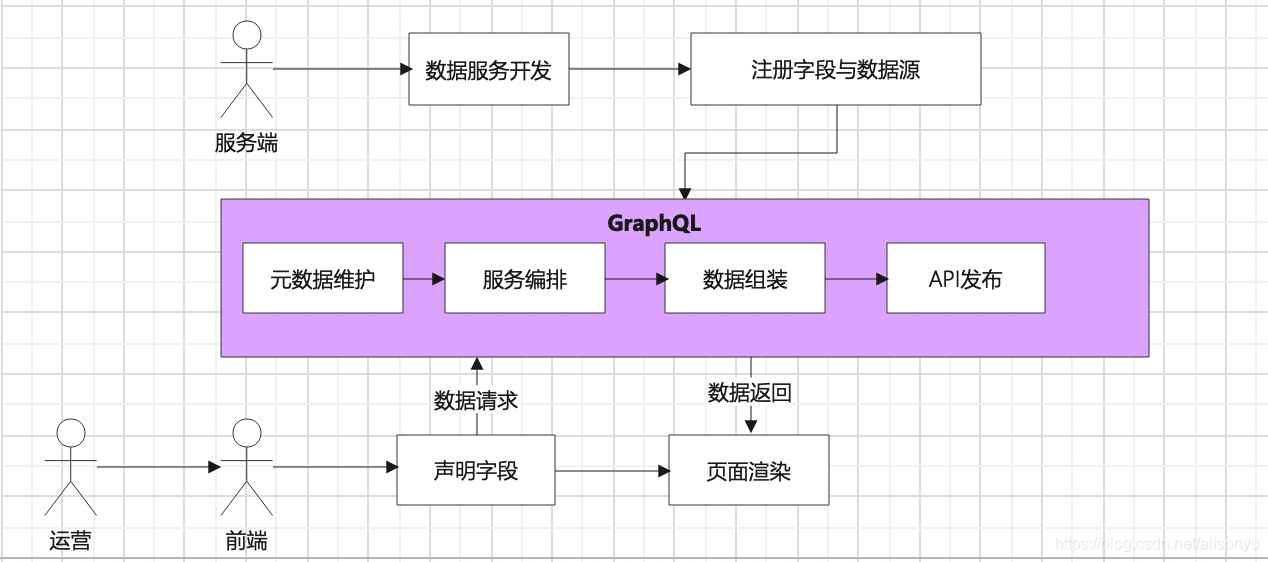
而只维护领域数据模型,对业务开发而言能够专注核心领域模型与能力的设计。
QuickStart
maven依赖
<dependencies>
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId>graphql-java</artifactId>
<version>16.2</version>
</dependency>
</dependencies>
基本概念
type : GraphQL对象类型,描述一个GraphQL领域中的对象,类似Java中的class
field : GraphQL字段,被对象所聚合,每个字段有类型以及数据获取器DataFetcher
query: GraphQL操作类型,表示查询操作,持有GraphQL query查询对象
schema: GraphQL类型系统,持有query,mutatioin等操作类型对象
dataFetcher: 数据获取器,作用在每个字段类型
对象关系如下: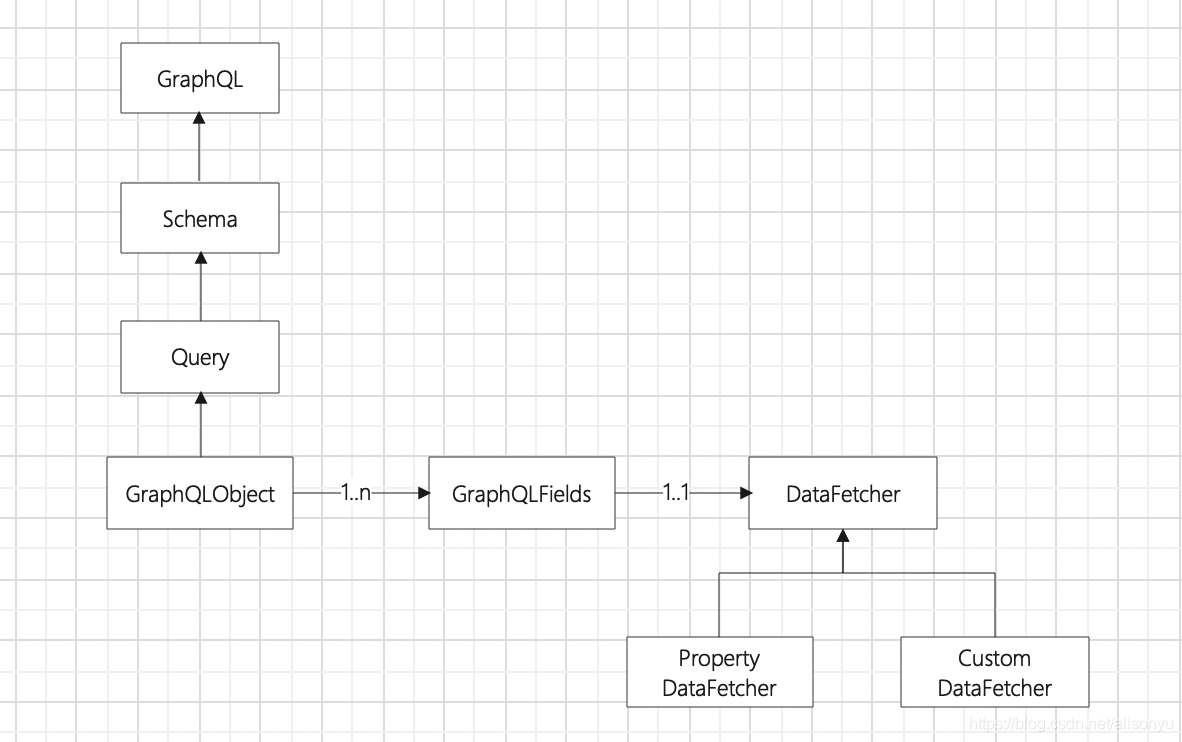
代码
以Movie对象进行举例
定义数据类
public class MovieVO {
private Long id;
private String name;
private Long publishTime;
// getter and setter....
