C++ 多字节编码与Unicode编码
前言
任何“物种”都有自己独特的语言和交流方式,计算机也不例外。计算机有计算机的语言,就是机器语言,也就是二进制,0和1。那怎么把其它语言翻译成机器语言呢,比如人的语言,那就需要一个字典—ASCII。比如 00100001 代表 “!”, 00100001是机器可以识别的ASCII码, "!"是代表的人可以识别的字符。
因为ASIIC码有8位数,每位是一个比特 (bit),8位就是一个字节 (byte)。除了第一位是0, 其他7位都可以有0 或者 1 两个选择,所以ASCII 一共可以表示 2^7 ,也就是128个字符。包括a-z 大小写,0-9 数字 和一些标点符号等。其中真正可读的只有95 个字符,其他的都是一些控制符,比如NUL,代表NULL。
对于英语来说, ASCII 包括所有的字母了。但是随着计算机的发展,世界各地都开始使用计算机,但是很多国家用的不是英语,于是就开始给127之后的状态进行编码,从128到255这一页的字符集被称为扩展字符集。
对于一些国家256种字节状态还是满足不了需要,比如中国的汉字有十万多,常用的也要6000,聪明的中国人民就对ASCII进行了中文扩展,使用了双字节编码的方式对汉字进行了编码,我们叫做“GB2312”。之后又对GB2312进行了扩展,增加了一些不常用字符,形成了“GBK”标准。后来又在GBK基础上增加了少数民族的字符,GBK扩展成了“GB18030”。
类似于中国,其它国家也相应的制定了自己的编码标准,比如BIG5等,这样的结果就是不同的编码之间谁也不懂谁的编码。如果你在中国使用计算机编写了一份中文文档,拿到韩国打开就成乱码了。于是一些组织就开始着手统一编码格式,然后就出现了Unicode和USC字符集。
一. 什么是字符集(Charcater Set)与字符编码(Encoding)?
字符集(Charcater Set或Charset):是一个系统支持的所有抽象字符的集合,也就是一系列字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。常见的字符集有:ASCII字符集、GB2312字符集(主要用于处理中文汉字)、GBK字符集(主要用于处理中文汉字)、Unicode字符集等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个字符集(如字母表或音节表),与计算机能识别的二进制数字进行配对。即它能在符号集合与数字系统之间建立对应关系,是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息,而计算机的信息处理系统则是以二进制的数字来存储和处理信息的。字符编码就是将符号转换为计算机能识别的二进制编码。
一般一个字符集等同于一个编码方式,ANSI体系(ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符)的字符集如ASCII、ISO 8859-1、GB2312、GBK等等都是如此。一般我们说一种编码都是针对某一特定的字符集。
一个字符集上也可以有多种编码方式,例如UCS字符集(也是Unicode使用的字符集)上有UTF-8、UTF-16、UTF-32等编码方式。
从计算机字符编码的发展历史角度来看,大概经历了三个阶段:
第一个阶段:ASCII字符集和ASCII编码。
计算机刚开始只支持英语(即拉丁字符),其它语言不能够在计算机上存储和显示。ASCII用一个字节(Byte)的7位(bit)表示一个字符,第一位置0。后来为了表示更多的欧洲常用字符又对ASCII进行了扩展,又有了EASCII,EASCII用8位表示一个字符,使它能多表示128个字符,支持了部分西欧字符。
第二个阶段:ANSI编码(本地化)
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
第三个阶段:UNICODE(国际化)
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。UNICODE 常见的有三种编码方式:UTF-8(1个字节表示)、UTF-16((2个字节表示))、UTF-32(4个字节表示)。
我们可以用一个树状图来表示由ASCII发展而来的各个字符集和编码的分支: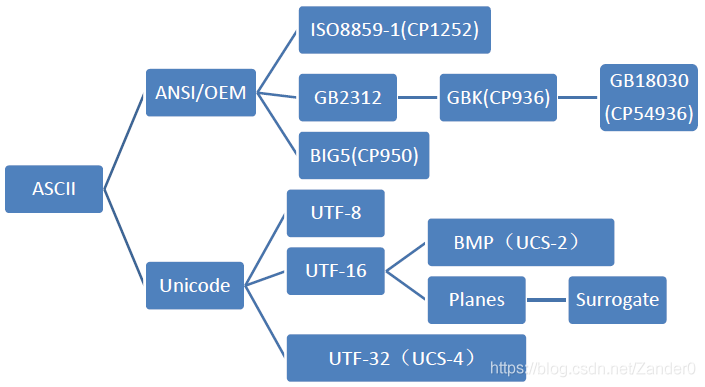
二. 不同字符集的区别
1. 不同字符集
单字节字符集:顾名思义,单字节字符集就是用一个字节表示一个字符,简称SBCS。ASCII就是单字节字符集。在编码的过程中char类型就是单字节编码。
Unicode字符集:前面已经介绍什么是Unicode字符集了。默认编码是USC-2,即所有的字符都是固定的使用2个字节进行编码。因为比单字节字符宽,所有又叫宽字节编码。宽字节编码有很多,Unicode编码只是宽字节编码中的一种实现方式,其它的比如:USC-4。
多字节字符集:指使用多个字节表示一个字符,其实就是ANSI编码。有的字符使用一个字节,如ASCII字符,有的字符使用多个字节表示,如中文。英文名简称MBCS,由于Windows里使用的多字节字符绝大部分是两个字节,所以MBCS常被用DBCS(双字节字符)代替。
2. 优缺点
| 优点 | 缺点 | |
|---|---|---|
| 使用Unicode字符集 | 查找速度快 | 内存占用大 |
| 使用多字节字符集 | 节省内存 | 每次查找需要确定字符的具体占有字节数,效率低 |
另外Unicode是国际通用的字符集,所以很容易在不同字符集之间进行转换,有利于软件的国际化。
三. char与wchar_t、string 与 wstring
