概念
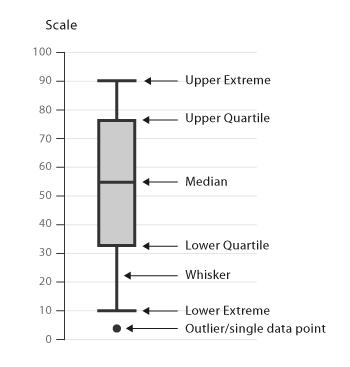
箱线图通过数据的四分位数来展示数据的分布情况。例如:数据的中心位置,数据间的离散程度,是否有异常值等。
把数据从小到大进行排列并等分成四份,第一分位数(Q1),第二分位数(Q2)和第三分位数(Q3)分别为数据的第25%,50%和75%的数字。

四分位间距(Interquartilerange(IQR))=上分位数(upper quartile)-下分位数(lower quartile)
箱线图分为两部分,分别是箱(box)和须(whisker)。箱(box)用来表示从第一分位到第三分位的数据,须(whisker)用来表示数据的范围。
箱线图从上到下各横线分别表示:数据上限(通常是Q3+1.5IQR),第三分位数(Q3),第二分位数(中位数),第一分位数(Q1),数据下限(通常是Q1-1.5IQR)。有时还有一些圆点,位于数据上下限之外,表示异常值(outliers)。
(注:如果数据上下限特别大,那么whisker将显示数据的最大值和最小值。)
案例
1. 使用pandas自带的函数
使用pandas里的dataframe数据结构存放待显示的数据。如果希望显示的各个数据列表中,数据长度不一致,可以先用Series函数转换为Series数据,再存储到dataframe中,对应index的value值若不存在则为NaN。
下面我们随机生成4组数据,看看他们的箱线图。
【代码】
import numpy as npimport pandas as pdfrom matplotlib import pyplot as pltdef list_generator(mean, dis, number): # 封装一下这个函数,用来后面生成数据 return np.random.normal(mean, dis * dis, number) # normal分布,输入的参数是均值、标准差以及生成的数量# 我们生成四组数据用来做实验,数据量分别为70-100y1 = list_generator(0.8531, 0.0956, 70)y2 = list_generator(0.8631, 0.0656, 80)y3 = list_generator(0.8731, 0.1056, 90)y4 = list_generator(0.8831, 0.0756, 100)# 如果数据大小不一,记得需要下面语句,把数组变为seriesy1 = pd.Series(np.array(y1))y2 = pd.Series(np.array(y2))y3 = pd.Series(np.array(y3))y4 = pd.Series(np.array(y4))data = pd.DataFrame({"1": y1, "2": y2, "3": y3, "4": y4, })data.boxplot() # 这里,pandas自己有处理的过程,很方便哦。plt.ylabel("ylabel")plt.xlabel("xlabel") # 我们设置横纵坐标的标题。plt.show()【效果】
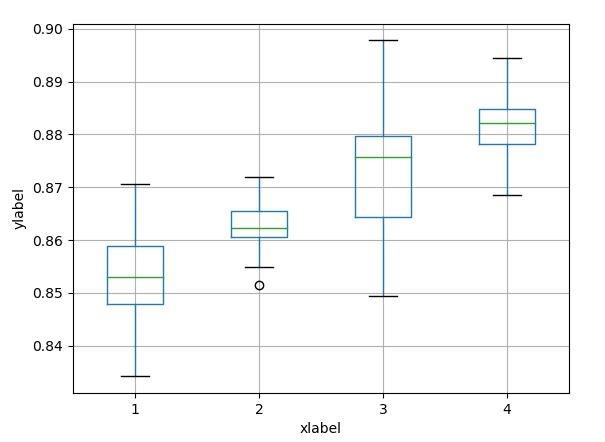
上面的箱线图很简单,给出数据后,几行代码就能生成,不过这是简单的箱线图。下面再看看稍微复杂点的。
2. 使用matplotlib库画箱线图
我们上面介绍了使用pandas画箱线图,几句命令就可以了。但是稍微复杂点的可以使用matplotlib库。matplotlib代码稍微复杂点,但是很灵活。细心点同学会发现pandas里面的画图也是基于此库的,下面给你看看pandas里面的源码:
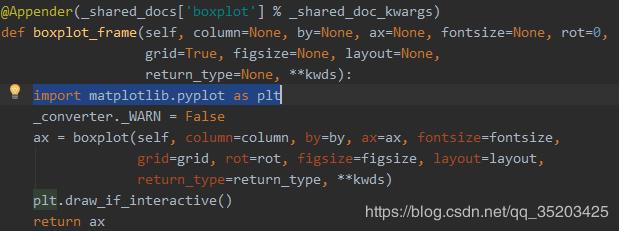
通过源码可以看到pandas内部也是通过调用matplotlib来画图的。那下面我们自己实现用matplotlib画箱线图。
我们简单模拟一下,男女生从20岁,30岁的花费对比图,使用箱线图来可视化一下。
【代码】
import numpy as npimport matplotlib.pyplot as pltfig, ax = plt.subplots() # 子图def list_generator(mean, dis, number): # 封装一下这个函数,用来后面生成数据 return np.random.normal(mean, dis * dis, number) # normal分布,输入的参数是均值、标准差以及生成的数量# 我们生成四组数据用来做实验,数据量分别为70-100# 分别代表男生、女生在20岁和30岁的花费分布girl20 = list_generator(1000, 29.2, 70)boy20 = list_generator(800, 11.5, 80)girl30 = list_generator(3000, 25.1056, 90)boy30 = list_generator(1000, 19.0756, 100)data=[girl20,boy20,girl30,boy30,]ax.boxplot(data)ax.set_xticklabels(["girl20