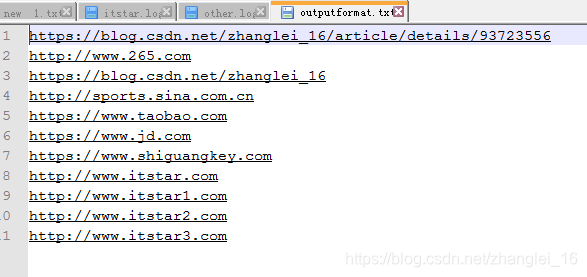
需求:有如下文件,需要将itstar输出到一个文件,其他的输出到另一个文件,并自定义输出文件路径与文件名
1:定义FilterMap类
package OutputFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FilterMap extends Mapper<LongWritable, Text, Text, NullWritable> {
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
k.set(line);
//写出
context.write(k, NullWritable.get());
}
}
2:定义FilterReducer类
package OutputFormat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FilterReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
String line = key.toString();
line = line + "\r\n";
context.write(new Text(line), NullWritable.get());
}
}
3:定义了FilterlogRecordWriter类
package OutputFormat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class FilterlogRecordWriter extends RecordWriter<Text, NullWritable> {
FSDataOutputStream itstarOut = null;
FSDataOutputStream otherOut = null;
/**
* 数据的输出环节
* @param job 用于获取配置信息,从而得到从而得到fs
*/
public FilterlogRecordWriter(TaskAttemptContext job) {
//数据的输出
try {
FileSystem fs = FileSystem.get(job.getConfiguration());
Path itstarPath = new Path("E:\\bigdata_code\\outputformat\\out\\itstar.log");
Path otherPath = new Path("E:\\bigdata_code\\outputformat\\out\\other.log");
itstarOut = fs.create(itstarPath);
otherOut = fs.create(otherPath);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
if(text.toString().contains("itstar")){
itstarOut.write(text.toString().getBytes());
}else {
otherOut.write(text.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
if(itstarOut != null){
itstarOut.close();
}
if(otherOut != null){
otherOut.close();
}
}
}
4:定义了FilterlogOutputFormat类
package OutputFormat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FilterlogOutputFormat extends FileOutputFormat<Text, NullWritable> {
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
return new FilterlogRecordWriter(job);
}
}
5:定义了FilterDriver类
package OutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FilterDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[] {"E:\\bigdata_code\\outputformat\\outputformat.txt",
"E:\\bigdata_code\\outputformat\\out"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FilterDriver.class);
job.setMapperClass(FilterMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(FilterReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//要将自定义的输出格式组件设置到job
job.setOutputFormatClass(FilterlogOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 虽然自定义了outputformat,但是因为OutputFormat继承自fileoutputformat,
// 而fileoutputformat要输出一个SUCCESS文件,所以这里还要指定一个输出目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
输出结果: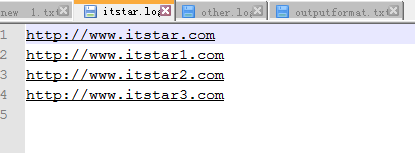
版权声明:本文为zhanglei_16原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。