前言
今天小伙伴要我帮他改一个临床决策曲线图,我一看,这图好像有点不那么好看,画图函数是rmda包的plot_decision_curve(),我一看帮助文档,可以传入plot()函数的参数,但是我对plot函数又不太熟悉,倒腾了半天也没美化好(菜是原罪),本着不懂就放弃的原则,我决定用ggplot2去画。
下图一张数原函数化的,一张是ggplot2画的,仔细看,区别还是有的。
先看一下原函数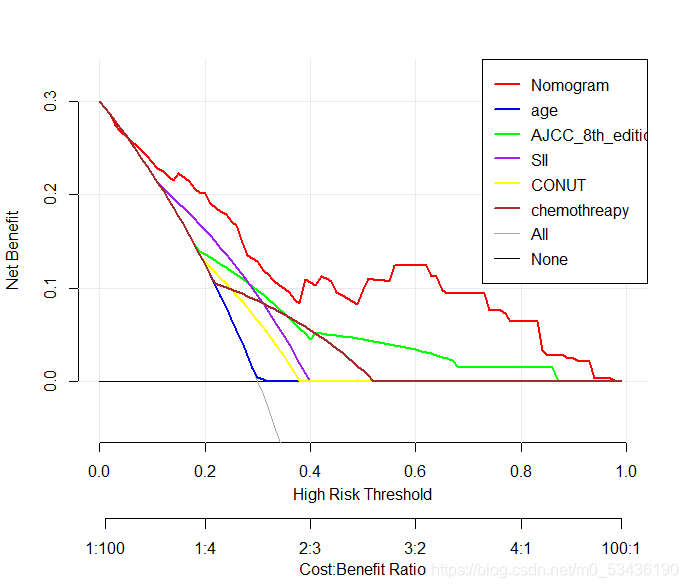
再看下ggplot2
一、观察数据
本着有坐标就能画图的大胆想法,我决定去看看模型中包含的数据。咦,这thresholds是从0到1的不就是横坐标吗?这NB不就是纵坐标吗?数据都有了说办就办。
二、步骤
1.从模型中提取模型的数据
ggplot2画图需要长数据类型,从一开始就构建好。里面设置的NBL,NBu,CBR没用到。一开始以为有用,害。。。
**提示:**这里面的Nomogram,age,AJCC_8th_edition,SII,CONUT,chemothreapy,是经过decision_curve函数得到的结果。例如:AJCC_8th_edition<- decision_curve(…)。需要生面这部分代码的请使用浏览器。
library(ggplot2)
library(RColorBrewer)
List<-list(Nomogram,age,AJCC_8th_edition,SII,CONUT,chemothreapy)
#为模型命名
names(List) <- c('Nomogram','age','AJCC_8th_edition','SII','CONUT','chemothreapy')
#经观察(踩坑)发现每个模型的303个数据数据分为3部分,只有前1/3是模型本身的,其余分别是All和None。
#因此设置一个长度,别让它读多了
l <- length(List[[1]][["derived.data"]][["NB"]])/3
#设置一个NA数据框用来循环取数据
dc <- data.frame('NBl'=rep(NA,l),
'NB'=rep(NA,l),
'NBu'=rep(NA,l),
'HRT'=rep(NA,l),
'CBR'=rep(NA,l),
'Model'=rep(NA,l))
#建立空数据框用来合并数据
dat <- data.frame()
for (i in names(List)) {
dc$NBl <- List[[i]][["derived.data"]][["NB_lower"]][1:l]
dc$NB<- List[[i]][["derived.data"]][["NB"]][1:l]
dc$NBu <- List[[i]][["derived.data"]][["NB_upper"]][1:l]
dc$HRT <- List[[i]][["derived.data"]][["thresholds"]][1:l]
dc$CBR <- List[[i]][["derived.data"]][["cost.benefit.ratio"]][1:l]
dc$Model <- rep(i,l)
#按行合并
dat <- rbind(dat,dc)
}
2.提取All和None数据
自己的模型数据取完了,但别忘了临床决策曲线中还有All和None两个,对同一数据建的模型All和None是一样的,所以这里就取第一个模型的All和None数据
#正经模型的数据取完了,现在取All和None的
dc$NBl <- List[[1]][["derived.data"]][["NB_lower"]][(2*l+1):(3*l)]
dc$NB<- List[[1]][["derived.data"]][["NB"]][(2*l+1):(3*l)]
dc$NBu <- List[[1]][["derived.data"]][["NB_upper"]][(2*l+1):(3*l)]
dc$HRT <- List[[1]][["derived.data"]][["thresholds"]][(2*l+1):(3*l)]
dc$CBR <- List[[1]][["derived.data"]][["cost.benefit.ratio"]][(2*l+1):(3*l)]
dc$Model <- rep('None',l)
dat <- rbind(dat,dc)
#去除NA,这是个坑,在每个模型最后一行数据取出来是NA,这里直接让它等于前一行的数据就行了
#dat[which(is.na(dat$NBl)),'CBR'] <- '100:1'#这一行画图没用到,纯粹强迫症
dat[which(is.na(dat$NBl)),1:3] <- dat[which(is.na(dat$NBl))-1,1:3]
#加入all
dc$NBl <- List[[1]][["derived.data"]][["NB_lower"]][(l+1):(2*l)]
dc$NB<- List[[1]][["derived.data"]][["NB"]][(l+1):(2*l)]
dc$NBu <- List[[1]][["derived.data"]][["NB_upper"]][(l+1):(2*l)]
dc$HRT <- List[[1]][["derived.data"]][["thresholds"]][(l+1):(2*l)]
dc$CBR <- List[[1]][["derived.data"]][["cost.benefit.ratio"]][(l+1):(2*l)]
dc$Model <- rep('All',l)
dat <- rbind(dat,dc)
