XGboot
Xgboost是GBDT思想算法实现的一种,我们主要先讲一下原理推导,再到实现的细节。
优化的目标公式: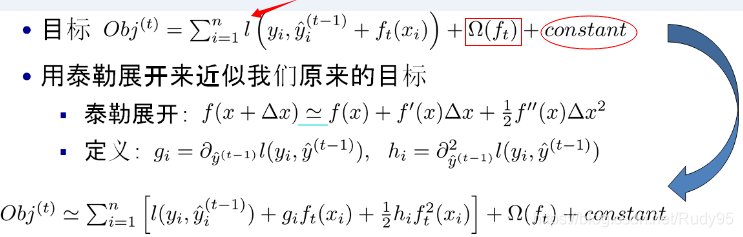
基于风险最小化,优化的目标函数=损失项+树的结构化约束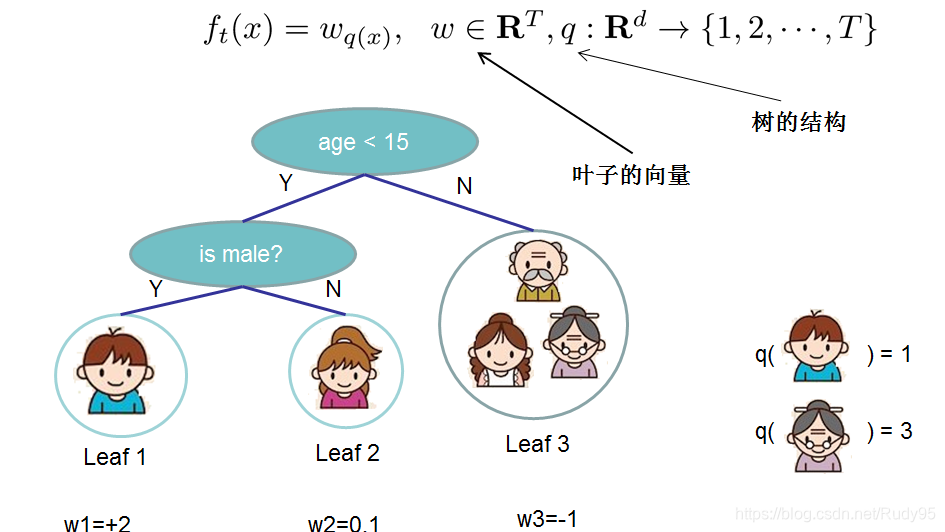
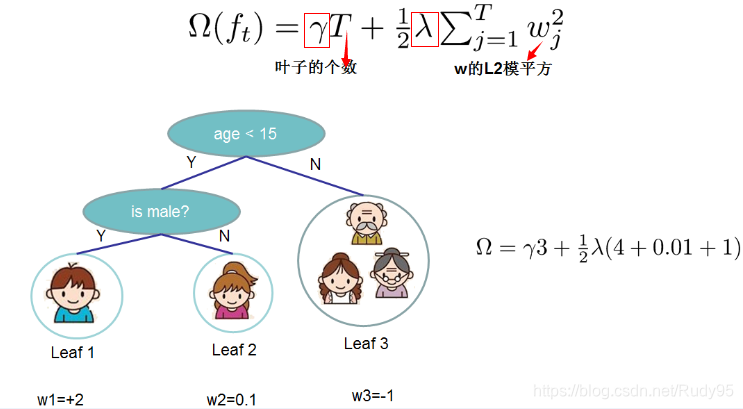
树的结构化主要有两部分组成:一个是树的叶子节点个数,第二个是每个叶子节点的权重,权重实质就是使每个叶子节点样本中损失最小的预测值(此前,楼主看了半天也不明白,这权重到底是啥)
——————————————————————————————————
为什么这里会对叶子节点的预测值进行L2正则呢?
