HashSet底层机制及源码分析
1、底层机制
(1)HashSer底层是HashMap,HashMap底层是数组+链表+红黑树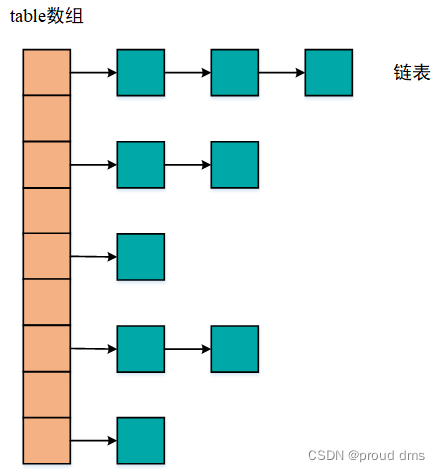
(2)添加一个元素时,先得到hash值(会转成索引值),找到存储数据表table,判断这个索引位置是否已经存放元素,如果没有存放,则直接加入;如果有,则调用equals比较,如果相同,就放弃添加,如果不相同,则添加到链表最后。
(3)在JDk 8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小≥MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。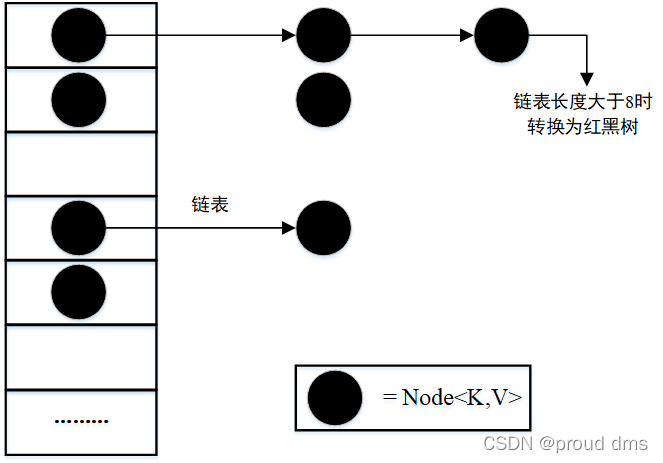
2、构造HashSet,给hashSet添加元素
import java.util.HashSet;
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("Java");
hashSet.add("DMS");
hashSet.add("TOM");
System.out.println("hashSet="+hashSet);
}
}
3、设置断点,debug添加机理
4、源码分析
(1) 执行HashSet()
public HashSet() {
map = new HashMap<>();
}
(2)执行add()
public boolean add(E e) {//e = “java”
return map.put(e, PRESENT)==null;//(static) PRESENT = new Object();
}
(3)执行put() , 该方法会执行hash(key) 得到key 对应的hash 值算法h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//key = “java” value = PRESENT 共享
return putVal(hash(key), key, value, false, true);
}
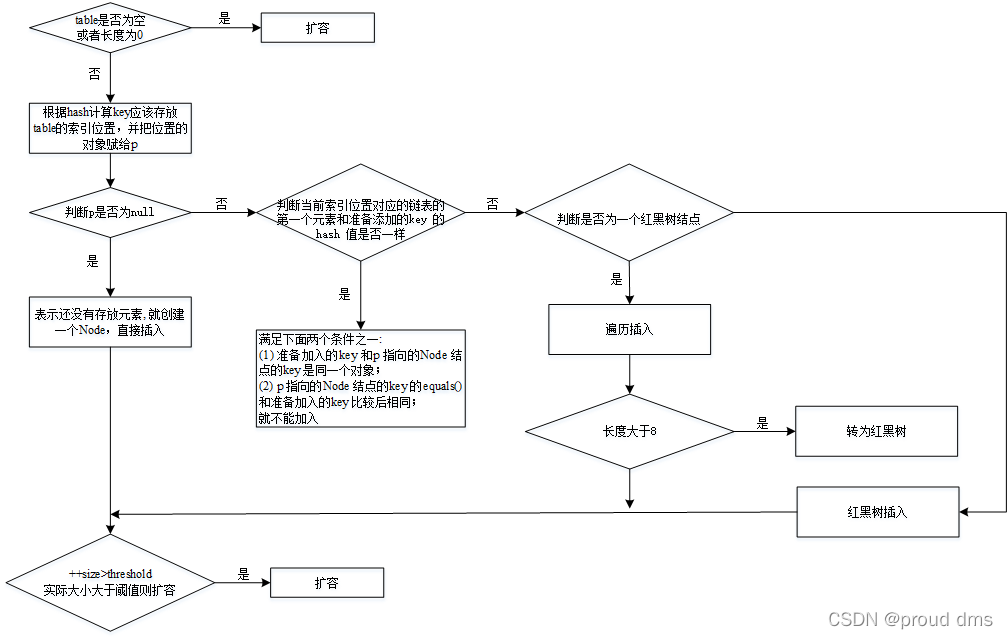
(4)执行putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //定义了辅助变量
//table 就是HashMap 的一个数组,类型是Node[]
//if 语句表示如果当前table 是null, 或者大小=0
//就是第一次扩容,到16 个空间.
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//(1)根据key,得到hash 去计算该key 应该存放到table 表的哪个索引位置
//并把这个位置的对象,赋给p
//(2)判断p 是否为null
//(2.1) 如果p 为null, 表示还没有存放元素, 就创建一个Node (key=“java”,value=PRESENT)
//(2.2) 就放在该位置tab[i] = newNode(hash, key, value, null)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//一个开发技巧提示: 在需要局部变量(辅助变量)时候,在创建
Node<K,V> e; K k; //
//如果当前索引位置对应的链表的第一个元素和准备添加的key 的hash 值一样
//并且满足下面两个条件之一:
//(1) 准备加入的key 和p 指向的Node 结点的key 是同一个对象
//(2) p 指向的Node 结点的key 的equals() 和准备加入的key 比较后相同
//就不能加入
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//再判断p 是不是一颗红黑树,
//如果是一颗红黑树,就调用putTreeVal , 来进行添加
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//如果table 对应索引位置,已经是一个链表, 就使用for 循环比较
//(1) 依次和该链表的每一个元素比较后,都不相同, 则加入到该链表的最后
// 注意在把元素添加到链表后,立即判断该链表是否已经达到8 个结点
// , 就调用treeifyBin() 对当前这个链表进行树化(转成红黑树)
// 注意,在转成红黑树时,要进行判断, 判断条件
// if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY(64))
// resize();
// 如果上面条件成立,先table 扩容.
// 只有上面条件不成立时,才进行转成红黑树
//(2) 依次和该链表的每一个元素比较过程中,如果有相同情况,就直接break
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD(8) - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//size 就是我们每加入一个结点Node(k,v,h,next), size++
if (++size > threshold)
resize();//扩容
afterNodeInsertion(evict);
return null;
}
*/
}
}
6、代码运行结果
