论文简述
原论文:(http://papers.nips.cc/paper/6233-hierarchical-deep-reinforcement-learning-integrating-temporal-abstraction-and-intrinsic-motivation.pdf)
经典的DQN在面临环境反馈稀疏和反馈延迟的情况下无能为力。例如在 Montezuma’s Revenge 游戏中,无论DQN如何去学习均为0。原因在于这类游戏需要高级的策略。比如图中要拿到钥匙,然后去开门。这对我们而言是通过先验知识得到的。但是很难想象计算机如何仅仅通过图像感知这些内容。感知不到,那么这种游戏也就无从解决。
为此,文中构造了一个两个层级的算法,顶层用于决策,确定下一步的目标,底层用于具体行动。这很符合人类完成一个复杂任务的模式,遇到一个复杂任务的时候,我们会把它拆解成一系列的小目标,然后逐个去实现这些小目标。通过这样的算法,文章能够学习到Montezuma’s Revenge游戏的策略。
公式理解
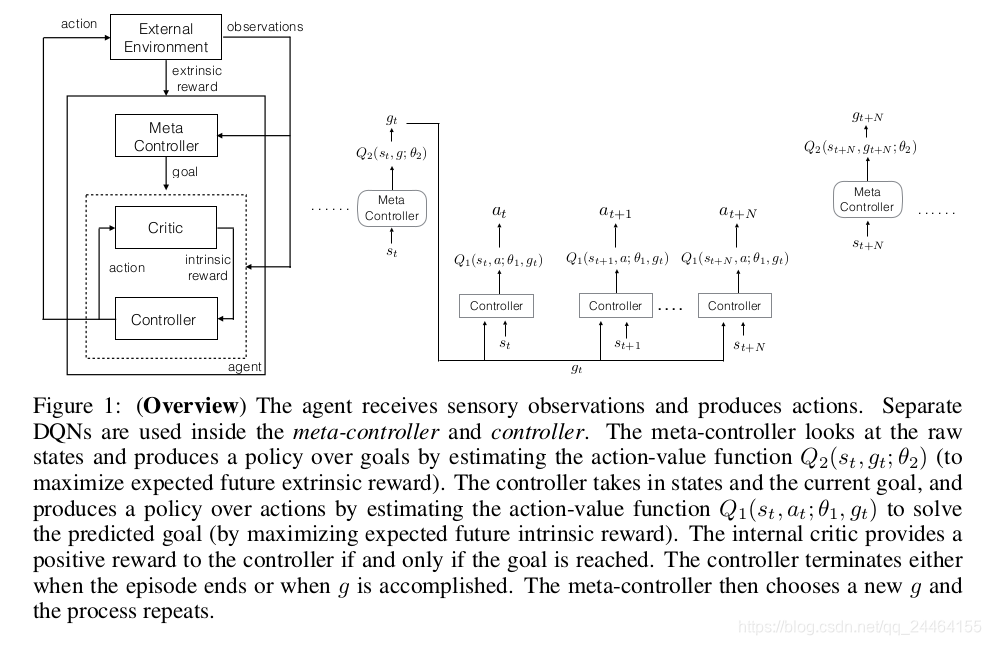