主要是考虑到,XGBoost是多个树的线性组合,如果某一棵的预测权重非常大,则这颗树非常有可能过拟合。
——————————————————————————————————
现在,我们对上面优化目标进行优化,使用泰勒公式展开后,再求解令损失最小的权重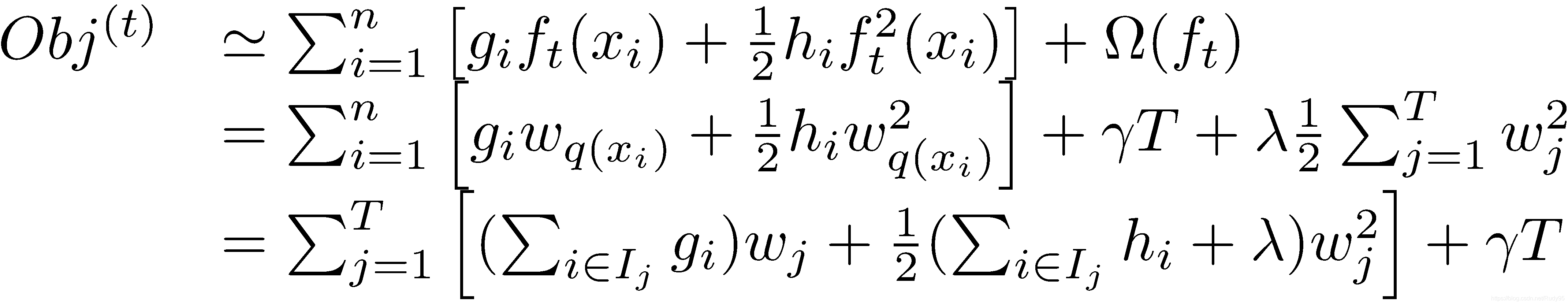
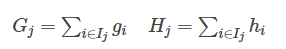
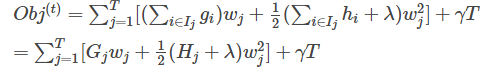
此时,我们对权重w求导: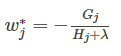
将w代入到原公式:
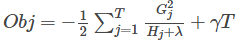
最终,目标函数越小,代表这棵树的结构越好。
搞定了目标优化,我们开始进行建树,分裂节点。
Xgboost是很多CART回归树集成
初始时,是单棵树树根,然后进行节点分裂。分裂到一定程度,形成一棵树,再创建第二颗树继续分裂,直到满足某种条件。
算法流程如下:
这里涉及到两个部分:节点分裂的方法,分裂/建树停止的条件。
- 节点分裂的方法
每次尝试对已有的叶子加入一个分割,因为cart树是二叉树,每次选取一个特征进行分割都会分割出左子树和右子树,得到分割后能产生的增益。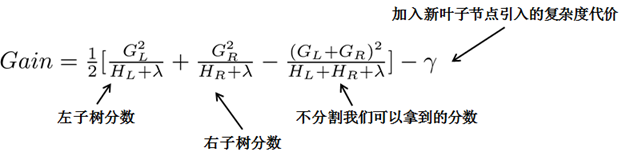
当增益小于某个阈值,可以不进行分割,类似预剪枝,或者设置最大深度参数,或者样本权重小于设定的阈值。
注意:
每次节点分裂,都是在子样本上进行分裂,因此计算loss的时候只有当前节点的子样本。
上面的分裂中,又出现了一个需要探讨的问题就是,如何快速的选取到最优的分割点呢?
方法一:
枚举特征上所有可能的分裂点,计算得分。算法图如下:
先要对特征上的取值进行排序,再遍历
首先,计算同层级节点可并行计算。
方法二:weighted Quantile Sketch(加权分位)方法
假设集合是x的第k个特征值以及对应集合上每个样本的二阶梯度: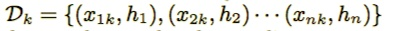
定义一个排序函数: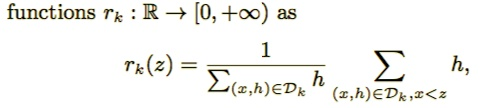
表示特征值k小于z的实例比例,现在寻找候选分裂集合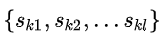
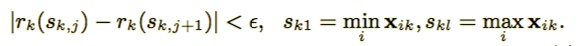
这里 ϵ \epsilonϵ是近似因子,这意味着有大概ϵ \epsilonϵ个候选点。这里每个数据点的权重为 hi。

针对稀疏数据:
导致稀疏值的原因,存在大量缺失值,太多0统计值,以及one-hot-encoding.
