下载数据
1、进入风云卫星遥感数据服务网 https://satellite.nsmc.org.cn/PortalSite/Default.aspx,登录账号,如无则需实名注册
2、点击数据 -> 数据下载 -> 风云二号/FY2H/VISSR/产品 -> 总云量(CTA)-> 9210格式总云量数据 -> 选择需要的时间段 -> 搜索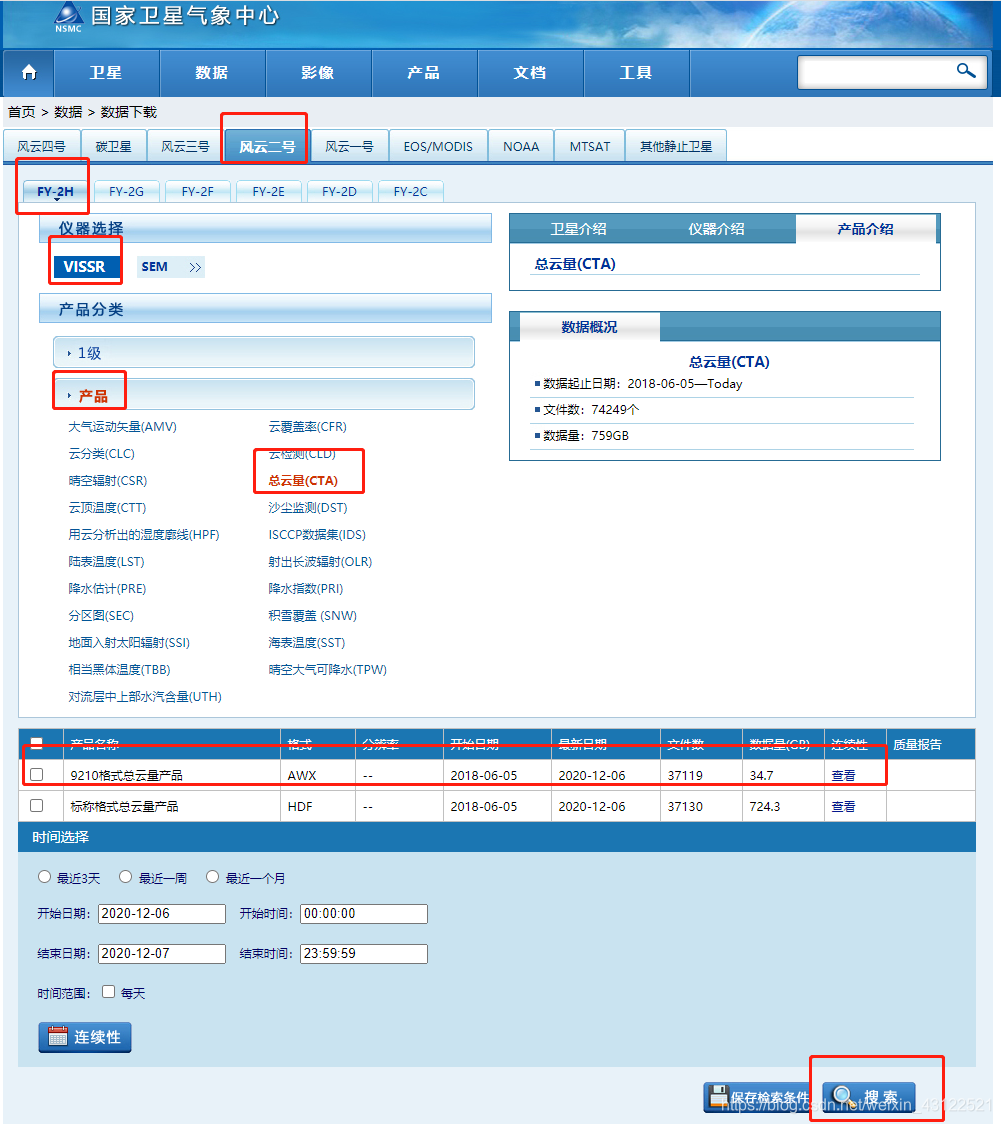
3、勾选想要的时间数据,或者点击全选,后进入购物车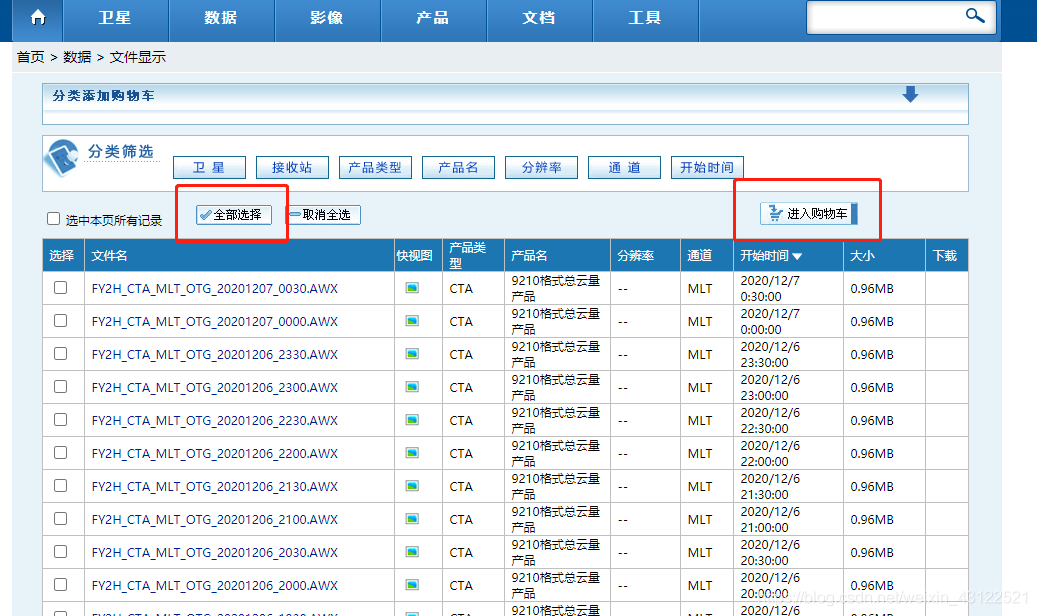
4、提交订单,会到回调过程,等待回调完成,一般半个小时多一些
5、回调完成后,进入我的订单,点击下载,便会出现ftp文件,可单击下载,也可以利用浏览器的downthemall插件,批量化下载所有的ftp文件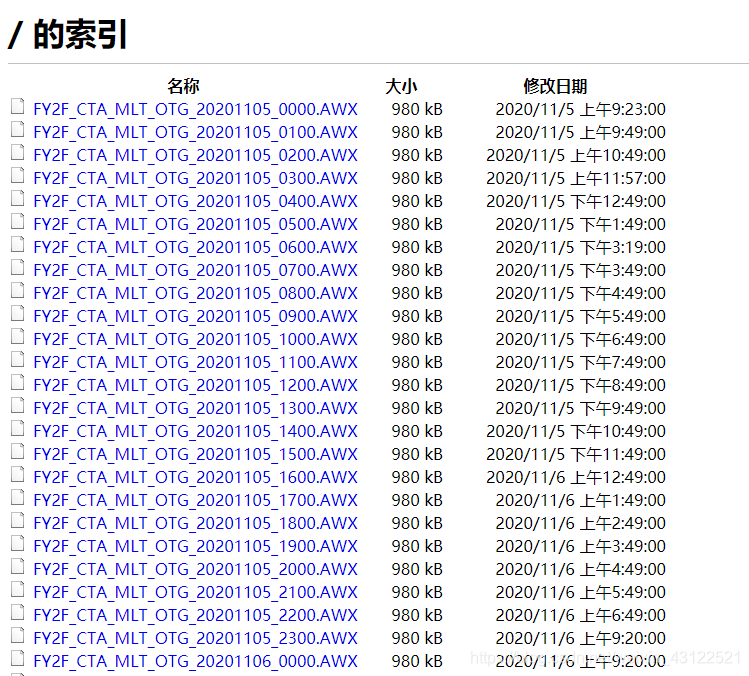
处理数据
处理数据的代码来自https://github.com/wqshen/AwxReader
我自己改了一些,删除了一些画图和转换nc文件,添加了批量处理,并将云量写入data.txt
# -*- coding: utf-8 -*-
import os
import numpy as np
from struct import unpack
from datetime import datetime, timedelta
class AwxGridField(object):
"""AWX grid field file reader 9210"""
def __init__(self, pathfile, lat, lon, autoload=True):
self._variable_dict()
self.pathfile = pathfile
self.tlat = lat
self.tlon = lon
self._deconstruct_filename()
self.file = open(pathfile, 'rb')
self._load_head_level1()
self._load_head_level2()
self._contruct_coords()
if autoload: self._load()
def __repr__(self):
"""print file info"""
s = ['=========文件信息=========\n']
for k in self._head_level1.keys():
s.append('{}: {}\n'.format(self._head_level1[k], self.head_level1[k]))
s.append('------------\n')
for k in self._head_level2.keys():
s.append('{}: {}\n'.format(self._head_level2[k], self.head_level2[k]))
return ''.join(s)
def __getitem__(self, item):
if isinstance(item, slice):
return self.lon, self.lat[self._reconstruct_lat_slice(item)], self.data[self._reconstruct_lat_slice(item)]
elif isinstance(item, tuple) and isinstance(item[0], slice):
slice_lon = self._reconstruct_lon_slice(item[1])
slice_lat = self._reconstruct_lat_slice(item[0])
