计算机操作系统(十六):内存(一)
来源王道考研系列视频:
https://www.bilibili.com/video/BV1YE411D7nH
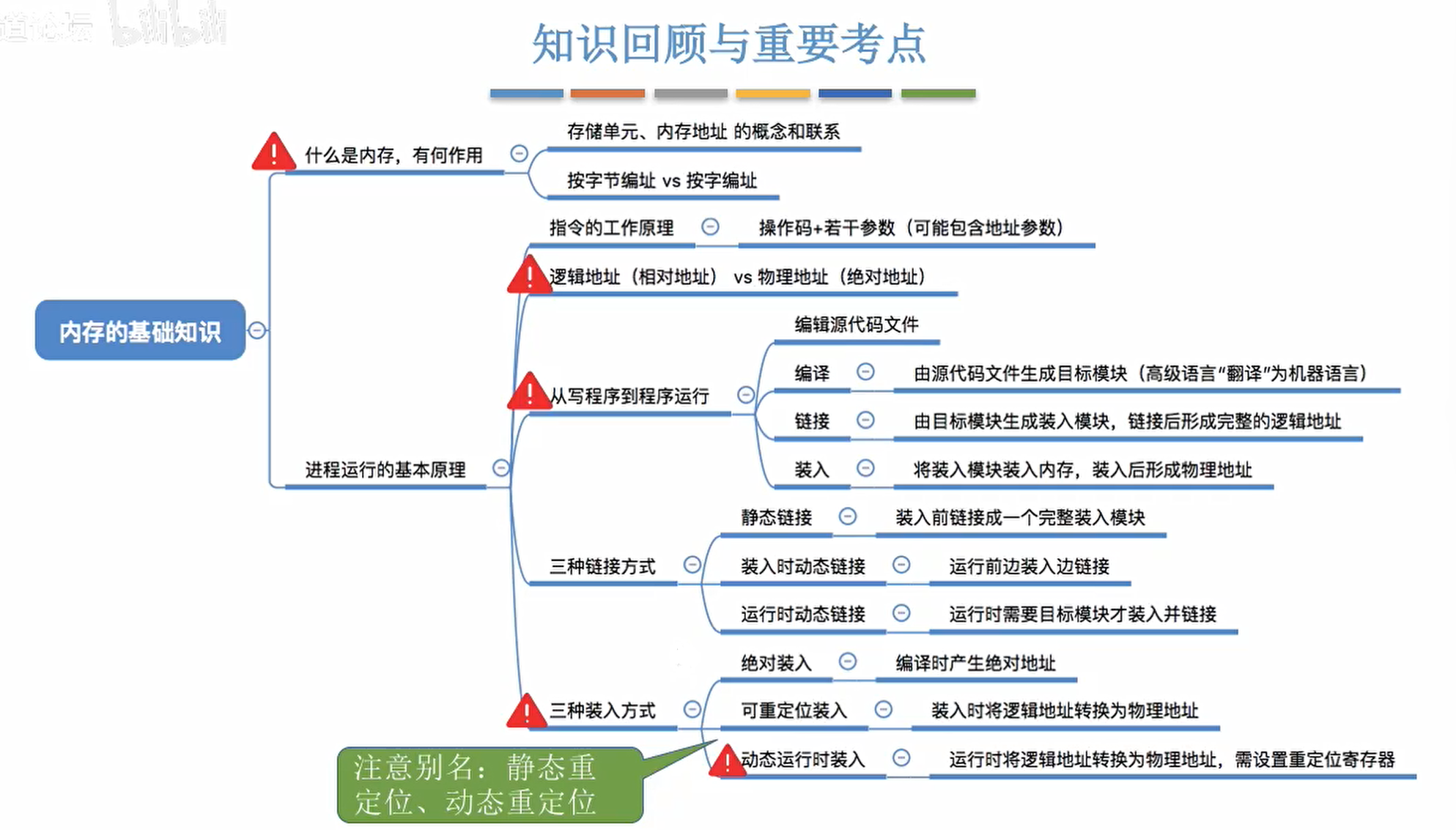
内存是用来存放数据的硬件,程序执行前需要先放到内存中才能被CPU处理。
内存中有一个一个的存储单元,内存地址从0开始,每个地址对应一个存储单元。
如果计算机按字节编址,每个存储单元的大小为1字节,即1B,八个二进制位。
如果字长为16位的计算机按字编址,则每个存储单元的大小为一个字;每个字的大小为16个二进制位。
逻辑地址和物理地址的转换
绝对装入
