比赛地址:https://www.kaggle.com/c/leaf-classification/rules
完整代码:https://github.com/SPECTRELWF/kaggle_competition
个人主页:liuweifeng.top:8090
比赛题目:对树叶的类别进行分类,树叶总共99个类别,树叶的图片如下:

我也不知道怎么分类,反正总共有99中类别的树叶。下载到的数据集解压后如下:
image里面存了所有的树叶图像,train.csv是训练文件的标号以及类别,后面有一堆的特征,我没用到,因为比赛已经结束了,我只是纯纯的拿了练习下CNN。test.csv文件是测试数据的标号,sample_submission.csv文件是提交样例,长这样:
第一列是id,后面的99列是对应的每个类别的概率,分类结果加上softmax就行。
思路:
直接使用的基于ImageNet预训练的resnet101,微调一下。
预处理
将训练集的id和label写到一个txt文件中,测试集的id写入另一个txt文件:
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/12/8 上午10:27
import os
import pandas as pd
classes = ['Acer_Capillipes', 'Acer_Circinatum', 'Acer_Mono', 'Acer_Opalus', 'Acer_Palmatum', 'Acer_Pictum', 'Acer_Platanoids', 'Acer_Rubrum', 'Acer_Rufinerve', 'Acer_Saccharinum', 'Alnus_Cordata', 'Alnus_Maximowiczii', 'Alnus_Rubra', 'Alnus_Sieboldiana', 'Alnus_Viridis', 'Arundinaria_Simonii', 'Betula_Austrosinensis', 'Betula_Pendula', 'Callicarpa_Bodinieri', 'Castanea_Sativa', 'Celtis_Koraiensis', 'Cercis_Siliquastrum', 'Cornus_Chinensis', 'Cornus_Controversa', 'Cornus_Macrophylla', 'Cotinus_Coggygria', 'Crataegus_Monogyna', 'Cytisus_Battandieri', 'Eucalyptus_Glaucescens', 'Eucalyptus_Neglecta', 'Eucalyptus_Urnigera', 'Fagus_Sylvatica', 'Ginkgo_Biloba', 'Ilex_Aquifolium', 'Ilex_Cornuta', 'Liquidambar_Styraciflua', 'Liriodendron_Tulipifera', 'Lithocarpus_Cleistocarpus', 'Lithocarpus_Edulis', 'Magnolia_Heptapeta', 'Magnolia_Salicifolia', 'Morus_Nigra', 'Olea_Europaea', 'Phildelphus', 'Populus_Adenopoda', 'Populus_Grandidentata', 'Populus_Nigra', 'Prunus_Avium', 'Prunus_X_Shmittii', 'Pterocarya_Stenoptera', 'Quercus_Afares', 'Quercus_Agrifolia', 'Quercus_Alnifolia', 'Quercus_Brantii', 'Quercus_Canariensis', 'Quercus_Castaneifolia', 'Quercus_Cerris', 'Quercus_Chrysolepis', 'Quercus_Coccifera', 'Quercus_Coccinea', 'Quercus_Crassifolia', 'Quercus_Crassipes', 'Quercus_Dolicholepis', 'Quercus_Ellipsoidalis', 'Quercus_Greggii', 'Quercus_Hartwissiana', 'Quercus_Ilex', 'Quercus_Imbricaria', 'Quercus_Infectoria_sub', 'Quercus_Kewensis', 'Quercus_Nigra', 'Quercus_Palustris', 'Quercus_Phellos', 'Quercus_Phillyraeoides', 'Quercus_Pontica', 'Quercus_Pubescens', 'Quercus_Pyrenaica', 'Quercus_Rhysophylla', 'Quercus_Rubra', 'Quercus_Semecarpifolia', 'Quercus_Shumardii', 'Quercus_Suber', 'Quercus_Texana', 'Quercus_Trojana', 'Quercus_Variabilis', 'Quercus_Vulcanica', 'Quercus_x_Hispanica', 'Quercus_x_Turneri', 'Rhododendron_x_Russellianum', 'Salix_Fragilis', 'Salix_Intergra', 'Sorbus_Aria', 'Tilia_Oliveri', 'Tilia_Platyphyllos', 'Tilia_Tomentosa', 'Ulmus_Bergmanniana', 'Viburnum_Tinus', 'Viburnum_x_Rhytidophylloides', 'Zelkova_Serrata']
train_txt = open('train.txt','w')
train_csv = pd.read_csv(r'leaf-classification/train.csv')
ids = train_csv['id']
species = train_csv['species']
for i in range(len(ids)):
train_txt.write(str(ids[i]))
train_txt.write(' ')
train_txt.write(str(classes.index(str(species[i]))))
train_txt.write('\n')
train_txt.close()
test_txt = open('test.txt','w')
test_csv = pd.read_csv(r'leaf-classification/test.csv')
ids = test_csv['id']
for i in range(len(ids)):
test_txt.write(str(ids[i]))
test_txt.write('\n')
test_txt.close()
模型resnet101
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/12/8 上午10:24
import torch
import torchvision.models
import torchvision.transforms as transforms
import torch.nn as nn
import torchvision.models as models
class resnet101(nn.Module):
def __init__(self, num_classes=1000):
super(resnet101, self).__init__()
self.num_classes = num_classes
self.feature_extract = torchvision.models.resnet101(pretrained=True)
self.net = nn.Sequential(