#最后一行含NA值
dat <- dat[-nrow(dat),]
#去除负值较大的行(主要是all那个模型),咱们画图y轴-0.1就差不多得了
dat <- dat[dat$NB>-0.1,]
dat$Model <- factor(dat$Model,levels = rev(unique(dat$Model)))
3.画图
数据准备充分就画图了
##画图
#为咱的图选个好看的颜色
colorm <- c('grey','black',brewer.pal(length(unique(dat$Model))-2,'Dark2'))
#找一个y轴上限
lmax <- max(dat$NB)
#Cost:Benefit Ratio标签(这里基本上可以不变,因为x轴就那么长,没必要细化了)
cb <- data.frame(x=c(1/101,0.2,0.4,0.6,0.8,100/101),lab=c('1:100','1:4','2:3','3:2','4:1','100:1'))
#假x轴的标签(实际是画的一条线)
tik <- data.frame(x=c(0,0.2,0.4,0.6,0.8,1),
y=rep(-0.1,6))
ggplot()+
geom_line(data=dat,lwd=1.2,aes(x=HRT,y=NB,color=Model))+
scale_colour_manual(name='Model',values = colorm)+
scale_y_continuous(name = 'Net Benefit',breaks = seq(0,max(dat$NB),by=0.1),limits = c(-0.18,max(dat$NB)+0.1),expand = c(0,0))+
scale_x_continuous(name = 'Cost:Benefit Ratio',breaks =cb$x,expand = c(0.01,0),labels = cb$lab)+
geom_segment(aes(x=0,y=-0.1,xend=1,yend=-0.1),color='black',size=0.5)+
geom_segment(data=tik,aes(x=x,y=y,xend=x,yend=y-0.01))+
geom_text(tik,mapping = aes(x=x,y=-0.1,label=x),vjust=2.5)+
geom_text(data=NULL,aes(x=0.5,y=-0.1,label='High Risk Threshold'),colour = 'black',size=4,vjust=3.5)+
theme_bw()+
theme(panel.grid.minor = element_line(colour = NA),
legend.position=c(0.85,0.75),
legend.background = element_blank(),
#这个图例的边框如果调整不好的话建议删除
legend.box.background = element_rect(),
panel.border = element_rect(),
axis.title = element_text(size=12,colour = 'black'),
axis.text = element_text(size = 11,colour = 'black'))
3.汇总代码
library(ggplot2)
library(RColorBrewer)
List<-list(Nomogram,age,AJCC_8th_edition,SII,CONUT,chemothreapy)
#为模型命名
names(List) <- c('Nomogram','age','AJCC_8th_edition','SII','CONUT','chemothreapy')
#经观察(踩坑)发现每个模型的303个数据数据分为3部分,只有前1/3是模型本身的,其余分别是All和None。
#因此设置一个长度,别让它读多了
l <- length(List[[1]][["derived.data"]][["NB"]])/3
#设置一个NA数据框用来循环取数据
dc <- data.frame('NBl'=rep(NA,l),
'NB'=rep(NA,l),
'NBu'=rep(NA,l),
'HRT'=rep(NA,l),
'CBR'=rep(NA,l),
'Model'=rep(NA,l))
#建立空数据框用来合并数据
dat <- data.frame()
for (i in names(List)) {
dc$NBl <- List[[i]][["derived.data"]][["NB_lower"]][1:l]
dc$NB<- List[[i]][["derived.data"]][["NB"]][1:l]
dc$NBu <- List[[i]][["derived.data"]][["NB_upper"]][1:l]
dc$HRT <- List[[i]][["derived.data"]][["thresholds"]][1:l]
dc$CBR <- List[[i]][["derived.data"]][["cost.benefit.ratio"]][1:l]
dc$Model <- rep(i,l)
#按行合并
dat <- rbind(dat,dc)
}
#正经模型的数据取完了,现在取All和None的
dc$NBl <- List[[1]][["derived.data"]][["NB_lower"]][(2*l+1):(3*l)]
dc$NB<- List[[1]][["derived.data"]][["NB"]][(2*l+1):(3*l)]