在编译的时候就知道程序该放到内存的哪个位置,编译程序产生绝对地址的目标代码装入程序按照装入模块的地址,将程序和数据装入内存。
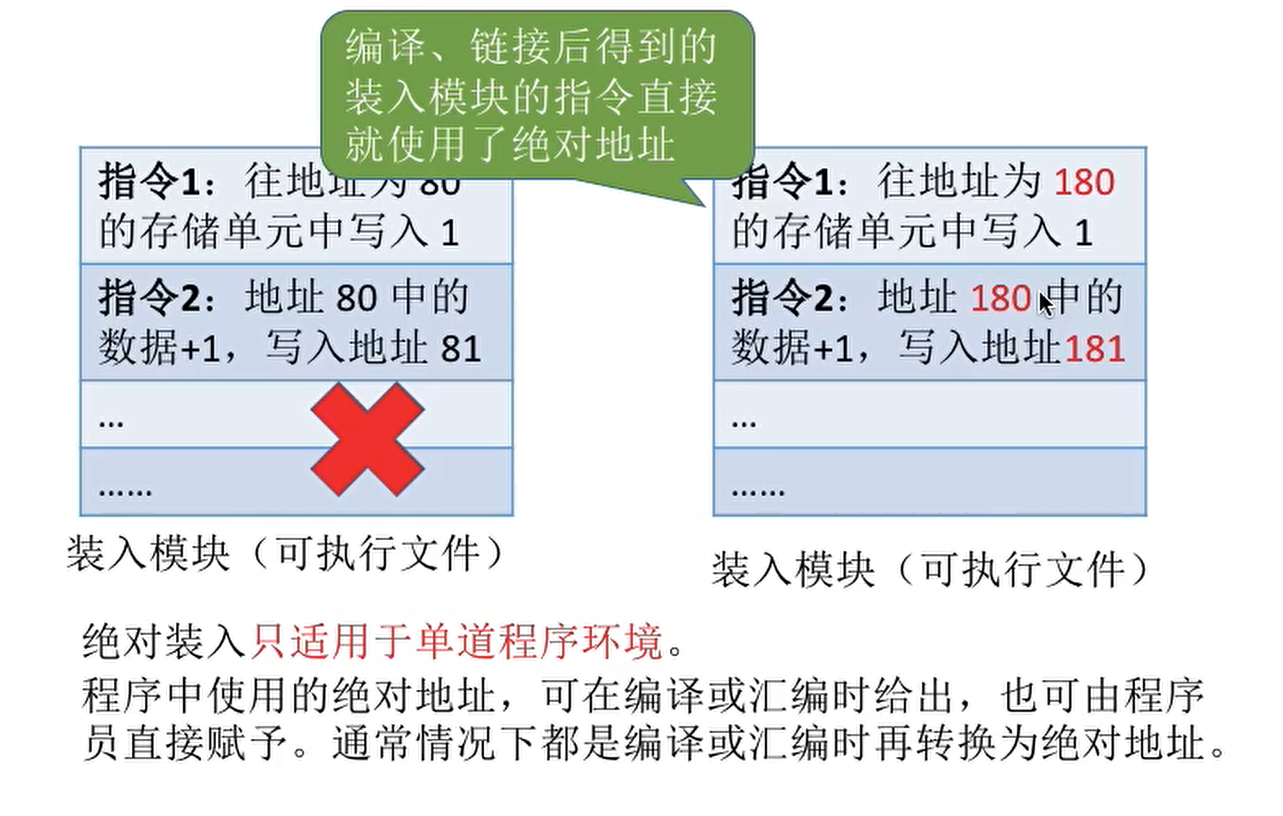
静态重定位
编译、链接后的装入模块的地址都是从0开始的,指令中使用的地址、数据存放的地址都是相对于起始位置而言的逻辑地址,可根据内存的当前情况,将装入模块放到适当的位置,装入时对地址进行重定位,将逻辑地址变换为物理地址。
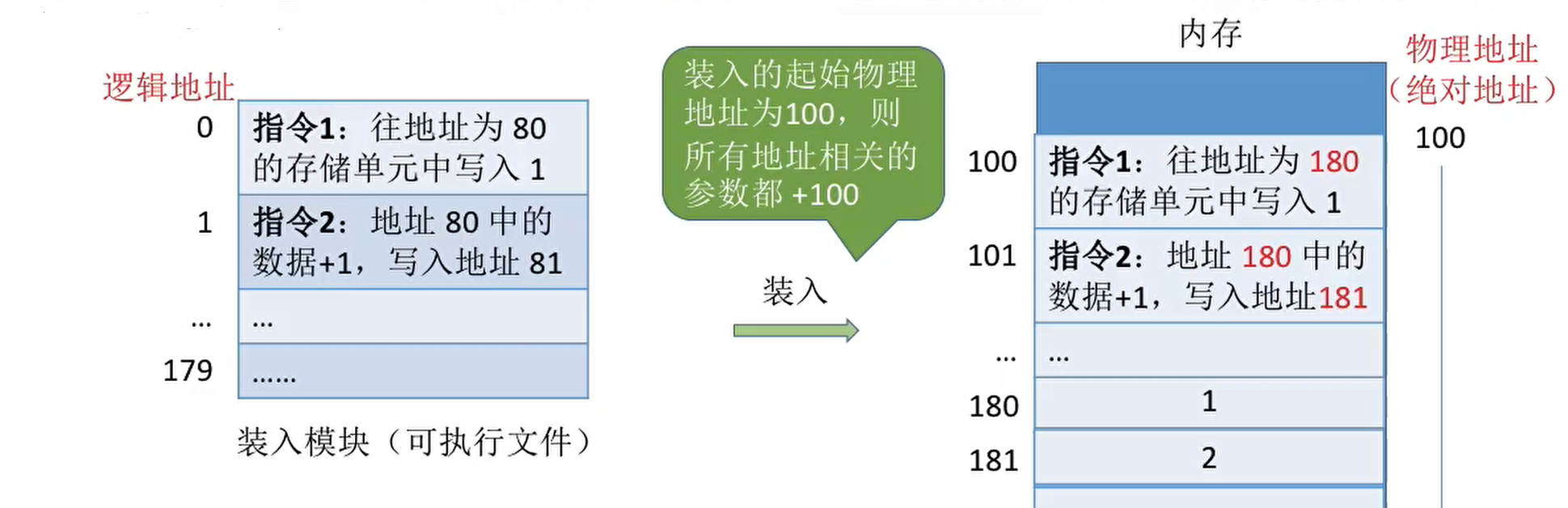
