
1.Client向RM提交请求,上传jar包到HDFS上
2.RM在集群中选择一个NM,在其上启动AppMaster,在AppMaster中实例化SparkContext(Driver)
3.AppMaster向RM注册应用程序并申请资源。RM监控AppMaster的状态直到AppMaster结束。
4.AppMaster申请到资源后,与NM通信在Container中启动Executor进程
5.Executor向driver反向注册,申请任务
6.Driver对应用进行解析,最后将Task发送到Executor上
7.Executor中执行Task,并将执行结果或状态汇报给Driver
8.应用执行完毕,AppMaster通知RM注销应用,回收资源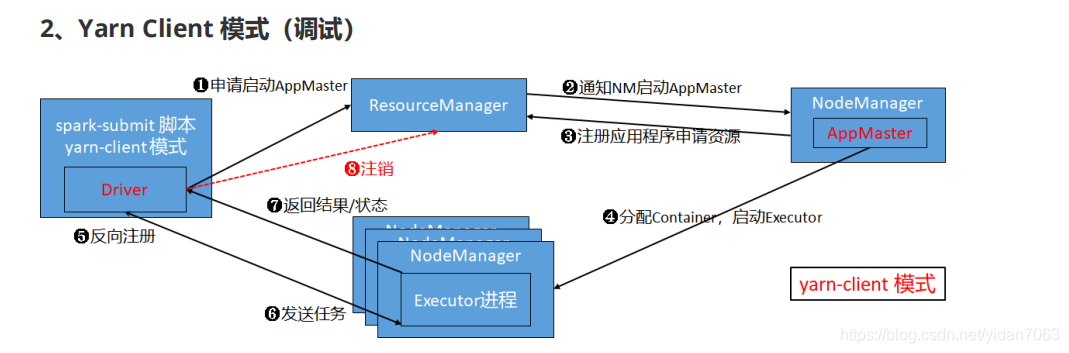
Client模式和cluster模式是差不多的。区别在于:Client的driver初始化在yarn-client端而不是AppMaster中。
1.启动应用程序实例化SparkContext,向RM申请启动AppMaster
2.RM在集群中选择一个NM,在其上启动AppMaster
3.AppMaster向RM注册应用程序并申请资源。RM监控AppMaster的状态直到AppMaster结束。
4.AppMaster申请到资源后,与NM通信在Container中启动Executor进程
5.Executor向driver反向注册,申请任务
6.Driver对应用进行解析,最后将Task发送到Executor上
7.Executor中执行Task,并将执行结果或状态汇报给Driver
8.应用执行完毕,AppMaster通知RM注销应用,回收资源
3.作业提交的细节
名词说明:
Job是以 Action 方法为界,遇到一个 Action 方法则触发一个 Job;
Stage是 Job 的子集,以 RDD 宽依赖(即 Shuffle)为界,遇到 Shuffle 做一次划分;
Task是 Stage 的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个 task。
Spark在接受到提交的job后,会进行以下处理:
总体来说分两路进行,一路是 Stage 级的调度,一路是 Task 级的调度,总体调度流程如下图所示: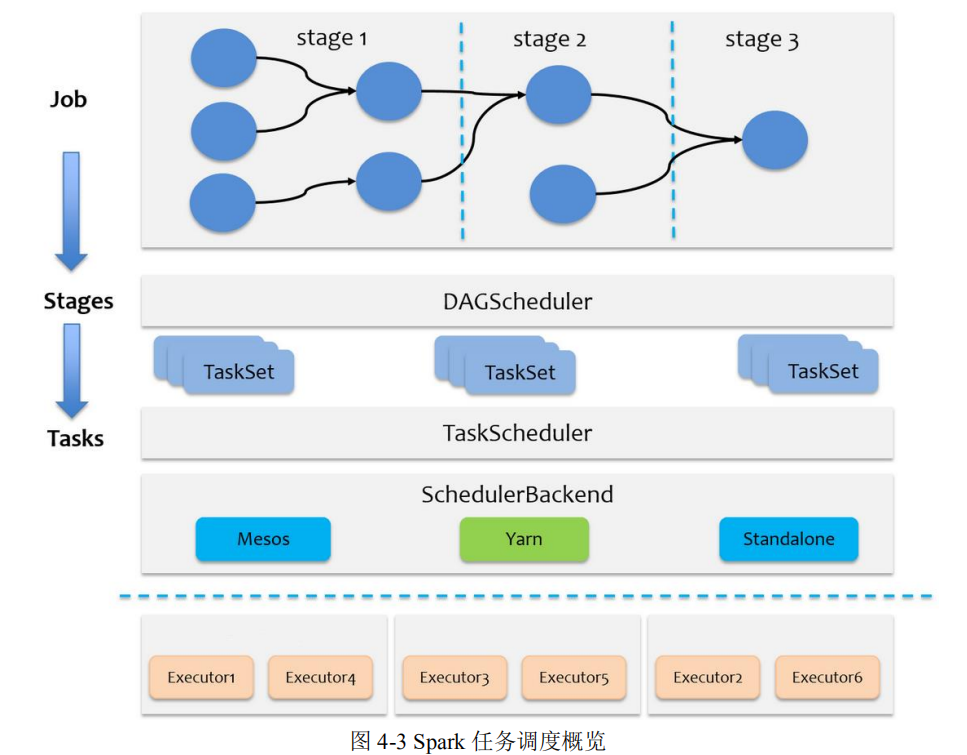
(1)Spark RDD 通过其 Transactions 操作,形成了 RDD 血缘关系图,即 DAG。依赖关系的分析和判断由DAGSchedule负责。
