DCGAN只是在网络结构上做了相应的改进,但是实质上并没有解决gan中的本质缺陷
Wasserstein GAN(下面简称WGAN)成功地做到了以下爆炸性的几点:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
- 基本解决了collapse mode的问题,确保了生成样本的多样性
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练- 得越好,代表生成器产生的图像质量越高
该论文的公式较多,本文只做简单的描述即可
原始GAN中判别器要最小化如下损失函数,尽可能把真实样本分为正例,生成样本分为负例
根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布与生成分布[公之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化和之间的JS散度。
问题就出在这个JS散度上。我们会希望如果两个分布之间越接近它们的JS散度越小,但是JS散度的问题在于,当两个分布没有接触时或者接触可以忽略,JS值会固定为log2,导致梯度消失
而Wesserstein GAN提出了新的解决方案,引入了Wesserstein 距离,表示将生成分布 “搬” 运成真实分布的最小“开销”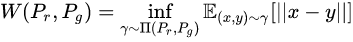
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近
最后得到判别器的损失函数为: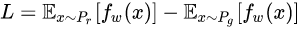
尽可能取到最大,此时就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数[公式])。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
生成器的损失函数为: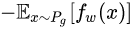
公式15是公式17的反,可以指示训练进程,其数值越小,表示真实分布与生成分布的Wasserstein距离越小,GAN训练得越好。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Discriminator(nn.Module):
def __init__(self, channels_img, features_d):
super(Discriminator, self).__init__()
self.disc = nn.Sequential(
# input: N x channels_img x 64 x 64
nn.Conv2d(
channels_img, features_d, kernel_size=4, stride=2, padding=1
),
nn.LeakyReLU(0.2),
# _block(in_channels, out_channels, kernel_size, stride, padding)
self._block(features_d, features_d * 2, 4, 2, 1),
self._block(features_d * 2, features_d * 4, 4, 2, 1),
self._block(features_d * 4, features_d * 8, 4, 2, 1),
# After all _block img output is 4x4 (Conv2d below makes into 1x1)
nn.Conv2d(features_d * 8, 1, kernel_size=4, stride=2, padding=0),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.InstanceNorm2d(out_channels, affine=True),
nn.LeakyReLU(0.2),
)
def forward(self, x):
return self.disc(x)
class Generator(nn.Module):
def __init__(self, channels_noise, channels_img, features_g):
super(Generator, self).__init__()
self.net = nn.Sequential(
# Input: N x channels_noise x 1 x 1
self._block(channels_noise, features_g * 16, 4, 1, 0), # img: 4x4
self._block(features_g * 16, features_g * 8, 4, 2, 1), # img: 8x8
self._block(features_g * 8, features_g * 4, 4, 2, 1), # img: 16x16
self._block(features_g * 4, features_g * 2, 4, 2, 1), # img: 32x32
nn.ConvTranspose2d(
features_g * 2, channels_img, kernel_size=4, stride=2, padding=1
),
# Output: N x channels_img x 64 x 64
nn.Tanh(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
def initialize_weights(model):
# Initializes weights according to the DCGAN paper
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
def test():
N, in_channels, H, W = 8, 3, 64, 64
noise_dim = 100
x = torch.randn((N, in_channels, H, W))
disc = Discriminator(in_channels, 8)
assert disc(x).shape == (N, 1, 1, 1), "Discriminator test failed"
gen = Generator(noise_dim, in_channels, 8)
z = torch.randn((N, noise_dim, 1, 1))
assert gen(z).shape == (N, in_channels, H, W), "Generator test failed"
device = "cuda" if torch.cuda.is_available() else "cpu"
LEARNING_RATE = 5e-5
BATCH_SIZE = 64
IMAGE_SIZE = 64
CHANNELS_IMG = 1
Z_DIM = 128
NUM_EPOCHS = 5
FEATURES_CRITIC = 64
FEATURES_GEN = 64
CRITIC_ITERATIONS = 5
WEIGHT_CLIP = 0.01
transforms = transforms.Compose(