return self.lon[slice_lon], self.lat[slice_lat], self.data[slice_lon, slice_lat]
else:
raise TypeError("argument item must be type of slice or tuple (tuple of slice)")
def __del__(self):
"""close file when delete instance object"""
if hasattr(self, 'file'):
self.file.close()
def _load(self):
"""read in data from file"""
self.file.seek(self.head_level1['head_record'])
self.data = self._load_field()
def clipper(self, item, include_end=True):
"""clip data to the interested region
Parameters
----------
item (slice, tuple of slice): latitude or/and longitude slice, like slice(55, 0)
include_end (bool): is include the end point, default: True
"""
slice_lon = self._reconstruct_lon_slice(item[1], include_end)
slice_lat = self._reconstruct_lat_slice(item[0], include_end)
self.lon = self.lon[slice_lon]
self.lat = self.lat[slice_lat]
self.data = self.data[slice_lat, slice_lon]
# with open("data.txt", "a+") as f:
# f.write(os.path.basename(self.pathfile) + " " + str(self.data[self.tlat][self.tlon]) + "\n")
print(os.path.basename(self.pathfile), self.data[self.tlat][self.tlon])
def obs_start_datetime(self, BJT=False):
"""get observation time of data
Parameters
----------
BJT (bool): is convert UTC datetime to Beijing Time
Returns
-------
(datetime): the data time in UTC (default) or BJT when `BJT=True`
"""
dt = datetime(self.head_level2['start_year'], self.head_level2['start_month'],
self.head_level2['start_day'], self.head_level2['start_hour'],
self.head_level2['start_minute'])
return dt + timedelta(hours=8) if BJT else dt
def _reconstruct_lat_slice(self, item, include_end=True):
"""reconstruct lat slice
Parameters
----------
item (slice, tuple of slice): latitude or/and longitude slice, like slice(55, 0)