(2)根据DAG的分析结果将一个作业分成多个Stage(宽依赖)。
(3)DAGSchedule在确定完stage后,会向TaskSchedule提交任务集(TaskSet),而TaskSchedule负责将这些任务一一分发到集群的计算节点(Exector)。
(4)调度过程中 SchedulerBackend 负责提供可用资源,其中 SchedulerBackend有多种实现,分别对接不同的资源管理系统。
第二个总图:作业提交执行期的函数调用

重新在看yarn的提交 重点是sparkContext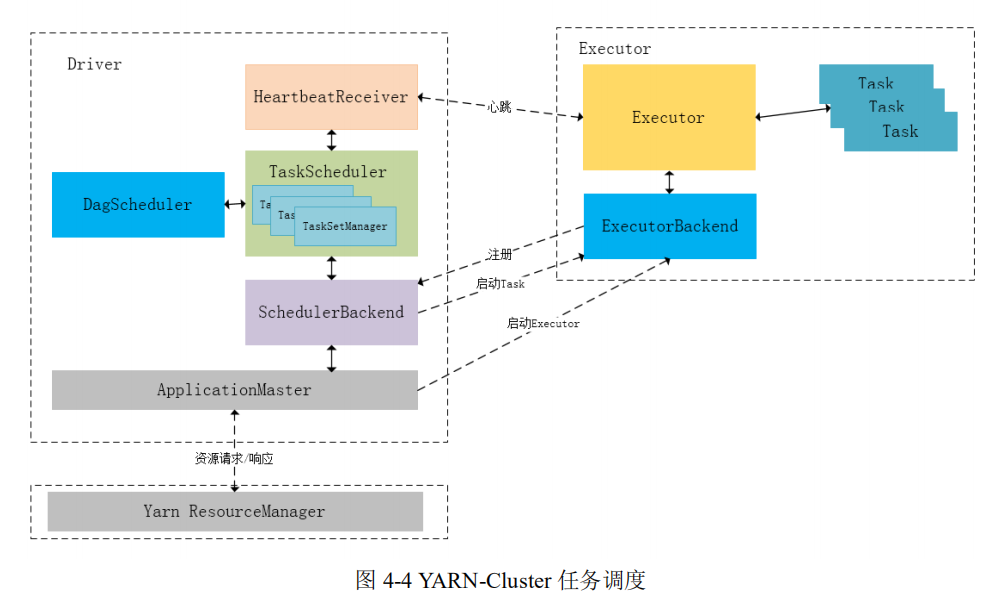
Driver 初始化 SparkContext 过 程 中 , 会 分 别 初 始 化 DAGScheduler 、 TaskScheduler、SchedulerBackend 以及 HeartbeatReceiver,并启动 SchedulerBackend 以及 HeartbeatReceiver。SchedulerBackend 通过 ApplicationMaster 申请资源,并不断从 TaskScheduler 中拿到合适的 Task 分发到 Executor 执行。HeartbeatReceiver 负责接收 Executor 的心跳信息,监控 Executor 的存活状况,并通知到 TaskScheduler。
4.Spark Stage 级调度
从上面已经知道了DAGScheduler 、 TaskScheduler、SchedulerBackend的作用,然后继续看细节问题。
DAG的形成比较简单通过RDD之间的血缘关系就可以完成构建。
这里关注Stage是如何切分的:
stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行(并行数量和core一致),整个作业按照stage顺序依次执行,最终完成整个Job。实际应用提交的Job中RDD依赖关系是十分复杂的,依据这些依赖关系来划分stage自然是十分困难的,Spark此时就利用了前文提到的依赖关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到ShuffleDependency(宽依赖关系的一种叫法)就断开,遇到NarrowDependency就将其加入到当前stage。stage中task数目由stage末端的RDD分区个数来决定。
