一、区别总结
1️⃣HashMap 是非线程安全的,不适用于多线程资源共享场景,在单线程场景下性能最好。在多线程环境中,需要手动实现同步机制。HashMap 中,null 可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为 null。当 get() 返回 null 时,既可以表示 HashMap 中没有该 key,也可以表示该 key 所对应的 value 为 null。因此,在 HashMap 中不能用 get() 来判断是否存在某个 key,应该用 containsKey() 来判断。
2️⃣Hashtable 的 API 都是 sychronized 的,因此是线程安全的,可以直接用在多线程环境中。由于 Hashtable 中的所有数据都加了同步锁,因此性能最差。Hashtable 中,无论是 key 还是 value 都不能为 null。
3️⃣HashMap 的迭代器(Iterator)是 fail-fast 迭代器,而 Hashtable 的 enumerator 迭代器不是 fail-fast 的。所以当有其它线程改变了 HashMap 的结构(增加或者移除元素),将会抛出 ConcurrentModificationException,但迭代器本身的 remove() 移除元素则不会抛出 ConcurrentModificationException。但这并不是一定发生的行为,要看 JVM。
4️⃣Hashtable 和 HashMap 都实现了 Map 接口,但是 Hashtable 的实现是基于 Dictionary 抽象类的。Java5 提供了 ConcurrentHashMap,它是 Hashtable 的替代,比 Hashtable 的扩展性更好。ConcurrentHashMap 在 HashMap 的基础上对其所存的数据进行了分段,每个分段都有一个锁,当读的时候不受锁的影响,只有在写的时候受锁的限制,缩小了锁的范围,不同段之间不受锁竞争影响,既保证了线程安全,又提升了性能。ConcurrentHashMap 类是 Java 并发包 java.util.concurrent中提供的一个线程安全且高效的 HashMap 实现。在 JDK7 中采用分段锁的方式;JDK8 中直接采用了 CAS(无锁算法)+ sychronized。
5️⃣Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列映射表的一个桶。
count 变量是一个计数器,它表示每个 Segment 对象管理的 table 数组(若干个 HashEntry 组成的链表)包含的 HashEntry 对象的个数。每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的总数。注意,之所以在每个 Segment 对象中包含一个计数器,而不是在 ConcurrentHashMap 中使用全局的计数器,是为了避免出现“热点域”而影响 ConcurrentHashMap 的并发性。
二、ConcurrentHashMap (线程安全)
- 底层采用分段的数组+链表实现
- 通过把整个 Map 分为N个 Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于 HashEntry 的 value 变量是 volatile 的,也能保证读取到最新的值。)
- Hashtable 的 synchronized 是针对整张 Hash 表的,即每次锁住整张表让线程独占,ConcurrentHashMap 允许多个修改操作并发进行,其关键在于使用了锁分离技术。
- 有些方法需要跨段,比如 size() 和 containsValue(),它们可能需要锁定整个表而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
- 扩容:段内扩容(段内元素超过该段对应 Entry 数组长度的 75% 触发扩容,不会对整个 Map 进行扩容),插入前检测是否需要扩容,避免无效扩容。
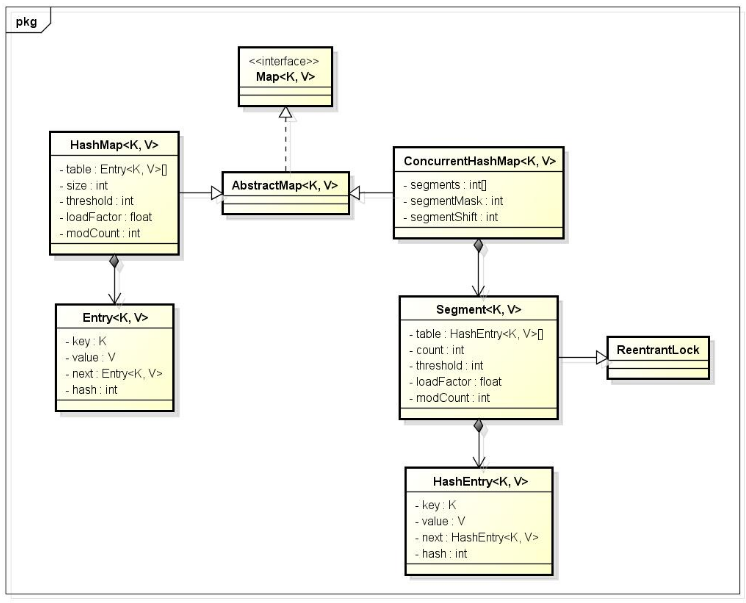
从类图可看出在存储结构中 ConcurrentHashMap 比 HashMap 多出了一个类 Segment,而 Segment 是一个可重入锁。ConcurrentHashMap 是使用了锁分段技术来保证线程安全的。
锁分段技术:
首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据仍能被其他线程访问。
ConcurrentHashMap 提供了与 Hashtable 和 SynchronizedMap 不同的锁机制。Hashtable 中采用的锁机制是一次锁住整个 hash 表,从而在同一时刻只能由一个线程对其进行操作;而 ConcurrentHashMap 中则是一次锁住一个桶。
ConcurrentHashMap 默认将 hash 表分为16个桶,诸如 get、put、remove 等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
三、Hashtable (线程安全)
- 底层采用数组+链表实现。key 和 value 都不能为 null。实现线程安全的方式是在修改数据时锁住整个 Hashtable,效率低。
- 初始 size 为11,扩容:newsize = oldsize*2+1
- 计算 index 的方法:index = (hash & 0x7FFFFFFF) % tab.length
#四、hash表的属性:加载因子/负载极限
1️⃣HashMap 和 Hashtable 都是用 hash 算法来决定其元素的存储,因此HashMap 和 Hashtable 的 hash 表包含如下属性:
①容量(capacity):hash 表中桶(buckets)的数量;图中的标有0、1、2、3 … 11所对应的数组空间就是一个个桶。
②初始化容量(initial capacity):创建 hash 表时桶的数量,HashMap 允许在构造器中指定初始化容量;
③尺寸(size):当前 hash 表中记录的数量;
④加载因子(load factor):加载因子等于“size/capacity”。加载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)。
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的加载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是75,即需要设定75/0.75=100的数组大小。
⑤哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
⑥空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
HashMap 和 Hashtable的构造器允许指定一个负载极限,HashMap 和 Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash 表会发生 rehashing。
2️⃣**“负载极限”值可以根据实际情况来调整,默认值(0.75)是时间和空间成本上的一种折中:**
- 较高的“负载极限”可以降低 hash 表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作。
HashMap 的 get() 与 put() 都要用到查询 - 较低的“负载极限”会提高查询数据的性能,但会增加 hash 表所占用的内存开销。
3️⃣影响 HashMap 性能的两个因素:哈希表中的初始化容量(桶的数量)和加载因子
当哈希表中条目数超过了当前容量与加载因子的乘积时,哈希表将会作出自我调整,将容量扩充为原来的两倍,并且重新将原有的元素重新映射到表中,这一过程成为 rehash。rehash 操作是会造成时间与空间的开销的,因此初始化容量与加载因子会影响 HashMap 的性能。