include_end (bool): is include the end point, default: True
Returns
-------
(slice): latitude slice
"""
if item.start is None or (item.start > self.lat[0]):
start = None
else:
start = np.argmax(self.lat < item.start)
if item.stop is None or (item.stop < self.lat[-1]):
stop = None
else:
stop = np.argmin(self.lat > item.stop)
return slice(start, stop + 1 if include_end else stop, item.step)
def _reconstruct_lon_slice(self, item, include_end=True):
"""reconstruct longitude slice
Parameters
----------
item (slice, tuple of slice): latitude or/and longitude slice, like slice(100, 125)
include_end (bool): is include the end point, default: True
Returns
-------
(slice): longitude slice
"""
if item.start is None or (item.start < self.lon[0]):
start = None
else:
start = np.argmax(self.lon > item.start)
if item.stop is None or (item.stop > self.lon[-1]):
stop = None
else:
stop = np.argmin(self.lon < item.stop)
return slice(start, stop + 1 if include_end else stop, item.step)
def _deconstruct_filename(self):
"""deconstruct AWX filename to get base information of file"""
self.satellite, self.product_type, self.channel, \
self.proj, self.obs_date, self.obs_start_time = os.path.splitext(os.path.basename(self.pathfile))[0].split('_')
def _contruct_coords(self):
"""construct data coordinate based start and end of latitude,longitude and resolution of data"""
latmax = self.head_level2['leftup_lat'] / 100.
lonmin = self.head_level2['leftup_lon'] / 100.
latmin = self.head_level2['rightdown_lat'] / 100.
lonmax = self.head_level2['rightdown_lon'] / 100.
hreso = self.head_level2['hgrid_space'] / 100.
vreso = self.head_level2['vgrid_space'] / 100.