从这里知道了stage是如何切分的,再看看stage是如何被提交运行的
下图是涉及到 Job 提交的相关方法调用流程图。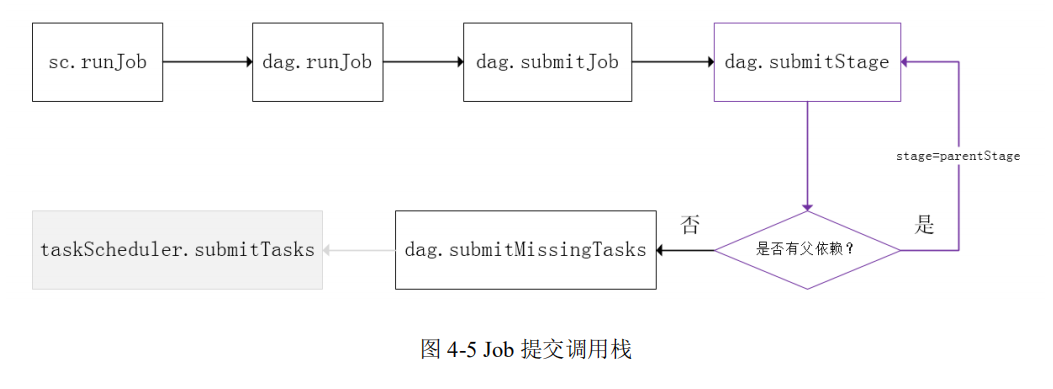
刚刚已经划分完stage了,然后对划分完成的stage进行分类。Stages 分两类, 一类叫做 ResultStage,为 DAG 最下游的 Stage,由 Action 方法决定(也就是Action算子),另一类叫做 ShuffleMapStage,为下游Stage 准备数据。以WordCount为例看stage的划分和分类:可以看到在reduceByKey这里就出现了stage的划分以及stage的分类。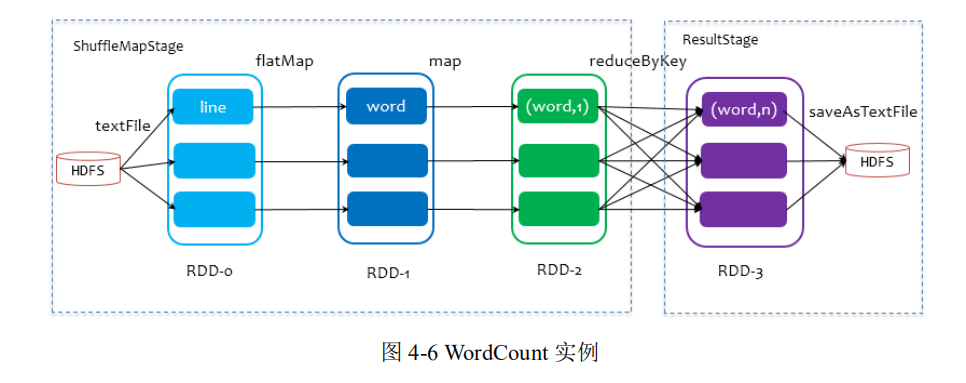
划分完stage的分类后,在看stage的提交。和stage的划分一样,stage的提交也是从后往前判断。一个 Stage 是否被提交,需要判断它的父 Stage 是否执行,只有在父 Stage 执行完毕才能提交当前 Stage,如果一个 Stage 没有父 Stage,那么从该 Stage开始提交。 Stage 提交时会将 Task 信息(分区信息以及方法等)序列化并被打包成 TaskSet 交给 TaskScheduler,一个 Partition对应一个 Task,另一方面 TaskScheduler 会监控 Stage 的运行状态,只有 Executor 丢失或者 Task 由于 Fetch 失败才需要重新提交失败的 Stage 以调度运行失败的任务,其他类型的 Task失败会在 TaskScheduler的调度过程中重试。
到这里作业提交执行期的函数调用总图就进行到scheduleBackend,由scheduleBackend提供资源然后TaskScheduler调度任务。
5.Spark Task 级调度
DAGScheduler 将Stage打包到TaskSet交给TaskScheduler,TaskScheduler会将TaskSet 封装为TaskSetManager加入到调度队列中,TaskSetManager 结构如下图所示:
TaskScheduler初始化后会启动SchedulerBackend。(在 SparkContext 源码中) SchedulerBackend负责跟外界打交道,接收 Executor 的注册,维护Executor的状 态。 SchedulerBackend是管“资源”(Executor)的,它在启动后会定期地去“询问” TaskScheduler 有没有任务要运行。 TaskScheduler在SchedulerBackend “问”它的时候,会从调度队列中按照指定的调度策略选择 TaskSetManager去调度运行,大致方法调用流程如下图所示:
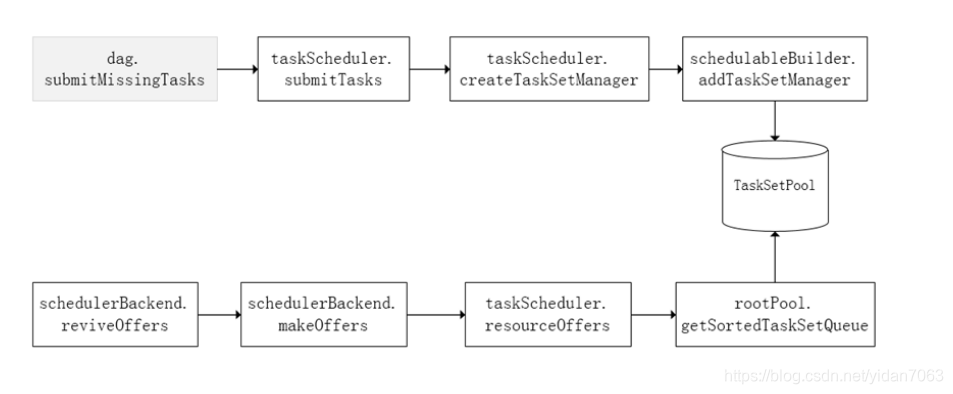
任务的执行是launchTasks() 向CoarseGrainedExecutorBackend发送LaunchTask消息。 CoarseGrainedExecutorBackend将在收到LaunchTask消息后运行Task。需要注意的是LaunchTask消息被Execute接收,Execute会使用LunchTask对该消息进行处理。 如果此时的execute没有注册到Driver上那么即便收到了LunchTask指令也不会做任何处理 。


TaskScheduler 支持两种调度策略: FIFO( 默认调度策略 ) 、 FAIR。
- runningTasks值(正在运行的Task数)
- minShare值(时间)
- weight值(权重)
调度池在构建阶段会先读取 fairscheduler.xml ($SPARK_HOME/conf)文件的相关配置,然后进行比较:
- 如果A对象的 runningTasks > minShare,B对象的 runningTasks < minShare,那么B排在A前面;(runningTasks比minShare小的先执行)
- 如果A、B对象的 runningTasks < minShare,那么就比较 runningTasks 与 minShare 的比值,谁小谁排前面;(使用率低的先执行)
- 如果A、B对象的 runningTasks > minShare,那么就比较runningTasks与 weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行)
- 如果上述比较均相等,则比较名字
从调度队列中拿到 TaskSetManager 后,由于 TaskSetManager 封装了一个 Stage 的所有 Task,并负责管理调度这些 Task,那么接下来的工作就是 TaskSetManager 按照一定的规则一个个取出 Task 给 TaskScheduler,TaskScheduler 再交给 SchedulerBackend ,最终分发到Executor上执行。
7.本地化调度