nn.Linear(1000, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(256, num_classes),
)
def forward(self, x):
x = self.feature_extract(x)
x = self.net(x)
return x
# x = torch.randn((1,3,224,224))
# net = resnet101(num_classes=99)
# print(net)
# print(net(x).shape)
dataloader
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/12/8 上午10:24
import numpy as np
import torch.utils.data as data
import torch
import torchvision.transforms as transforms
from PIL import Image
data_root = r'leaf-classification/images/'
class leaf_Dataset(data.Dataset):
def __init__(self,is_train=True,transform=None):
self.is_train = is_train
self.transform = transform
self.images = []
self.labels = []
if is_train:
file = open('train.txt','r')
lines = file.readlines()
for line in lines:
res = line[:-1]
image = res.split(' ')[0]
label = int(res.split(' ')[1])
self.images.append(image)
self.labels.append(label)
print(self.images)
print(self.labels)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
image_name = self.images[index] + '.jpg'
image_path = data_root + image_name
img = Image.open(image_path).convert('RGB')
# print(img)
img = self.transform(img)
label = self.labels[index]
label = torch.from_numpy(np.array(label))
return img, label
transforms = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor()
])
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/12/8 上午10:25
"""
使用imagenet预训练的rennet101来在树叶数据集上面进行微调
"""
import torch
import torchvision.transforms as transforms
from dataset import leaf_Dataset
import torch.utils.data as data
import torch.optim as optim
import torch.nn as nn
from resnet import resnet101
#使用Adam优化器来训练网络,不冻结参数
# 设置hyperparameter
epoch = 200
lr = 1e-3
b1 = 0.9
b2 = 0.999
device = torch.device('cuda:0')
train_loss = []
# 初始化网络模型
net = resnet101(num_classes=99)
net.to(device)
# load data
transforms = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
])
data = leaf_Dataset(is_train=True,transform=transforms)
dataloader = torch.utils.data.DataLoader(data,
batch_size=64,
shuffle=True)
loss_func = nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(),lr=lr,betas=(b1,b2))
for epoch in range(1,epoch + 1):
for i, (x,y) in enumerate(dataloader):
x = x.to(device)
y = y.to(device)
pred = net(x)
loss = loss_func(pred,y)
opt.zero_grad()
loss.backward()
opt.step()
train_loss.append(loss.item())
print("epoch: %d batch_idx:%d loss:%.3f" %(epoch,i,loss.item()))
torch.save(net.state_dict(),'model/epoch:%d'%epoch + '.pth')
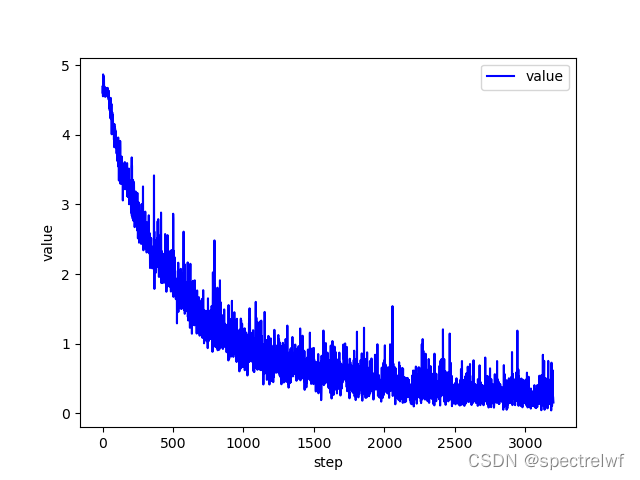
from utils import plot_curve
plot_curve(train_loss)
loss
将预测结果写入要提交的文件
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/12/8 下午5:42
import torch
import torchvision.transforms as transforms
import numpy as np
import os
from PIL import Image
from resnet import resnet101
import torch.nn.functional as F
image_path = r'leaf-classification/images'
f = open('test.txt','r')
tmp = f.readlines()
test_file = []
for i in tmp:
i = i[:-1]
test_file.append(i+'.jpg')
print(test_file)
device = torch.device('cuda:0')
net = resnet101(num_classes=99)
print('load weight........')
net.load_state_dict(torch.load('model/epoch:200.pth'))
net.to(device)
net.eval()
transformss = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor()
])
res = []
with torch.no_grad():
for image in test_file:
img = Image.open(os.path.join(image_path,image)).convert('RGB')
img = transformss(img)
img = torch.unsqueeze(img,dim=0)
img = img.to(device)
# print(img.shape)
pred = net(img)
pred = F.softmax(pred).flatten()
pred = pred.cpu().numpy()
print(pred)
res.append(pred)
np.savetxt("result.csv",res,delimiter = ',')
版权声明:本文为lwf1881原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。