1. char与wchar_t
我们知道C++基本数据类型中表示字符的有两种:char、wchar_t。
char叫多字节字符,一个char占一个字节,之所以叫多字节字符是因为它表示一个字时可能是一个字节也可能是多个字节。一个英文字符(如’s’)用一个char(一个字节)表示,一个中文汉字(如’中’)用3个char(三个字节)表示,看下面的例子。
void TestChar()
{
char ch1 = 's'; // 正确
cout << "ch1:" << ch1 << endl;
char ch2 = '中'; // 错误,一个char不能完整存放一个汉字信息
cout << "ch2:" << ch2 << endl;
char str[4] = "中"; //前三个字节存放汉字'中',最后一个字节存放字符串结束符\0
cout << "str:" << str << endl;
//char str2[2] = "国"; // 错误:'str2' : array bounds overflow
//cout << str2 << endl;
}
结果如下:
ch1:s
ch2:
str:中
wchar_t被称为宽字符,一个wchar_t占2个字节。之所以叫宽字符是因为所有的字都要用两个字节(即一个wchar_t)来表示,不管是英文还是中文。看下面的例子:
void TestWchar_t()
{
wcout.imbue(locale("chs")); // 将wcout的本地化语言设置为中文
wchar_t wch1 = L's'; // 正确
wcout << "wch1:" << wch1 << endl;
wchar_t wch2 = L'中'; // 正确,一个汉字用一个wchar_t表示
wcout << "wch2:" << wch2 << endl;
wchar_t wstr[2] = L"中"; // 前两个字节(前一个wchar_t)存放汉字'中',最后两个字节(后一个wchar_t)存放字符串结束符\0
wcout << "wstr:" << wstr << endl;
wchar_t wstr2[3] = L"中国";
wcout << "wstr2:" << wstr2 << endl;
}
结果如下:
ch1:s
ch2:中
str:中
str2:中国
注:
- 用常量字符给wchar_t变量赋值时,前面要加L。如: wchar_t wch2 = L’中’;
- 用常量字符串给wchar_t数组赋值时,前面要加L。如: wchar_t wstr2[3] = L"中国";
- 如果不加L,对于英文可以正常,但对于非英文(如中文)会出错。
2. string与wstring
字符数组可以表示一个字符串,但它是一个定长的字符串,我们在使用之前必须知道这个数组的长度。为方便字符串的操作,STL为我们定义好了字符串的类string和wstring。大家对string肯定不陌生,但wstring可能就用的少了。
string是普通的多字节版本,是基于char的,对char数组进行的一种封装。
wstring是Unicode版本,是基于wchar_t的,对wchar_t数组进行的一种封装。
3. string与wstring转换
以下的两个方法是跨平台的,可在Windows下使用,也可在Linux下使用。
#include <cstdlib>
#include <string.h>
#include <string>
// wstring => string
std::string WString2String(const std::wstring& ws)
{
std::string strLocale = setlocale(LC_ALL, "");
const wchar_t* wchSrc = ws.c_str();
size_t nDestSize = wcstombs(NULL, wchSrc, 0) + 1;
char *chDest = new char[nDestSize];
memset(chDest,0,nDestSize);
wcstombs(chDest,wchSrc,nDestSize);
std::string strResult = chDest;
delete []chDest;
setlocale(LC_ALL, strLocale.c_str());
return strResult;
}
// string => wstring
std::wstring String2WString(const std::string& s)
{
std::string strLocale = setlocale(LC_ALL, "");
const char* chSrc = s.c_str();
size_t nDestSize = mbstowcs(NULL, chSrc, 0) + 1;
wchar_t* wchDest = new wchar_t[nDestSize];
wmemset(wchDest, 0, nDestSize);
mbstowcs(wchDest,chSrc,nDestSize);
std::wstring wstrResult = wchDest;
delete []wchDest;
setlocale(LC_ALL, strLocale.c_str());
return wstrResult;
}
四. 理解_T()、_Text()宏即L“ ”
除了使用L”Title”外,还可以使用_T(“Title”)和_TEXT(“Title”)。而且你会发现在MFC和Win32程序中会更多地使用_T和_TEXT,那_T、_TEXT和L之间有什么区别呢?
