利用java代码删除ES索引、创建ES索引
public class createIndex {
public static void main(String[] args) throws Exception {
String user_id_types = args[0];
String tag_origin_short_name = args[1];
String dt = args[2];
StringBuilder mapping = new StringBuilder();
mapping.append("{\n" +
" \"settings\": {\n" +
" \"analysis\": {\n" +
" \"analyzer\": {\n" +
" \"mark\": {\n" +
" \"type\": \"pattern\",\n" +
" \"pattern\": \"[\\u0001|,]\"\n" +
" }\n" +
" }\n" +
" },\n" +
" \"index.mapping.nested_fields.limit\": \"6000\",\n" +
" \"index.mapping.total_fields.limit\": \"6000\",\n" +
" \"index.mapping.depth.limit\": \"6000\",\n" +
" \"number_of_shards\": 8,\n" +
" \"number_of_replicas\": 0,\n" +
" \"index.refresh_interval\": \"100s\",\n" +
" \"index.translog.durability\": \"async\",\n" +
" \"index.translog.flush_threshold_size\": \"1024mb\",\n" +
" \"index.translog.sync_interval\": \"100s\",\n" +
" \"index.merge.scheduler.max_thread_count\": 1,\n" +
" \"merge.policy.max_merged_segment\": \"2gb\",\n" +
" \"index.unassigned.node_left.delayed_timeout\": \"2880m\",\n" +
" \"index.routing.allocation.total_shards_per_node\": \"-1\"\n" +
" },\n" +
" \"mappings\": {\n" +
" \"_doc\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\",\n" +
" \"norms\": false\n" +
" },\n" +
" ");
mapping.append(XXXXX);
JSONObject jsonMapping = new JSONObject(mapping.toString());
System.out.println("ES索引名前缀_" + user_id_types.toString() + "_" + tag_origin_short_name.toString() + "_" + dt.toString() + "的mapping结构如下:" + "\n" + mapping.toString());
/*
以下为发送curl命令部分
*/
//1. 删除T+1的索引
//1. 预删除T+1的项目独立索引
String[] cmd1 = {"curl", "-u", "ES集群账号:ES集群密码", "-s", "-XDELETE", "ES集群域名:ES集群端口号/ES索引名前缀_" + user_id_types.toString() + "_" + tag_origin_short_name.toString() + "_" + dt.toString() + "?pretty"};
System.out.println("\n" + "1. 预删除T+1的项目独立索引: " + "DELETE /ES索引名前缀_" + user_id_types.toString() + "_" + tag_origin_short_name.toString() + "_" + dt.toString() + "?pretty");
sendCurl(cmd1);
//2. 创建T+1的项目独立索引
String[] cmd2 = {"curl", "-u", "ES集群账号:ES集群密码", "-s", "-XPUT", "-H", "Content-type:application/json", "-d", jsonMapping.toString(), "ES集群域名:ES集群端口号/ES索引名前缀_" + user_id_types.toString() + "_" + tag_origin_short_name.toString() + "_" + dt.toString() + "?pretty"};
System.out.println("\n" + "2. 创建T+1的项目独立索引: " + "PUT /ES索引名前缀_" + user_id_types.toString() + "_" + tag_origin_short_name.toString() + "_" + dt.toString() + "?pretty");