self.lon = np.arange(lonmin, lonmax + hreso, hreso)
self.lat = np.arange(latmax, latmin - vreso, -vreso)
def _load_field(self):
"""read data field"""
hgrid_num, vgrid_num = self.head_level2['hgrid_num'], self.head_level2['vgrid_num']
data = np.fromstring(self.file.read(hgrid_num * vgrid_num), np.uint8).reshape(hgrid_num, vgrid_num)
return (data.astype(float) + self.head_level2['grid_base']) / self.head_level2['grid_scale']
def _load_head_level1(self):
self.head_level1 = {k: v for k, v in zip(self._head_level1.keys(), unpack('12s9h8sh', self.file.read(40)))}
def _load_head_level2(self):
self.head_level2 = {k: v for k, v in zip(self._head_level2.keys(), unpack('8s36h', self.file.read(80)))}
def _variable_dict(self):
key = 'filename_Sat96, int_order, head1_length, head2_length, filled_length, record_length, ' \
'head_record, data_record, product_kind, zip_method, form_string, data_quality'.split(', ')
value = 'Sat96文件名,整型数的字节顺序,第一级文件头长度,第二级文件头长度,填充段数据长度,纪录长度,' \
'文件头占用记录数,产品数据占用记录数,产品类别,压缩方式,格式说明字串,产品数据质量标记'.split(',')
from collections import OrderedDict
self._head_level1 = OrderedDict()
for k, v in zip(key, value):
self._head_level1[k] = v
key2 = 'satellite_name, grid_element, grid_byte, grid_base, grid_scale, time_scale, ' \
'start_year, start_month, start_day, start_hour, start_minute, ' \
'end_year, end_month, end_day, end_hour, end_minute, ' \
'leftup_lat, leftup_lon, rightdown_lat, rightdown_lon, ' \
'grid_unit, hgrid_space, vgrid_space, hgrid_num, vgrid_num, ' \
'has_land, land, has_cloud, cloud, has_water, water, has_ice, ' \
'ice, has_quality, quality_up, quality_dowm, reserve'.split(', ')
value2 = '卫星名,格点场要素,格点数据字节,格点数据基准值,格点数据比例因子,时间范围代码,' \
'开始年,开始月,开始日,开始时,开始分,结束年,结束月,结束日,结束时,结束分,' \
'网格左上角纬度,网格左上角经度,网格右下角纬度,网格右下角经度,' \
'格距单位,横向格距,纵向格距,横向格点数,纵向格点数,' \
'有无陆地判释值,陆地具体判释值,有无云判释值,云具体判释值,有无水体判释值,水体具判释值,' \
'有无冰体判释值,冰体具判释值,是否有质量控制值,质量控制值上限,质量控制值下限,备用'.split(',')
self._head_level2 = OrderedDict()
for k, v in zip(key2, value2):
self._head_level2[k] = v
@property
def _element_dict(self):
return {0: '数值预报', 1: '海面温度(K)', 2: '海冰分布', 3: '海冰密度', 4: '射出长波辐射(W/m2)',
5: '归一化植被指数', 6: '比值植被指数', 7: '积雪分布', 8: '土壤湿度(kg/m3)',
9: '日照(小时)', 10: '云顶高度(hPa)', 11: '云顶温度(K)', 12: '低云云量', 13: '高云云量',
14: '降水指数(mm/1小时)', 15: '降水指数(mm/6小时)', 16: '降水指数(mm/12小时)',
17: '降水指数(mm/24小时)', 18: '对流层中上层水汽量(相对湿度)', 19: '亮度温度',
20: '云总量(百分比)', 21: '云分类', 22: '降水估计(mm/6小时)', 23: '降水估计(mm/24小时)',
24: '晴空大气可降水(mm)', 25: '备用', 26: '地面入射太阳辐射(W/m2)', 27: '备用', 28: '备用',
29: '备用', 30: '备用', 31: '1000hPa相对湿度', 32: '850hPa相对湿度', 33: '700hPa相对湿度',
34: '600hPa相对湿度', 35: '500hPa相对湿度', 36: '400hPa相对湿度', 37: '300hPa相对湿度'}
def test_read(pathfile, lat, lon):
"""测试裁剪数据并快速绘图"""
agf = AwxGridField(pathfile, lat, lon)
print(agf)
agf.clipper((slice(55, 0), slice(30, 130))) #裁剪指定经度的数据,看处理数据的纬度从55-0,经度从30-130,也可不裁剪
if __name__ == '__main__':
#FY2F的格点场纬度55到-45,经度从东经62到东经162
#指定某一经纬度的云量数据
lat = 32
lon = 119
path = "E:\\satellie\\file"
filenames = sorted(os.listdir(path))
for filename in filenames:
filepath = os.path.join(path, filename)
print(filepath)
test_read(filepath, lat, lon)
至此,总云量数据可以得出。
版权声明:本文为weixin_43122521原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。