假设特征缺失样本分别属于右子树和左子树在不缺失的样本上迭代,然后计算各自增益,哪个大就放在哪。
算法流程如下:
防止过拟合的手段:
收缩和列采样
在防止模型过拟合方面,除了使用正则化项,收缩和列采样也经常使用。收缩规模在树提升的每一步迭代中通过因子逐步增加收缩权重,这和随机梯度下降的学习率相似。收缩技术降低了每一个单个的树和叶子节点对之后要学习的树结构的影响。列采样在随机森林中被使用,它除了能防止过拟合还能加快并行算法的计算速度。
——————————————————————————————————
关于XGBoost中分类问题是如何解决?
把每一个类作为拟合的对象,每个类都会有多个树,最终分类结果,是叶子节点中的子集做softmax取最大。
XGBoost中,每一棵树的输入是什么?
前面所有预测值的和
——————————————————————————————————
为什么XGBoost泰勒展开式二阶后效果比较好?
Xgboost使用二阶展开效果更好的原因,应该与牛顿法使用海塞矩阵比SGD好的原因一样。
(1)Xgboost官网上有说,当目标函数是MSE时,展开是一阶项(残差)+二阶项的形式(官网说这是一个nice form),而其他目标函数,如logloss的展开式就没有这样的形式。为了能有个统一的形式,所以采用泰勒展开来得到二阶项,这样就能把MSE推导的那套直接复用到其他自定义损失函数上。简短来说,就是为了统一损失函数求导的形式以支持自定义损失函数。这是从为什么会想到引入泰勒二阶的角度来说的二阶信息本身就能让梯度收敛更快更准确。(2)二阶信息本身就能让梯度收敛更快更准确。这一点在优化算法里的牛顿法里已经证实了。可以简单认为一阶导指引梯度方向,二阶导指引梯度方向如何变化。这是从二阶导本身的性质,也就是为什么要用泰勒二阶展开的角度来说的
——————————————————————————————————
这里写了很多解答,我说一下自己的理解吧,泰勒公式展开到二阶导,会与loss更加接近,因此,在迭代过程中,会收敛的更快。其次,泰勒公式展开到了二阶,会出现平方项,对于loss的形式也就变成了凸函数,求解极值。(如有不对,还希望大佬们指正)
总结一下XGB中的亮点:
w是最优化求解出来
支持自定义损失函数,只需要支持一阶,二阶导就可以
支持并行化,同层级的节点可并行,对于不同的特征的特征划分点,XGBoost分别在不同的线程中并行选择分裂的最大增益。
针对稀疏数据的处理
行采样,列采样
shrinkage
支持设置样本权重
XGBoost与GBDT对比:
(1)XGBOOST采用基学习器不但是CART,还可以是线性分类器
(2)在构建树寻找最佳分割点的时候,XGBoost采用与损失函数相关的增益最大化,而GBDT则是无论是什么损失函数,采用的标准都是最小化均方差。
是每一个基分类器去拟合前K个基学习器的一阶导数,采用的损失函数多种多样(Log Loss也好,softmax Loss也好),构造树这一过程采用的准则就是均方误差,分开看这两部分,前一部分采用的损失函数是为了衡量前K个基学习器线性组合好后这一整体的性能,第二部分的损失函数是为了衡量当前训练这一棵树(即第K+1颗树)的性能,GBDT某种程度上来讲独立了两部分,即不管前一部分采用什么损失函数,在训练当前这一棵树的时候都是采用最小化均方差(当然也可以是别的,但GBDT就是用来MSE这一损失函数),显然这没有联系,是不好的,Xgboost将两部分采用的损失函数联系了起来,即Xgboost建单个树采用的损失函数和第一部分是有联系的,不再拘泥于均小误差,抽象出各种损失函数一个表达式。
(3)目标函数不再像GBDT那样只是损失函数,XGBoost还加入了正则项
(4)XGBoost不仅采用了一阶导数信息还有二阶导数信息
(5)GBDT拟合的是负梯度
(6)传统的GBDT每一轮迭代使用全部数据,xgboost进行采样
(7)传统GBDT没有设计对缺失值的处理
XGBoost调参
XGBoost框架参数
对于XGBoost的框架参数,最重要的是3个参数: booster,n_estimators和objectve。
1) booster决定了XGBoost使用的弱学习器类型,可以是默认的gbtree, 也就是CART决策树,还可以是线性弱学习器gblinear以及DART。一般来说,我们使用gbtree就可以了,不需要调参。
2) n_estimators则是非常重要的要调的参数,它关系到我们XGBoost模型的复杂度,因为它代表了我们决策树弱学习器的个数。这个参数对应sklearn GBDT的n_estimators。n_estimators太小,容易欠拟合,n_estimators太大,模型会过于复杂,一般需要调参选择一个适中的数值。