特点:在一个作业装入内存的是皇后,必须分配到要求的全部空间,如果没有足够的内存,就不能装入作业。作业一旦进入内存后,在运行期间就不能再移动,也不能再申请内存空间。
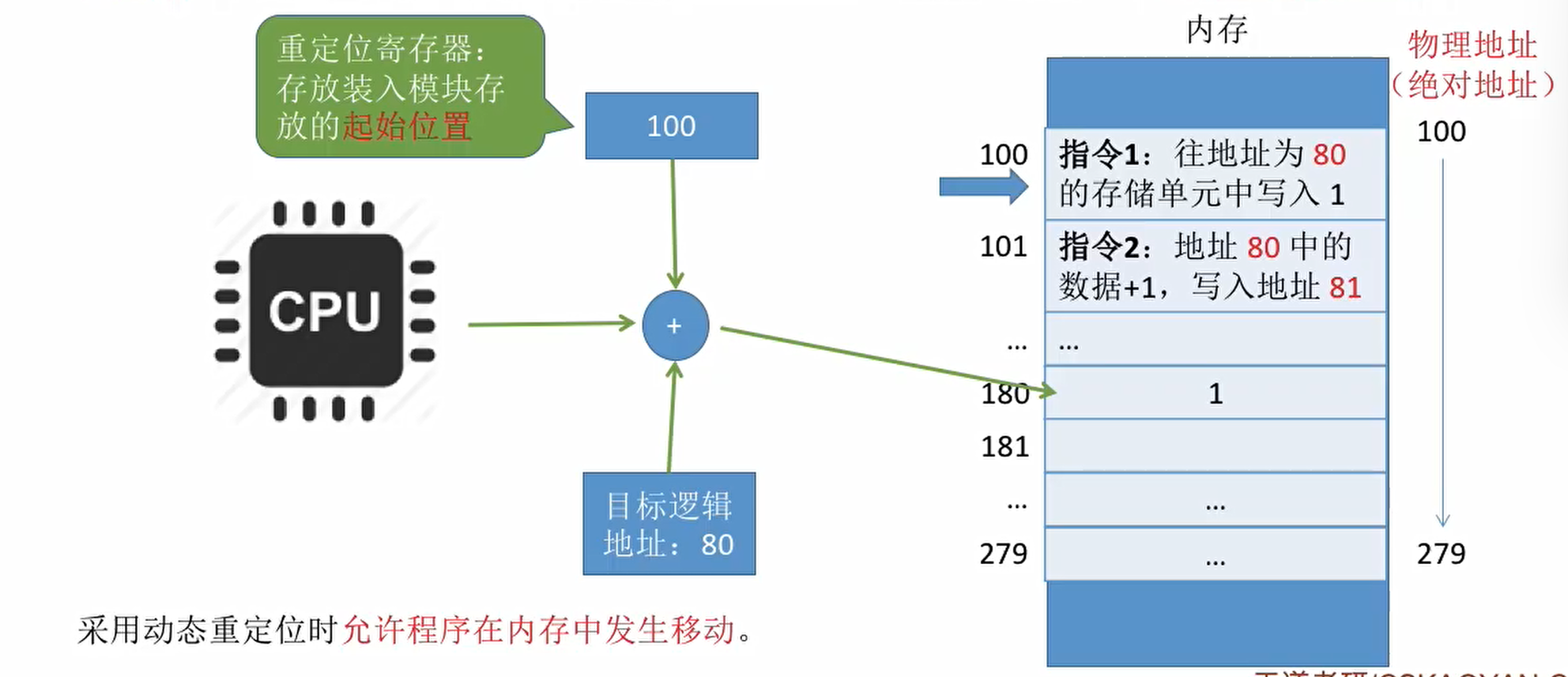
动态重定位
装入程序把装入模块装入内存后,并不会立刻将逻辑地址转换为物理地址,而是把地址推迟到程序真正执行时候才进行。
因此装入内存后所有的地址依然是逻辑地址,这种方式需要一个人重定位寄存器的支持。
链接的三种的方式:
- 静态链接:在程序运行之前,先将各目标模块及它们所需的库函数连接成一个完整的可执行文件(装入模块),之后不再拆开。
- 装入时动态链接:将各目标模块装入内存时,边装入边链接的链接方式。