- DAGScheduler切割Job,划分Stage。调用submitStage来提交一个Stage对应的 tasks,submitStage会调用submitMissingTasks,submitMissingTasks 确定每个需要计算的 task的 preferred Locations
- 通过调用 getPreferrdeLocations 得到分区的优先位置,一个partition对应一个 task,此分区的优先位置就是task的优先位置
- 从调度队列中拿到 TaskSetManager 后,那么接下来的工作就是 TaskSetManager 按照一定的规则一个个取出 task 给 TaskScheduler, TaskScheduler 再交给 SchedulerBackend 发送到 Executor 上执行
- 根据每个 task 的优先位置,确定 task 的 Locality 级别,Locality一共有五种, 优先级由高到低顺序
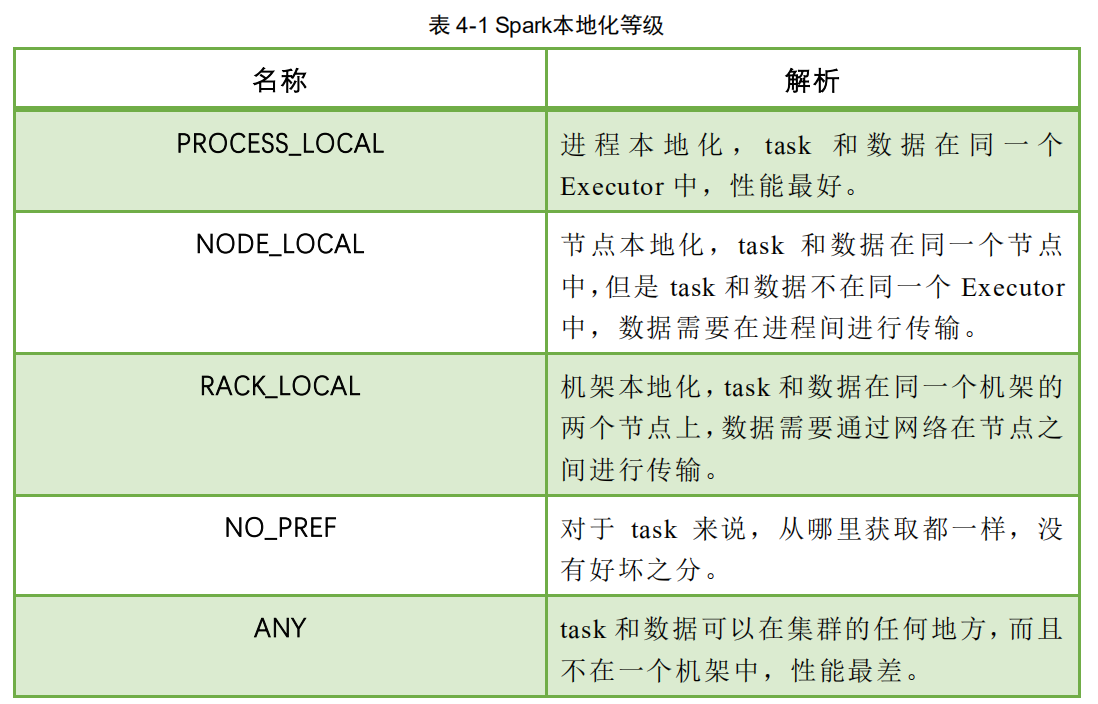
在调度执行时,Spark 调度总是会尽量让每个 task 以最高的本地性级别来启动, 当一个 task 以 X 本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资 源而启动失败,此时并不会马上降低本地性级别启动而是在某个时间长度内再次以 X 本地性级别来启动该 task,若超过限时时间则降级启动,去尝试下一个本地性级 别,依次类推。 可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的 Executor 可能 就会有相应的资源去执行此 task,这就在在一定程度上提到了运行性能
到此任务就已经提交到execute上执行了,往下看Task在执行后是如何做的。
8.Task结果返回
Task在执行时,会有大量的数据交互,这些数据可以分成3种不同的类型:
- 状态相关,如StatusUpdate
- 中间结果
- 计量相关的数据Metrices Data
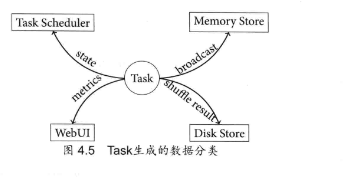
ShuffleMapTask需要返回MapStatus,而ResultTask只需要告知是否已经完成执行。
ScheduleBackend接收到StatusUpdate后会做如下判断:如果任务已经成功处理,则将其从监视的列表中删除。如果整个作业中的所有任务都已经完成,则将占用的资源释放。TaskScheduleImpl将当前顺利完成的任务放入完成队列,同时取出下一个等待运行的Task。
