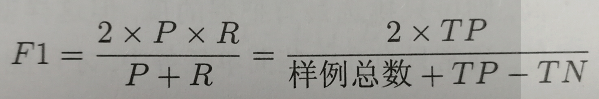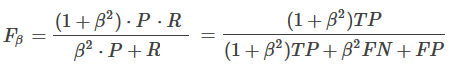一、混淆矩阵 二、错误率、正确率 三、精确度、召回率 四、F1值 五、P-R曲线 六、ROC曲线
参考:https://www.jianshu.com/p/82903edb58dc //这篇文章写的不错,除了F1值那个地方有错误。 https://www.cnblogs.com/gczr/p/10137063.html //ROC和PR怎么选择 https://www.cnblogs.com/xuexuefirst/p/8858274.html 西瓜书
评价一个二分类模型好坏,可以使用以下指标: 1. 错误率(正确率) 2. 精确度 3. 召回率 4. F1值 5. P-R曲线 6. ROC曲线
一、混淆矩阵
二、正确率、错误率 Accuracy(正确率、准确率) = 分对的概率 = (TP+TN)/(TP+TN+FP+FN) Error(错误率) = 分错的概率 = (FP+FN)/(TP+TN+FP+FN)
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如预测地震,将所有的情况都预测为不地震,那么准确率也很高。因为这里数据分布不均衡。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
三、精确度、召回率 precision(精确度、查准率) = 预测为正的样本中有多少实际为正 = TP/(TP+FP) //挑出来的好西瓜中到底有多少是好的? Recall(召回率、查全率) = 实际为正的样本中有多少预测为正 = TP/(TP+FN) //好的西瓜挑出来了多少?
说明: 1. 在西瓜书里面,把accuracy翻译成精度;把precision翻译成:查准率、准确率。我认为是错误的。 2. 在以后,我尽量使用英语来说,避免歧义。
四、F1值
查准率和查全率是一对矛盾的度量。往往一个高另一个就低。 1. 要提高挑西瓜的查全率,也就是尽量把所有的好西瓜都挑出来,那怎么挑?当然是挑西瓜的标准低一点,看到一个西瓜还没烂就行了,差不多就行,能吃就行。这样就基本把好西瓜都挑出来了。同时,挑出来的西瓜里面有很多不怎么样的,导致查准率低了。换句话说就是:宁可错挑一千,也不漏掉一个。 2. 要提高挑西瓜的查准率,也就是挑出来的西瓜基本都是好瓜,怎么挑?当然是提高标准,仔细挑选,颜色好看,花纹好看,一个虫子也没有,还得尝尝,确实是好瓜才挑出来。这样就能保证只要我挑的个个都是好瓜,查准率相当高。但是,本来呢是好瓜的,就因为长的丑的点,就没挑上。。。导致查全率就不怎么高了。换句话说就是:宁缺毋滥。
只考虑P或者只考虑R都不行,我们需要综合考虑他们,最常见的方法就是F1。
F1是查准率和查全率的调和平均值。证明见附1。
在一些应用中,我们查准率和查全率的重视程度不同,这时候就需要用到F1度量的一般形式是----Fβ。 Fβ是查准率和查全率的加权调和平均。证明见附2。 当β=1时退化为F1;当β>1时查全率有更大影响;当β<1时查准率有更大影响。