3) objective代表了我们要解决的问题是分类还是回归,或其他问题,以及对应的损失函数。具体可以取的值很多,一般我们只关心在分类和回归的时候使用的参数。
在回归问题objective一般使用reg:squarederror ,即MSE均方误差。二分类问题一般使用binary:logistic, 多分类问题一般使用multi:softmax。
3.2 XGBoost 弱学习器参数
这里我们只讨论使用gbtree默认弱学习器的参数。 要调参的参数主要是决策树的相关参数如下:
1) max_depth: 控制树结构的深度,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,需要限制这个最大深度,具体的取值一般要网格搜索调参。这个参数对应sklearn GBDT的max_depth。
2) min_child_weight: 最小的子节点权重阈值,如果某个树节点的权重小于这个阈值,则不会再分裂子树,即这个树节点就是叶子节点。这里树节点的权重使用的是该节点所有样本的二阶导数的和,即XGBoost原理篇里面的Htj:
这个值需要网格搜索寻找最优值,在sklearn GBDT里面,没有完全对应的参数,不过min_samples_split从另一个角度起到了阈值限制。
3) gamma: XGBoost的决策树分裂所带来的损失减小阈值。也就是我们在尝试树结构分裂时,得到的增益要大于这个参数
subsample: 子采样参数,这个也是不放回抽样,和sklearn GBDT的subsample作用一样。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。初期可以取值1,如果发现过拟合后可以网格搜索调参找一个相对小一些的值。
5) colsample_bytree/colsample_bylevel/colsample_bynode: 这三个参数都是用于特征采样的,默认都是不做采样,即使用所有的特征建立决策树。colsample_bytree控制整棵树的特征采样比例,colsample_bylevel控制某一层的特征采样比例,而colsample_bynode控制某一个树节点的特征采样比例。比如我们一共64个特征,则假设colsample_bytree,colsample_bylevel和colsample_bynode都是0.5,则某一个树节点分裂时会随机采样8个特征来尝试分裂子树。
6) reg_alpha/reg_lambda: 这2个是XGBoost的正则化参数。reg_alpha是L1正则化系数,reg_lambda是L1正则化系数,
上面这些参数都是需要调参的,不过一般先调max_depth,min_child_weight和gamma。如果发现有过拟合的情况下,再尝试调后面几个参数。
XGBoost还有一些其他的参数需要注意,主要是learning_rate。
learning_rate控制每个弱学习器的权重缩减系数,和sklearn GBDT的learning_rate类似,较小的learning_rate意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参才有效果。当然也可以先固定一个learning_rate ,然后调完n_estimators,再调完其他所有参数后,最后再来调learning_rate和n_estimators。
一般来说使用网格搜索:
先后调参的步骤:
n_estimators
max_depth和min_child_weight
gamma
subsample和colsample_bytree
reg_alpha和reg_lambda
learning_rate
XGBoost中特征重要性计算:
提供了三种特征计算的方法,分别是:
weight:一个特征在所有树中用来进行分裂的的次数
gain: 特征在树中使用的平均增益
cover: 同一个特征被分到该节点的样本的二阶导数之和
参考链接:
https://zhuanlan.zhihu.com/p/31654000
https://blog.csdn.net/github_38414650/article/details/76061893
https://www.cnblogs.com/cupleo/p/9951436.html
https://blog.csdn.net/a819825294/article/details/51206410
https://blog.csdn.net/weixin_42001089/article/details/84965333
https://www.cnblogs.com/pinard/p/11114748.html