}
定义数据服务
public class MovieRepositoryImpl implements MovieRepository{
@Override
public MovieVO queryById(Long id) {
MovieVO mockMovieVO = new MovieVO();
mockMovieVO.setId(id);
mockMovieVO.setName("movie_"+id);
mockMovieVO.setPublishTime(0L);
return mockMovieVO;
}
@Override
public List<MovieVO> batchQueryByIds(List<Long> ids) {
List<MovieVO> resultList = new ArrayList<>(ids.size());
for (Long id : ids){
resultList.add(queryById(id));
}
return resultList;
}
}
构建DataFetcher
构建iGraph系统的DataFetcher
public class BatchMovieDataFetcher implements BatchedDataFetcher<List<MovieVO>> {
private Logger logger = LoggerFactory.getLogger(BatchMovieDataFetcher.class);
@Override
public List<MovieVO> get(DataFetchingEnvironment environment) throws Exception {
List<String> idList = environment.getArgument("ids");
logger.info("BatchMovieDataFetcher|get|ids:{}",idList);
List<Long> ids = idList.stream().map(Long::valueOf).collect(Collectors.toList());
return ServiceFactory.getInstance().getMovieRepository().batchQueryByIds(ids);
}
}
定义Schema
使用Java代码动态构建schema
public class MovieObjectSchemaDefinition {
public static GraphQLObjectType getSchema(){
return GraphQLObjectType.newObject()
.name("movie")
.field(GraphQLFieldDefinition.newFieldDefinition()
.name("id")
.type(Scalars.GraphQLInt)
.build())
.field(GraphQLFieldDefinition.newFieldDefinition()
.name("name")
.type(Scalars.GraphQLString)
.build())
.field(GraphQLFieldDefinition.newFieldDefinition()
.name("publishTime")
.type(Scalars.GraphQLLong)
.build())
.build();
}
}
绑定数据源与构建GraphQL
public class MovieGraphQLFactory {
public GraphQL buildMovieQueryGraphQL(){
/* Query操作定义 **/
GraphQLObjectType movieQueryType = GraphQLObjectType.newObject()
.name("query")
.field(GraphQLFieldDefinition.newFieldDefinition()
.name("movies")
.type(GraphQLList.list(MovieObjectSchemaDefinition.getSchema()))
.argument(GraphQLArgument.newArgument()
.name("ids")
.type(GraphQLList.list(Scalars.GraphQLString))
.build())
.build()
)
.build();
/* 数据源绑定 **/
GraphQLCodeRegistry registry = GraphQLCodeRegistry.newCodeRegistry()
.dataFetcher(
FieldCoordinates.coordinates("query", "movies"),
ServiceFactory.getInstance().getBatchMovieDataFetcher()
)
.build();
/* 定义schema **/
GraphQLSchema schema = GraphQLSchema.newSchema()
/* 定义query schema **/
.query(movieQueryType)
/* 定义数据源绑定信息 **/
.codeRegistry(registry)
.build();
/* 构建graphQL实例 **/
GraphQL graphQL = GraphQL.newGraphQL(schema).build();
return graphQL;
}
}
发起查询
public static void main(String[] args) {
/* 构建graphQL实例 **/
MovieGraphQLFactory movieGraphQLFactory = new MovieGraphQLFactory();
GraphQL graphQL = movieGraphQLFactory.buildMovieQueryGraphQL();
String query = buildQuery("movies", Lists.newArrayList("1","2"),Lists.newArrayList("name"));
/* 执行查询 **/
ExecutionInput executionInput = ExecutionInput.newExecutionInput().query(query).build();
ExecutionResult result = graphQL.execute(executionInput);
/* 返回数据 **/
Object data = result.getData();
System.out.println(data);
System.out.println(result.getErrors());
}
public static String buildQuery(String entityType, List<String> ids,List<String> fields){
String params = String.format("ids:[%s]", ids.stream().map(it -> "\"" + it + "\"").collect(Collectors.joining(",")));
String fieldsStr = String.format("%s", String.join(",",fields));
String query = String.format("query{ %s(%s){%s} }", entityType,params,fieldsStr);
return query;
}
感想
本文记录于GraphQL探讨过程中,发现其技术概念于复杂度还是相当高的,因此GraphQL还是适合复杂组织的项目;GraphQL作为数据的查询引擎,有些技术的优化必须深入了解GraphQL的执行机制和原理,在这一点性能优化的难易性比手写较低。
真正工程化需要将GraphQL那套下层封装,对于业务开发而言最好只需要了解到需要提供什么字段与数据服务,不需要实现复杂的配置构建与匹配,可以参考springboot对GraphQL的封装。GraphQL本身复杂度问题,需要更上层进行封装,具体看[2]美团的实践。
参考文档
[1] graphQL文档:https://graphql.cn/learn/queries/#operation-name
[2] GraphQL及元数据驱动架构在后端BFF中的实践 - 美团技术团队的文章 - 知乎
https://zhuanlan.zhihu.com/p/370436576
[3] GraphQL java工程化实践
https://segmentfault.com/a/1190000014829295