sendCurl(cmd2);
//关闭接口
System.exit(0);
}
public static void sendCurl(String[] cmd) {
ProcessBuilder pb = new ProcessBuilder(cmd);
pb.redirectErrorStream(true);
Process p;
try {
p = pb.start();
BufferedReader br = null;
String line = null;
br = new BufferedReader(new InputStreamReader(p.getInputStream()));
while ((line = br.readLine()) != null) {
System.out.println("\t" + line);
}
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}mapping拼接的索引结构
{
"settings": {
"analysis": {
"analyzer": {
"mark": {
"type": "pattern",
"pattern": "[\u0001|,]"
}
}
},
"index.mapping.nested_fields.limit": "6000",
"index.mapping.total_fields.limit": "6000",
"index.mapping.depth.limit": "6000",
"number_of_shards": 8,
"number_of_replicas": 0,
"index.refresh_interval": "100s",
"index.translog.durability": "async",
"index.translog.flush_threshold_size": "1024mb",
"index.translog.sync_interval": "100s",
"index.merge.scheduler.max_thread_count": 1,
"merge.policy.max_merged_segment": "2gb",
"index.unassigned.node_left.delayed_timeout": "2880m",
"index.routing.allocation.total_shards_per_node": "-1"
},
"mappings": {
"_doc": {
"properties": {
"id<这种格式可以避免id过长报错>": {
"type": "text",
"norms": false,
"analyzer": "mark",
"search_analyzer": "mark",
"fielddata": true,
"index_options": "docs"
},
"字段1": {
"type": "keyword",
"norms": false
},
"字段2": {
"type": "text",
"norms": false,
"analyzer": "mark",
"search_analyzer": "mark",
"fielddata": true,
"index_options": "docs"
},
"字段3": {
"type": "long",
"norms": false
},
"字段4": {
"type": "nested",
"properties": {
"cate": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"latest": {
"type": "keyword"
},
"tag_value": {
"type": "long"
}
}
}
}
}
}
}ps:index_options:索引选项,控制添加到倒排索引(Inverted Index)的信息,这些信息用于搜索(Search)和高亮显示:
- docs:只索引文档编号(Doc Number)
- freqs:索引文档编号和词频率(term frequency)
- positions:索引文档编号,词频率和词位置(序号)
- offsets:索引文档编号,词频率,词偏移量(开始和结束位置)和词位置(序号)
- 默认情况下,被分析的字符串(analyzed string)字段使用positions,其他字段使用docs;
此外,field为是否开启字段聚合,如果字段需要被聚合例如group by,则开启,设置为true;这货比较占用内存,所以不需要聚合的字段我们一般直接设置为false
norms为是否对该字段进行打分,不需要打分设置为false
因为我们的需求里倒排索引只需要检索出文档id,不需要统计词频和词位置序号,所以用的docs;
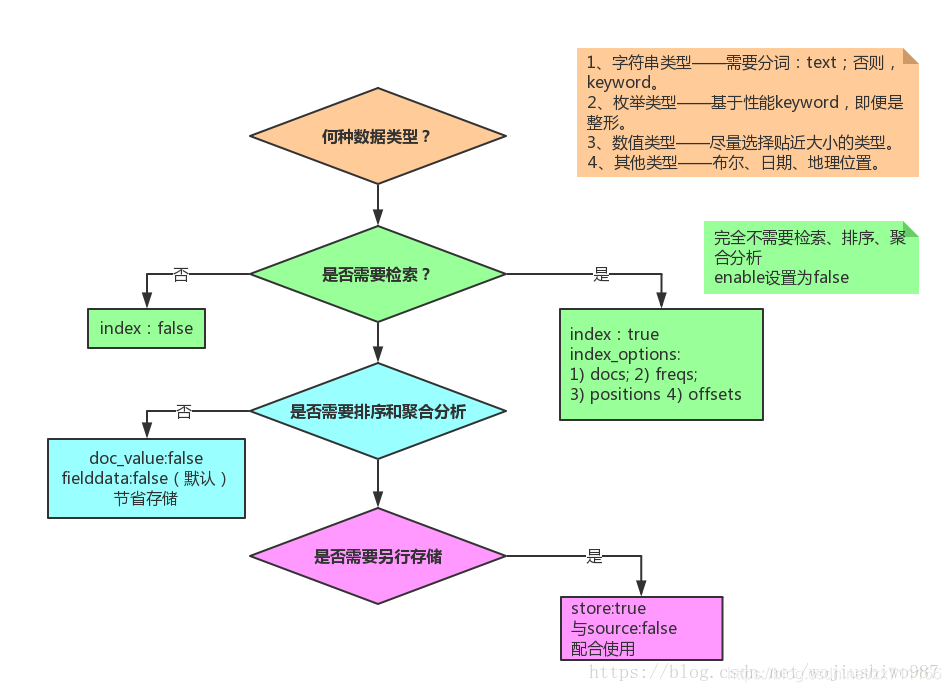
以上就是通过脚本调java程序,自动化创建索引和删除索引的流程
版权声明:本文为wx1528159409原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。