- 运行时动态链接:在程序执行中需要该目标模块时,才对它进行链接。其优点是便于修改和更新,便于实现对目标模块的共享。
小结(一)
内存管理
- 操作系统负责内存空间的分配和回收
- 操作系统需要提供某种技术从逻辑上对内存空间进行扩充
- 需要提供地址转换功能,负责程序的逻辑地址和物理地址的转换。
- 需要提供内存保护功能。保证个进程再各自的内存空间内运行,互不干扰。
- 设置上下限寄存器
- 利用重定位寄存器、界地址寄存器进行判断
内存空间的扩充
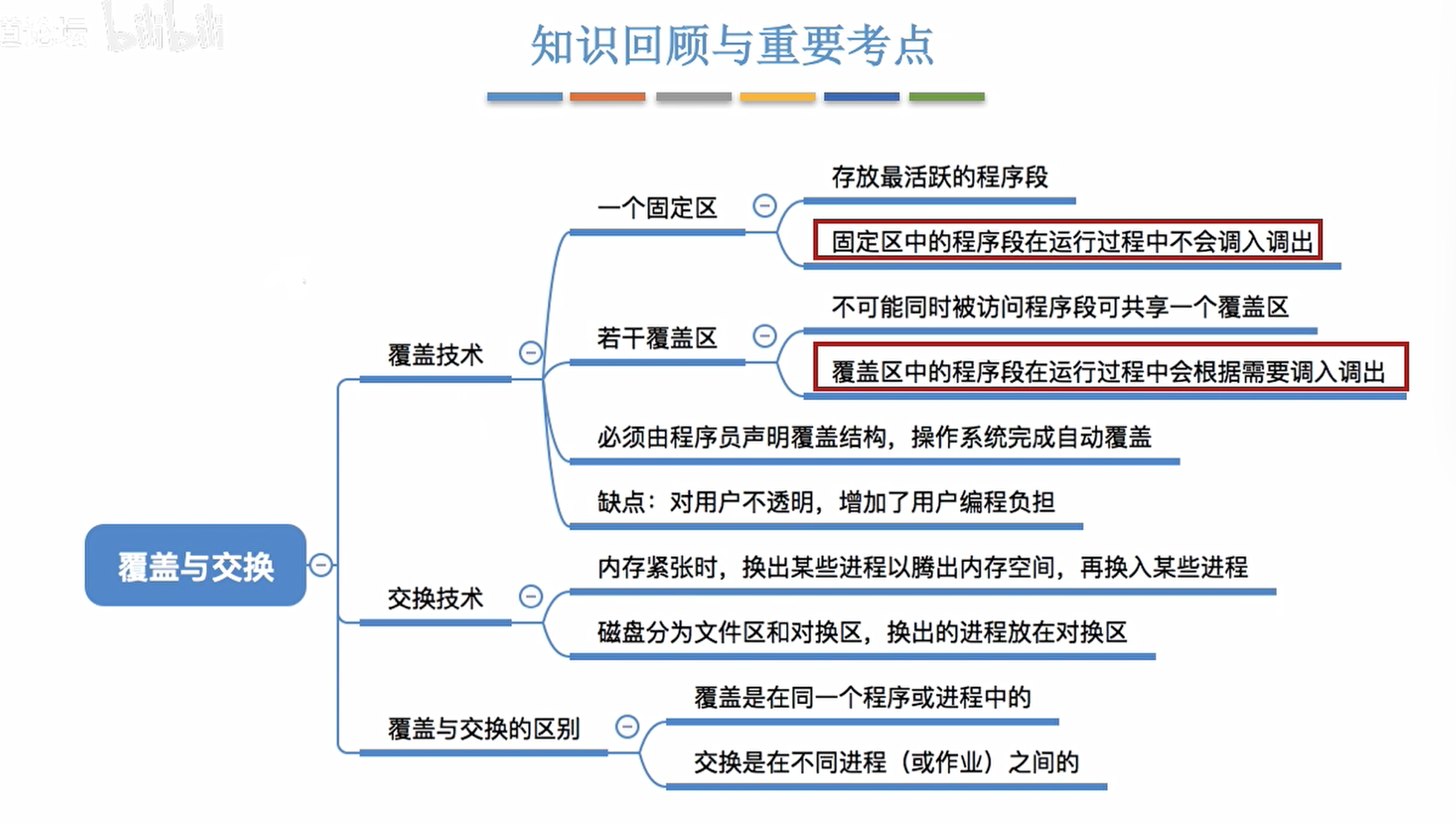
覆盖技术
将程序分为多个段落(多个模块),常用的段常驻,不常用的段再需要的时候调入内存。