dc$NBu <- List[[1]][["derived.data"]][["NB_upper"]][(2*l+1):(3*l)]
dc$HRT <- List[[1]][["derived.data"]][["thresholds"]][(2*l+1):(3*l)]
dc$CBR <- List[[1]][["derived.data"]][["cost.benefit.ratio"]][(2*l+1):(3*l)]
dc$Model <- rep('None',l)
dat <- rbind(dat,dc)
#去除NA,这是个坑,在每个模型最后一行数据取出来是NA,这里直接让它等于前一行的数据就行了
#dat[which(is.na(dat$NBl)),'CBR'] <- '100:1'#这一行画图没用到,纯粹强迫症
dat[which(is.na(dat$NBl)),1:3] <- dat[which(is.na(dat$NBl))-1,1:3]
#加入all
dc$NBl <- List[[1]][["derived.data"]][["NB_lower"]][(l+1):(2*l)]
dc$NB<- List[[1]][["derived.data"]][["NB"]][(l+1):(2*l)]
dc$NBu <- List[[1]][["derived.data"]][["NB_upper"]][(l+1):(2*l)]
dc$HRT <- List[[1]][["derived.data"]][["thresholds"]][(l+1):(2*l)]
dc$CBR <- List[[1]][["derived.data"]][["cost.benefit.ratio"]][(l+1):(2*l)]
dc$Model <- rep('All',l)
dat <- rbind(dat,dc)
#最后一行含NA值
dat <- dat[-nrow(dat),]
#去除负值较大的行(主要是all那个模型),咱们画图y轴-0.1就差不多得了
dat <- dat[dat$NB>-0.1,]
dat$Model <- factor(dat$Model,levels = rev(unique(dat$Model)))
##画图
#为咱的图选个好看的颜色
colorm <- c('grey','black',brewer.pal(length(unique(dat$Model))-2,'Dark2'))
#找一个y轴上限
lmax <- max(dat$NB)
#Cost:Benefit Ratio标签(这里基本上可以不变,因为x轴就那么长,没必要细化了)
cb <- data.frame(x=c(1/101,0.2,0.4,0.6,0.8,100/101),lab=c('1:100','1:4','2:3','3:2','4:1','100:1'))
#假x轴的标签(实际是画的一条线)
tik <- data.frame(x=c(0,0.2,0.4,0.6,0.8,1),
y=rep(-0.1,6))
ggplot()+
geom_line(data=dat,lwd=1.2,aes(x=HRT,y=NB,color=Model))+
scale_colour_manual(name='Model',values = colorm)+
scale_y_continuous(name = 'Net Benefit',breaks = seq(0,max(dat$NB),by=0.1),limits = c(-0.18,max(dat$NB)+0.1),expand = c(0,0))+
scale_x_continuous(name = 'Cost:Benefit Ratio',breaks =cb$x,expand = c(0.01,0),labels = cb$lab)+
geom_segment(aes(x=0,y=-0.1,xend=1,yend=-0.1),color='black',size=0.5)+
geom_segment(data=tik,aes(x=x,y=y,xend=x,yend=y-0.01))+
geom_text(tik,mapping = aes(x=x,y=-0.1,label=x),vjust=2.5)+
geom_text(data=NULL,aes(x=0.5,y=-0.1,label='High Risk Threshold'),colour = 'black',size=4,vjust=3.5)+
theme_bw()+
theme(panel.grid.minor = element_line(colour = NA),
legend.position=c(0.85,0.75),
legend.background = element_blank(),
#这个边框如果调整不好的话建议去除
legend.box.background = element_rect(),
panel.border = element_rect(),
axis.title = element_text(size=12,colour = 'black'),
axis.text = element_text(size = 11,colour = 'black'))
总结
回过头来再看,原函数画的图,稍显得松散,中部灰线虽然更直观的看出各个值的大小,但感觉有点像栅栏啊。
倘若大佬路过可以指点一下怎么在原函数的基础上调整成这个样子。我一定虚心接受,本着知难而退的精神,一定勤奋好学(第一次写这个,有点小紧张啊)。如有错误,各位要好好批评!!!!
如果各位有需求要改临床影响曲线(是不是这么叫的?)的话,留言,我会尽量更新。