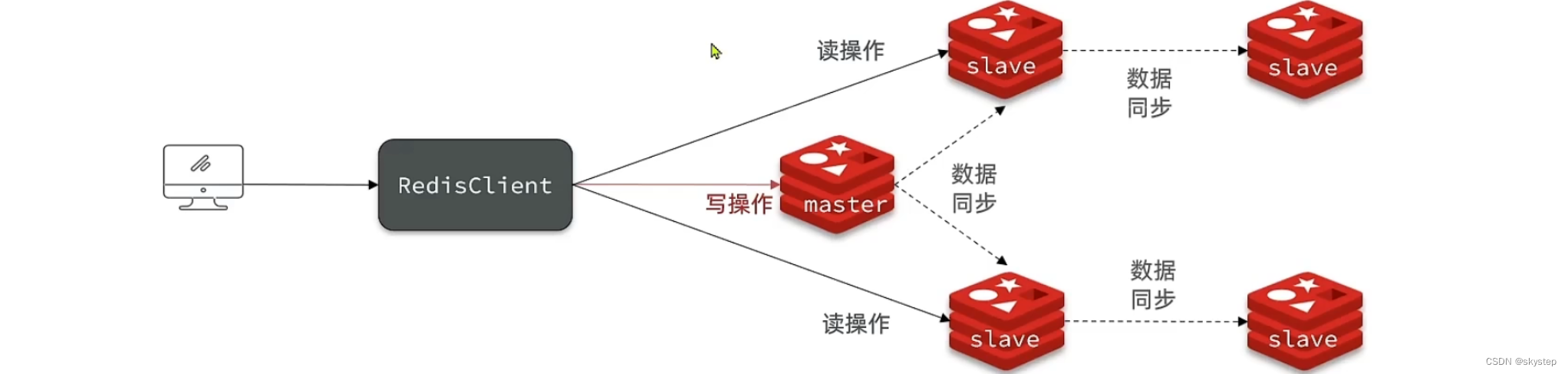
Redis 数据同步
全量同步

redis 从节点第一次连接主节点采用的是全量同步,包括两个阶段:
第一阶段:
- 从节点执行slaveof命令和主节点建立了连接,然后发送同步请求;
- 主节点收到消息判断是否是第一次请求,如果是,将数据版本信息发送给从节点;
- 从节点存储存储数据版本信息;
第二阶段:
- 主节点后台 fork 子进程生成 RDB;
- 将生产的 RDB 文件发送给从节点;
- 由于在记录 RDB 的同时会生成指令,主节点将这部分指令存储到repl_baklog;
- 将 repl_baklog 的指令发送到从节点;从节点进行存储;
数据同步原理
全量同步过程有一个问题:主节点如何判断一个从节点是第一次同步数据?
实际上每一个 redis 节点都会有一个 replication id ,称为数据集ID。从节点第一次请求主节点,会带上 replication id,主节点收到从节点 replication id,和自己的 replication id 对比,如果不相同说明是第一次请求同步数据,主节点将自己的 replication id 发送给从节点,从节点存储主节点的 replication id,从节点后续请求再带上该 replication id。
此外,主节点如何知道每次从 repl_baklog 中获取哪部分数据同步从节点?
实际上主节点向从节点同步数据时,会带上两个个参数:replication id 和 offset, offset 标记每次复制数据的偏移量。往后同步从节点带上 replication id 和 offset 即可。

增量同步
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OF5Xs64v-1656605036138)(https://note.youdao.com/yws/res/7/WEBRESOURCEcb63e2e95c849a9c2da7484aeecd9627)]](https://img-blog.csdnimg.cn/896cae44f5a14e66956d36ce9eae7624.png)
增量同步一般发生在重启阶段:
- 从节点带上 replication id 和 offset 向主节点请求同步;
- 主节点根据 replication id 判断是否和自己的一致;如果一直则回复继续;
- 主节点从 repl_baklog 中取出数据,同步到从节点;
- 从节点接收之后存储指令;
增量同步过程中需要注意一个问题:repl_baklog 是一个循环数组,offset 是主节点和从节点同步内容的偏移量。由于 repl_baklog 是一个循环数组,当从节点停止过长时间,旧数据会被新数据覆盖,这时候只能做全量同步。
主从同步优化
可以从这几个方面来优化主从集群:
- 在 master 中配置 repl-diskless-sync yes 启动无磁盘复制,避免全量同步时的磁盘IO;
- Redis 单节点的内存占用不要太大,减少 RDB 导致的过多磁盘IO;
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步;
- 限制一个 master 的 slave 节点,如果需要较多的 slave,可以采用主-从-从链接模式;
版权声明:本文为skystep原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。