内存中分为一个固定区和若干个覆盖区。
需要常驻内存的段落放在固定区中,调入后就不再调出,除非运行结束。
不常用的段放在覆盖区,需要时候调入内存,用不到时调出内存。
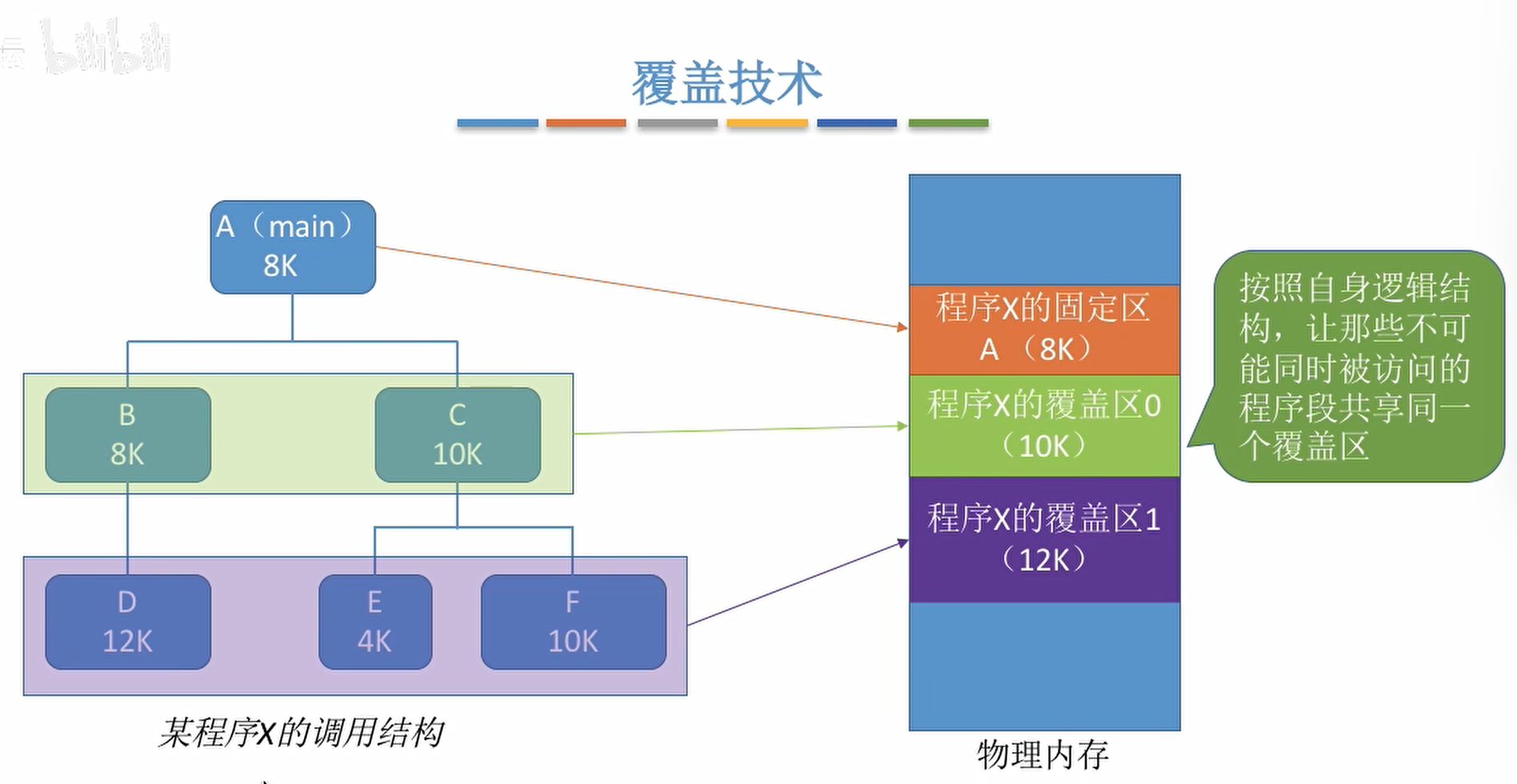
缺点:必须由程序员声明覆盖结构,操作系统完成自动覆盖,对用户不透明,增加了编程负担。
交换技术
内存紧张时,系统将内存中的某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存(进程在内存与磁盘间动态调度)
暂时换出外存等待的进程状态为挂起状态.