这是一个两层算法:
meta-controller:负责获取当前状态s_t,后从可能的子任务里面选取一个子任务 交代给下一个层级的控制器去完成。它是一个强化学习算法,其目标是最大化实际得到的extrinsic reward之和。在这里,这一层使用的是DQN方法,这一层Q-value的更新目标是: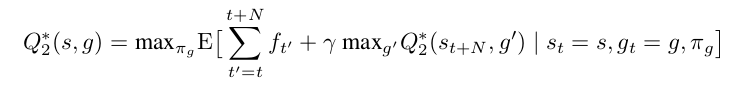
controller:它负责接收上一个层级的子任务 以及当前的状态 ,然后选择一个可能的行动 去执行。它也是一个强化学习算法,其目标是最大化一个人为规定的critic给出的intrinsic reward之和。这里也使用DQN方法,更新目标为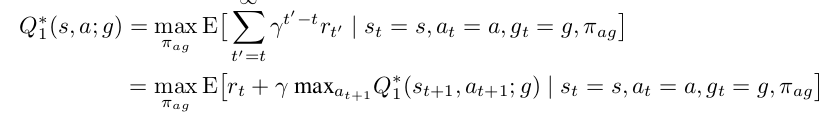
伪代码

实验结果
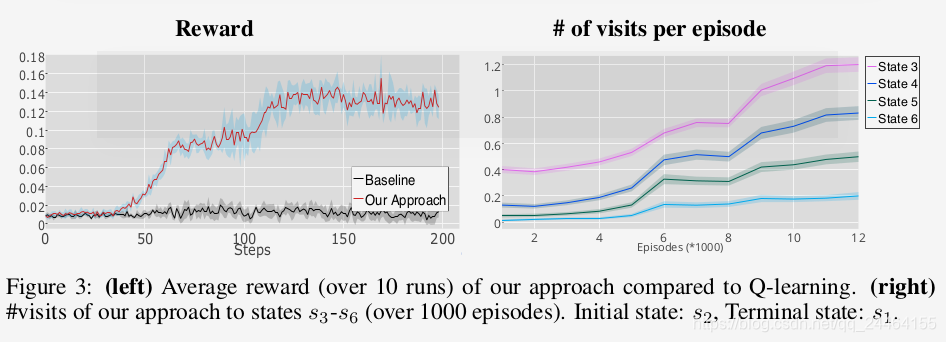
延迟反馈下的实验结果,Q-learning作为baseline ,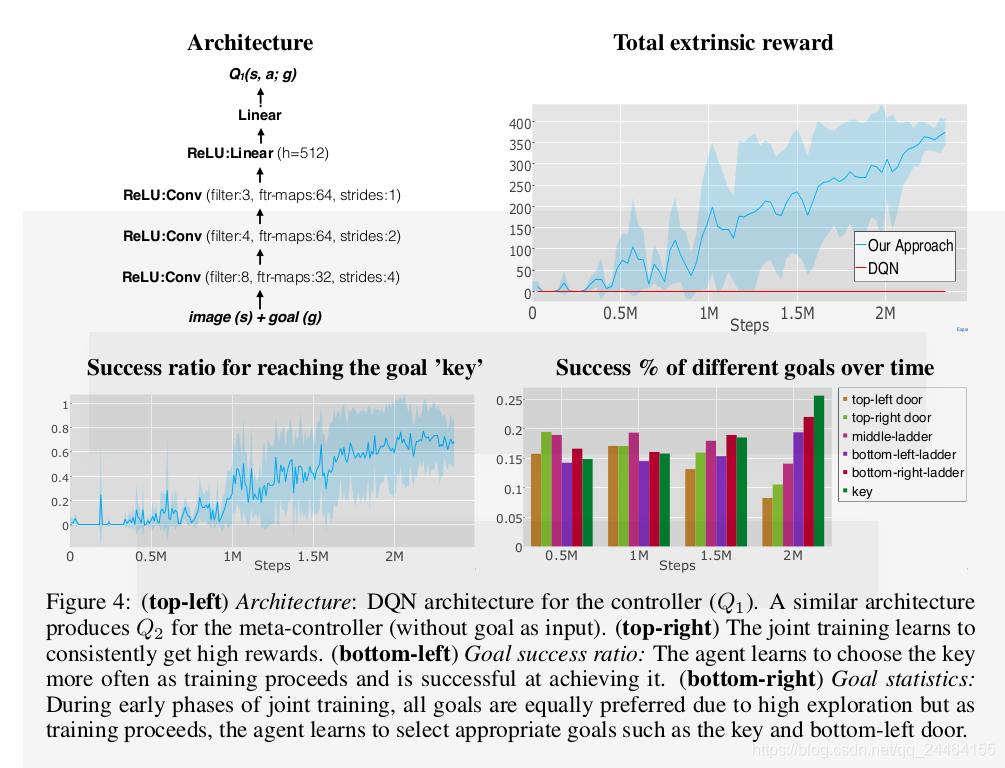
延迟反馈下的实验结果,DQN作为baseline ,