[
transforms.Resize(IMAGE_SIZE),
transforms.ToTensor(),
transforms.Normalize(
[0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)]
),
]
)
dataset = datasets.MNIST(root="MNIST", transform=transforms, download=False)
#comment mnist and uncomment below if you want to train on CelebA dataset
#dataset = datasets.ImageFolder(root="celeb_dataset", transform=transforms)
loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
# initialize gen and disc/critic
gen = Generator(Z_DIM, CHANNELS_IMG, FEATURES_GEN).to(device)
critic = Discriminator(CHANNELS_IMG, FEATURES_CRITIC).to(device)
initialize_weights(gen)
initialize_weights(critic)
# initializate optimizer
opt_gen = optim.RMSprop(gen.parameters(), lr=LEARNING_RATE)
opt_critic = optim.RMSprop(critic.parameters(), lr=LEARNING_RATE)
# for tensorboard plotting
fixed_noise = torch.randn(32, Z_DIM, 1, 1).to(device)
writer_real = SummaryWriter(f"Test/real")
writer_fake = SummaryWriter(f"Test/fake")
step = 0
gen.train()
critic.train()
for epoch in range(NUM_EPOCHS):
# Target labels not needed! <3 unsupervised
for batch_idx, (data, _) in enumerate(loader):
data = data.to(device)
cur_batch_size = data.shape[0]
# Train Critic: max E[critic(real)] - E[critic(fake)]
for _ in range(CRITIC_ITERATIONS):
noise = torch.randn(cur_batch_size, Z_DIM, 1, 1).to(device)
fake = gen(noise)
critic_real = critic(data).reshape(-1)
critic_fake = critic(fake).reshape(-1)
loss_critic = -(torch.mean(critic_real) - torch.mean(critic_fake))
critic.zero_grad()
loss_critic.backward(retain_graph=True)
opt_critic.step()
# clip critic weights between -0.01, 0.01
for p in critic.parameters():
p.data.clamp_(-WEIGHT_CLIP, WEIGHT_CLIP)
# Train Generator: max E[critic(gen_fake)] <-> min -E[critic(gen_fake)]
gen_fake = critic(fake).reshape(-1)
loss_gen = -torch.mean(gen_fake)
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
# Print losses occasionally and print to tensorboard
if batch_idx % 100 == 0 and batch_idx > 0:
gen.eval()
critic.eval()
print(
f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(loader)} \
Loss D: {loss_critic:.4f}, loss G: {loss_gen:.4f}"
)
with torch.no_grad():
fake = gen(noise)
# take out (up to) 32 examples
img_grid_real = torchvision.utils.make_grid(
data[:32], normalize=True
)
img_grid_fake = torchvision.utils.make_grid(
fake[:32], normalize=True
)
writer_real.add_image("Real", img_grid_real, global_step=step)
writer_fake.add_image("Fake", img_grid_fake, global_step=step)
step += 1
gen.train()
critic.train()
总结
WGAN前作分析了Ian Goodfellow提出的原始GAN两种形式各自的问题,第一种形式等价在最优判别器下等价于最小化生成分布与真实分布之间的JS散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及JS散度的突变特性,使得生成器面临梯度消失的问题;第二种形式在最优判别器下等价于既要最小化生成分布与真实分布直接的KL散度,又要最大化其JS散度,相互矛盾,导致梯度不稳定,而且KL散度的不对称性使得生成器宁可丧失多样性也不愿丧失准确性,导致collapse mode现象。
WGAN前作针对分布重叠问题提出了一个过渡解决方案,通过对生成样本和真实样本加噪声使得两个分布产生重叠,理论上可以解决训练不稳定的问题,可以放心训练判别器到接近最优,但是未能提供一个指示训练进程的可靠指标,也未做实验验证。
WGAN本作引入了Wasserstein距离,由于它相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题。接着通过数学变换将Wasserstein距离写成可求解的形式,利用一个参数数值范围受限的判别器神经网络来最大化这个形式,就可以近似Wasserstein距离。在此近似最优判别器下优化生成器使得Wasserstein距离缩小,就能有效拉近生成分布与真实分布。WGAN既解决了训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。作者对WGAN进行了实验验证。
参考链接
https://zhuanlan.zhihu.com/p/25071913
参考视频为 李宏毅视频教程