- 在外存的对换区保存被换出的进程
- 交换通常发生在许多进程运行且内存吃紧的时候进行,而系统负荷降低就会暂停。
- 可优先换出阻塞的进程;可换出优先级低的进程;为了防止优先级低的进程在被调入内存后很快又被换出,有的系统还会考虑驻留时间。
小结(二)
内存空间的分配与回收(一)
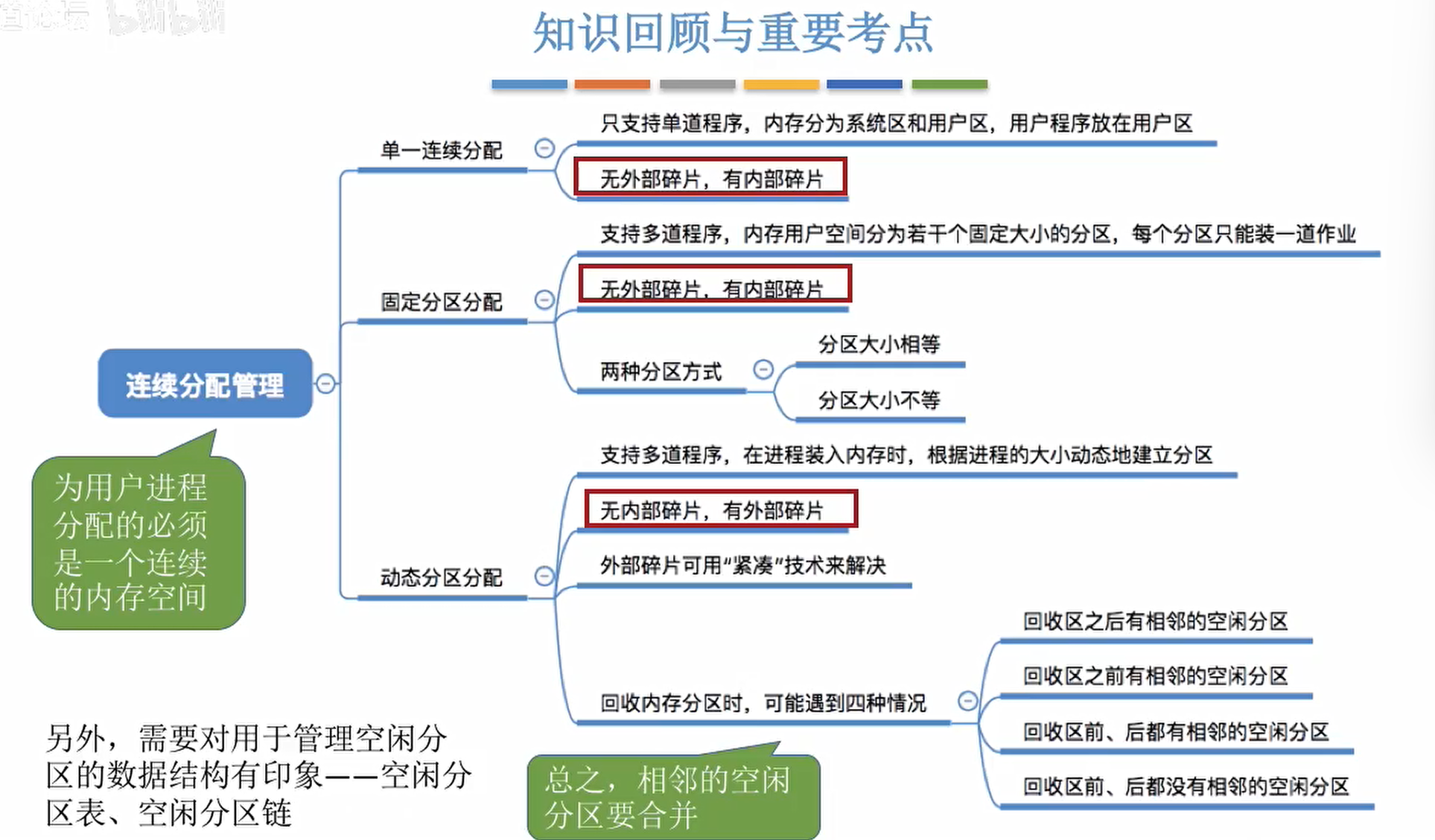
连续分配
系统给用户进程分配的必须是一个连续的内存空间。
单一连续分配
内存分为系统区和用户区,系统区通常位于内存的低地址部分,用于存放操作系统的相关数据。用户区用于存放用户进程的相关数据。