DAGSchedule中的HandlerTaskCompletion,针对ResultTask和ShuffleMapTask会有区别对待。如果ResultTask执行成功,则DAGSchedule会发出TaskSuccess来通知对整个作业情况感知的监听者,如JobWaiter。JobWaiter中的taskSucceeded函数会根据当前已经完成的任务数之和是否等于事先提交的任务总数来判断整个作业执行结束与否。
如果整个成功结束,此时awaitResult结束等待。
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
//收到job的运行结果
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
9.返回结果
对于Executor的计算结果,会根据结果的大小使用不同的处理策略:可配置
- 计算结果在(0,200KB-128MB)区间内:通过Netty直接发送给Driver终端
- 计算结果在[128MB,1GB]区间内:将结果以taskId为编号存入到 BlockManager 中,然后通过Netty把编号发送给Driver;阈值可通过Netty 框架传输参数设置
- 计算结果在(1GB,∞)区间内:直接丢弃,可通过
10.失败重试与黑名单机制
Task被提交到Executor启动执行后,Executor会将执行状态上报给 SchedulerBackend(DriverEndpoint);
SchedulerBackend 则告诉TaskScheduler,TaskScheduler 找到该 Task 对应的 TaskSetManager,并通知到该TaskSetManager,这样 TaskSetManager 就知道 Task 的失败与成功状态;
即SchedulerBackend(DriverEndPoint) => TaskScheduler => TaskSetManager
对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数, 那么就把它放回待调度的Task池子中,否则整个Application失败
在记录 Task 失败次数过程中,会记录它上一次失败所在的Executor Id和Host。下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用;