通过上述我们知道表示多字节字符(char)串常量时用一般的双引号括起来就可以了,如”String test”;而表示宽字节字符(wchar_t)串常量时要在引号前加L,如L”String test”。
查看tchar.h头文件的定义我们知道_T和_TEXT的功能是一样的,是一个预定义的宏。
#define _T(x) __T(x)
#define _TEXT(x) __T(x)
我们再看看__T(x)的定义,发现它有两个:
#ifdef _UNICODE
// ... 省略其它代码
#define __T(x) L ## x
// ... 省略其它代码
#else /* ndef _UNICODE */
// ... 省略其它代码
#define __T(x) x
// ... 省略其它代码
#endif /* _UNICODE */
这下明白了吗?当我们的工程的Character Set设置为Use Unicode Character Set时_T和_TEXT就会在常量字符串前面加L,否则(即Use Multi-Byte Character Set时)就会以一般的字符串处理。实现是通过我们右键在项目属性中选择 “使用多字节字符集” 或者 “使用Unicode字符集”时,VS在“C++ -> 预处理器”中增加了宏定义,分别是 _MBCS 和 _UNICODE,注意 _MBCS和 _UNICODE 是相互排斥的。
之所以能实现,主要通过编译器来实现,通过使用条件编译#ifdef _UNICODE(有下划线) 来对 替代名称 的不同定义。有Windows编码经验的人可能发现了,还有一个UNICODE宏,很多的定义跟_UNICODE是一样的,这是为什么呢?UNICODE是Windows 提供的宏,Windows有一些系统API也要用到字符串,但是C库没有,比如:SetWindowText()和MessageBox()等,微软就对_UNICODE进行了重写和扩展,但是本质是一样,都是为了方便处理两种编码程序。
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif // !UNICODE
五. Dword、LPSTR、LPWSTR、LPCSTR、LPCWSTR、LPTSTR、LPCTSTR
还有一些常用的宏你也许会范糊涂,如Dword、LPSTR、LPWSTR、LPCSTR、LPCWSTR、LPTSTR、LPCTSTR。解释如下:
L表示long指针,这是为了兼容Windows 3.1等16位操作系统遗留下来的,在win32中以及其他的32为操作系统中, long指针和near指针及far修饰符都是为了兼容的作用,没有实际意义。即win32中,long,near,far指针与普通指针没有区别,LP 与P是等效的。
P表示这是一个指针。
T表示_T宏,这个宏用来表示你的字符是否使用UNICODE, 如果你的程序定义了UNICODE或者其他相关的宏,那么这个字符或者字符串将被作为UNICODE字符串,否则就是标准的ANSI字符串。
STR表示这个变量是一个字符串。
C表示是一个常量,const。
LPTSTR: 如果定义了UNICODE宏则LPTSTR被定义为LPWSTR。typedef LPTSTR LPWSTR;
否则LPTSTR被定义为LPSTR。 typedef LPTSTR LPSTR;
这里我们统一总结一下:
| 类型 | MBCS | UNICODE |
|---|---|---|
| WCHAR | wchar_t | wchar_t |
| LPSTR | char* | char* |
| LPCSTR | const char* | const char* |
| LPWSTR | wchar_t* | wchar_t* |
| LPCWSTR | const wchar_t* | const wchar_t* |
| TCHAR | char | wchar_t |
| LPTSTR | TCHAR*(或char*) | TCHAR*(或wchar_t*) |
| LPCTSTR | const TCHAR* | const TCHAR* |
相互转换方法: (MFC库,atlconv.h)
LPWSTR->LPTSTR: W2T();
LPTSTR->LPWSTR: T2W();
LPCWSTR->LPCSTR: W2CT();
LPCSTR->LPCWSTR: T2CW();
ANSI->UNICODE: A2W();
UNICODE->ANSI: W2A();