内存中只有一道用户程序,用户程序独占整个用户空间。
优缺点:实现简单;无外部碎片;可以使用覆盖技术;不一定要采取内存保护。但是只能用于单用户、单任务的操作系统;有内部碎片。
固定分区分配
将整个用户划分为若干个固定大小的分区,在每个分区中只装入一道作业。

动态分区分配
不会预先划分内存分区,而是在进程装入内存时候根据进程大小动态划分区域,并使得分区大小正好适合进程的需要。
系统要用什么样的数据结构来记录内存的使用情况?
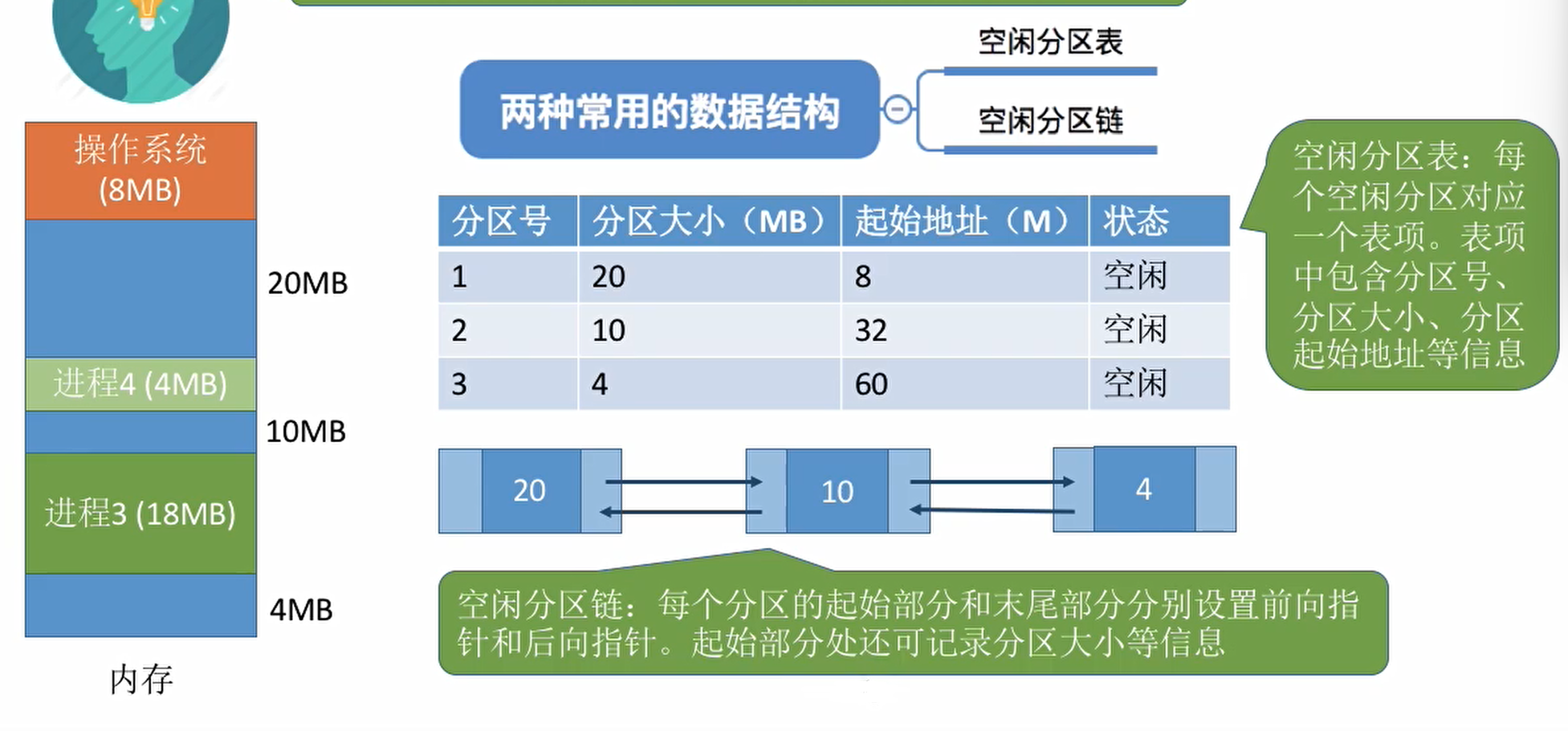
应该选择哪个空闲分区进行分配?
