计算机硬件有两种储存数据的方式:
大端字节序(big endian)和小端字节序(little endian)。
举例来说,数值0x2211使用两个字节储存:高位字节是0x22,低位字节是0x11。
- 大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
- 小端字节序:低位字节在前,高位字节在后,即以0x1122形式储存。
同理,0x1234567的大端字节序和小端字节序的写法如下图: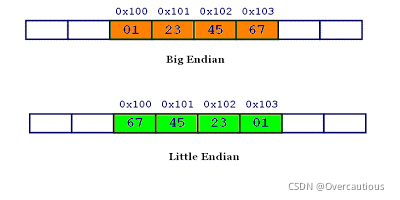
为什么会有这两种存储方式?
- 因为计算机电路从低位开始处理数据,效率会比较高,所以,在早起的计算机内部处理都是小端字节序。现在的PC大多数采用小端字节序。
- 人类比较习惯读写大端字节序,因此,除了计算机内部,其他的场合几乎都是大端字节序,比如网络传输和文件存储。
使用程序判断主机的字节序
#include <stdio.h>
void byteorder()
{
union
{
short value;
char union_bytes[ sizeof( short ) ];
} test;
test.value = 0x0102;
if ( ( test.union_bytes[ 0 ] == 1 ) && ( test.union_bytes[ 1 ] == 2 ) )
{
printf( "big endian\n" );
}
else if ( ( test.union_bytes[ 0 ] == 2 ) && ( test.union_bytes[ 1 ] == 1 ) )
{
printf( "little endian\n" );
}
else
{
printf( "unknown...\n" );
}
}
int main(){
byteorder();
return 0;
}
版权声明:本文为qq_44700810原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。