使用错误率(正确率)、精确度、召回率、F1值这几个方法方法有个缺点就是需要对预测概率设分类阔值,当预测概率大于阈值为正例,反之为负例。这使得模型多了一个超参数,并且这个超参数会影响模型的泛化能力。下面介绍的P-R曲线和ROC曲线就没有这样的限制,他们把所有的分类阈值从0-1都在曲线上展示了一下,然后就可以看出整个模型的好坏。
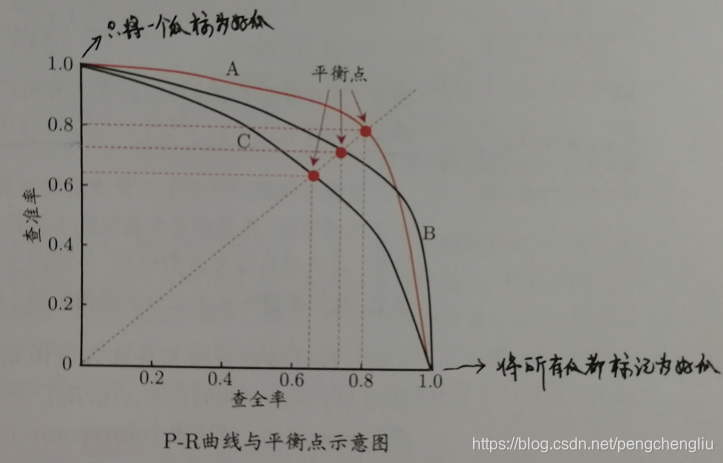
五、P-R曲线 我们可以根据学习器的预测结果对样例进行排序,排在前面的是正样本的可能性大,排在后面的是正样本的可能性小。按此顺序逐个把样本作为正例进行预测,则每次可计算当前的查全率和查准率,以查准率为y轴,以查全率为x轴,可以画出P-R曲线。
比如,对于10个样本点,某个机器学习模型计算出的属于正样本的概率分别为:0.9 0.8 0.8 0.7 0.5 0.4 0.3 0.3 0.2 0.1,那这样绘制曲线:当把第一个样本作为正样本,其他样本作为负样本时,得到一个(查准率,查全率)点。当把前两个样本作为正样本,其他作为负样本时,得到一个点。当把前3个作为正样本时,得到一个点。。。。把这10个点连成一条线,就是一条P-R曲线。
上图中每一条曲线代表一个学习期。一共有三个学习器。 怎么判断ABC三个学习器哪一个好呢? 方法一:若一个学习期被另一个完全包住,则可以判断后者好。图中,A和B优于C。如果两条曲线有交叉,则难以一般性地说谁好谁不好。 方法二:比较P-R曲线下面积的大小。 方法三:"平衡点"(BEP),即"查准率"=="查全率"时的取值。基于平衡点比较,A优于B。
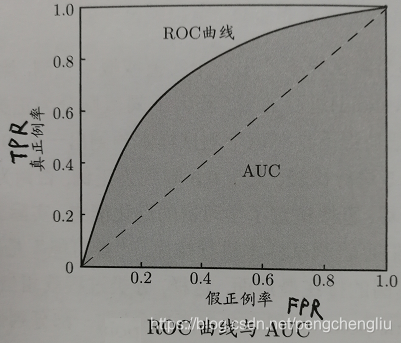
六、ROC曲线 ROC("Receiver Operating Characteristic",受试者工作特征)曲线。
首先介绍两个指标:TPR、FPR TPR(真正例率、灵敏度):TP/(TP+FN) 也就是召回率,即好瓜里面有多少预测为了好瓜?即,好用户的预测正确率。 FPR(假正例率、特异度):FP/(TN+FP) 坏瓜里面有多少预测为了好瓜?即,坏用户的预测错误率。
与P-R曲线相似,我们根据预测结果对样本进行排序,按此顺序逐个把概率值作为阈值进行预测,则每次可计算当前的TPR和FPR,以TPR为y轴,以FPR为x轴,可以画出ROC曲线。
怎么确定模型的好坏? 1. 我们希望好用户的预测正确率越高越好,坏用户的预测错误率越低越好。所以ROC曲线越陡越好,即ROC下面的面积越大越好。 2. 若一个学习期被另一个完全包住,则可以判断后者好。如果两条曲线有交叉,则难以一般性地说谁好谁不好。 3. 可以比较P-R曲线下面积的大小。这里有一个专有名词,叫AUC。AUC(Area Under Curve)的值为ROC曲线下面的面积。 AUC的一般判断标准为: 0.5 :即与上图中虚线重合,表示模型的区分能力与随机猜测没有差别。随机猜,TPR和FPR都是50%. 0.5 - 0.7 :效果较低,但用于预测股票已经很不错了 0.7 - 0.85 :效果一般 0.85 - 0.95:效果很好 0.95 - 1 :效果非常好,但一般不太可能 1 :即ROC曲线为左边的轴和上边的轴。说明模型十分精准。正例正确率100%,反例错误率0.
附1:
附2:
|