0. 写作目的
好记性不如烂笔头。
1. 主要思路
目前的self-attention需要生成 N * N 的affinity 矩阵(其中N = H * W), 作者提出存在一种更有效的方法?
因此作者提出了 Criss-Cross attention,使用“十字架” 的结构来代替 所有的位置(感觉使用“十字架”的paper很多,比如GCN使用十字街的conv,SPNet使用“十字架”的Pooling)。然后使用两次 criss-cross attention,这样可以综合全部的空间信息。
2. 模型具体细节
reduction 先将使用3*3conv将channel降低为输入channel 的1/4.
然后加入在两层 Criss-cross Attention Module之后,然后使用3*3conv进行refine一下得到H‘’, 然后与X 进行concat,
然后使用3*3conv + BN + dropuout + 1*1Conv输出结果(这里输出的是下采样的结果)。
作者这里也使用了辅助loss, 在layer3 加入了辅助loss,权重为0.4。

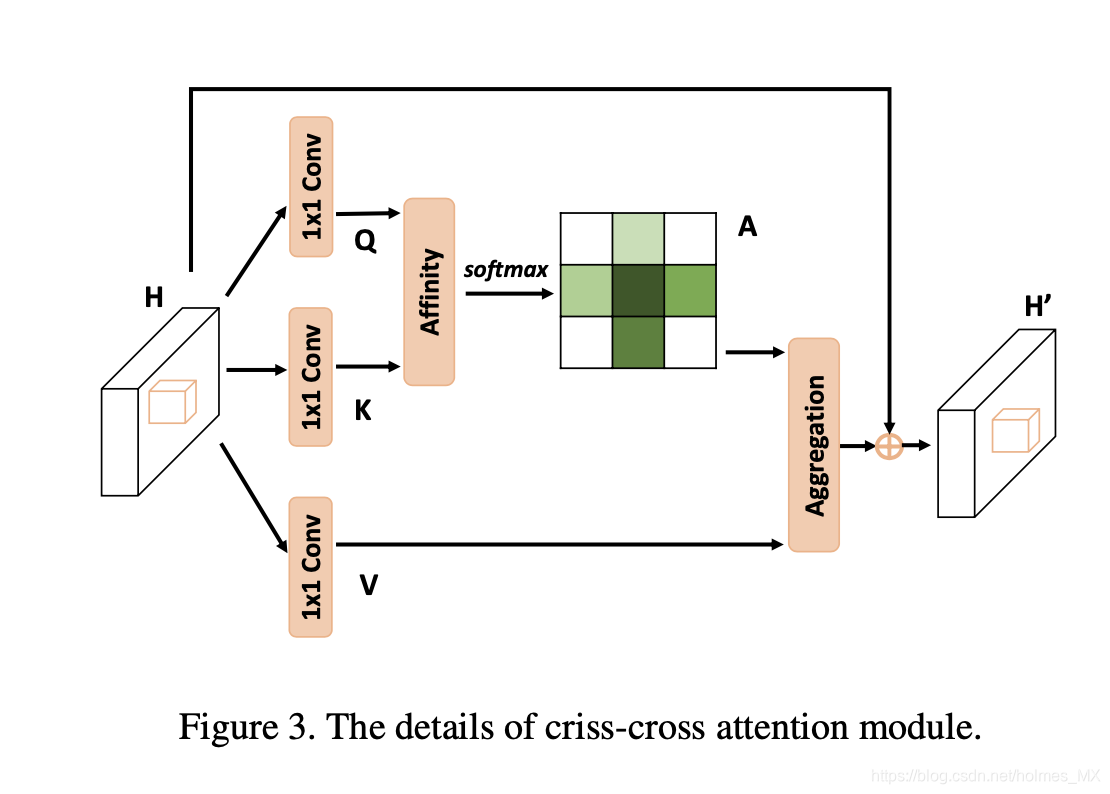
criss-cross attention module细节:
其中,Q, K 1*1得到的channel 为输出channel的1/8,V 的channel与输入channel相同。
3. 实验结果



注:文中图片来自于paper。
There may be some mistakes in this blog. So, any suggestions and comments are welcome!
[Reference]
1. paper: https://arxiv.org/pdf/1811.11721.pdf
2. code: https://github.com/speedinghzl/CCNet