按照动态分区分配算法!
如何进行分区的分配与回收?
分配情况一:分配空间小于分区空间,直接改写分区大小和起始地址
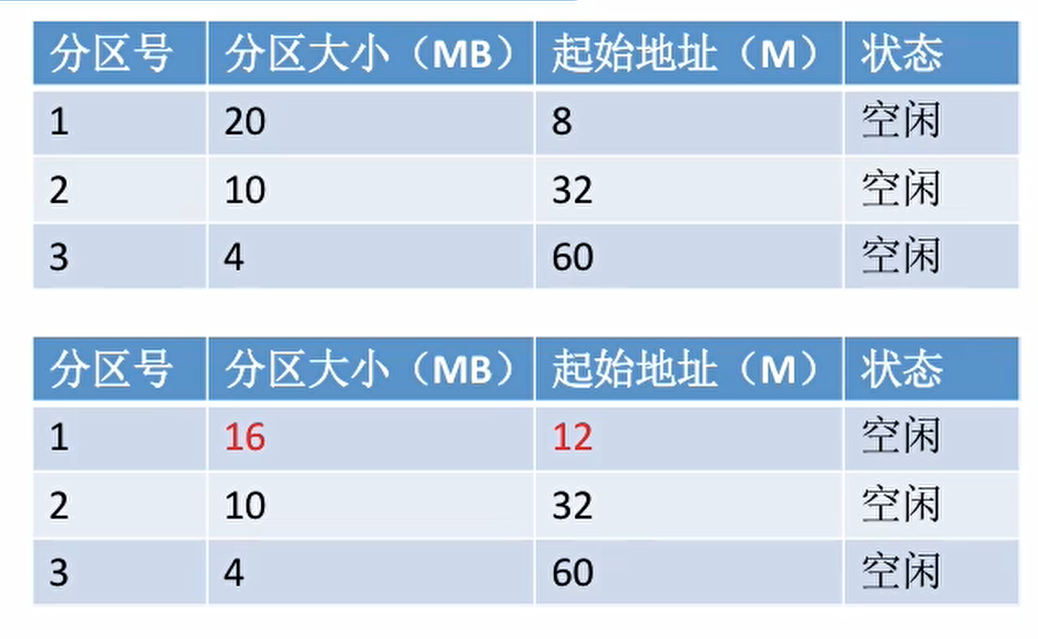
分配情况二:分配空间等于分区空间,分区数目减一
回收情况一:回收区前后有相邻的空闲分区,将空闲分区合并
回收情况二:回收区前后没有相邻的空闲分区,将空闲分区表增加一个表项
小结(三)
动态分配算法
首次适应算法
算法思想:每次都从最低地址开始查找,找到第一个能满足大小的空闲分区。
实现:空闲分区以地址递增的次序排列。每次分配内存时候顺序查找空闲分区链。
最佳适应算法
算法思想:优先使用更小的空闲区,留下大片的空闲区。
实现:空闲分区按照容量递增次序链接。每次分配内存时候顺序查找空闲分区链。
最坏适应算法
算法思想:优先使用更大的空闲区,留下大片的空闲区。
实现:空闲分区按照容量递减次序链接。每次分配内存时候顺序查找空闲分区链。
缺点:之后有“大进程”到达时,没有内存可以分配
邻近适应算法
算法思想:首次适应算法每次从链头开始查找。这可能导致低地址部分出现很多小的空闲分区,而每次分配查找时,都要经过这些分区,因此也增加了查找的开销。如果每次都从上次查找的位置开始检索,就能解决上述问题。
实现:空闲分区以地址递增顺序排列。每次分配内存时从上次查找结束位置开始查找空闲分区链,找到大小能满足要求的第一个空闲的分区。
小结(四)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6cV0bX74-1643186637556)(https://gitee.com/WAEM/my-pictures2/raw/master/png/image-20220124003915570.png)]](https://img-blog.csdnimg.cn/0c09d226ba0247538d0cb778b435e6a4.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAQktTVy4=,size_20,color_FFFFFF,t_70,g_se,x_16)