C++ 实现神经网络
介绍
深度学习和神经网络最近几年如火如荼,各种NN层出不穷, 这年头程序员要没听说过CNN, RNN, 还真不好意思跟人打招呼。各种库也非常多,什么pyTorch, mxnet, theano, tensorflow, keras,cntk,各种听过的没听过的满天飞。都快是全民AI学习机器学习的节奏了,怪不得Nvidia的股票一直在涨。
虽然用C++ 实现神经网络会比较麻烦,不过如果注意到以下下的trick, 在用C++ 实现神经网络时会舒服很多,代码也会非常简明,核心代码在百行左右也不是问题。
- C++ 没有内置的向量,矩阵库,可以自己先轮几个Vector, Matrix类以及各种数学运算操作,最好搞成链式操作。
- 不要用index form来推导和实现BP算法,个人比较喜欢matrix form, 公式会非常紧凑,实现起来也不太容易出错
- 顶层框架设计,比如先设计几个基类Model类,数据库类,定义几个通用的接口。实现具体的算法时,只要实现特定接口即可。
我最近实现了一把基本的神经网络,包括LR和多层NN模型, 使用C++11, Visual Studio 2017开发,源码放在了https://github.com/speedmancs/ML上。
训练程序的基本框架
在基类Model中,训练的框架逻辑在Fit方法中,主要流程就是SGD或者batch训练, 对于不同的模型,需要实现其中的ClearGradient, Eval, ComputeGradient, Update等方法
1. Eval 也就是神经网络的forward过程,前向计算得到当前的参数下的预测结果 数学上就是 计算E=f(θ)
2. ComputeGradient 是BP 计算参数导数的过程, ∂E∂θ
3. 再得到导数之后, 再Update更新参数。 θ=θ−η∂E∂θ
void Model::Fit(const DataSet& trainingSet, const DataSet& validateSet)
{
for (int i = 0; i < m_config.train_epoch; i++)
{
for (size_t j = 0; j < trainingSet.Size(); j++)
{
if (j % m_config.batchSize == 0) ClearGradient();
size_t pred = Eval(trainingSet.GetData(j));
ComputeGradient(trainingSet.GetData(j), trainingSet.GetTarget(j));
if (j % m_config.batchSize == m_config.batchSize - 1 || j == trainingSet.Size() - 1) Update();
}
}
}
在batch模式下训练时,ComputeGradient需要把batch个样例的所有导数加起来,最后平均一下后进行update。在一个新的batch开始之前,需要调用ClearGradient对存储这些参数导数的变量清零。以logistic regression为例, 其中W,b分别是权重参数和偏置项, dW, db分别是其导数。
void LRModel::ClearGradient()
{
db = 0;
dW = 0;
}
void LRModel::Update()
{
db.Div((float)m_config.batchSize);
dW.Div((float)m_config.batchSize);
b.Sub(m_config.learning_rate, db);
W.Sub(m_config.learning_rate, dW);
}Logistic Regression Model
有个上面的基本训练算法框架,实现具体的算法就很简单了,比如LR的模型是这样的, y是OneHot的target, x是输入向量
Forward
Compute gradients
照着公式实现Eval, ComputeGradient就行了。
void LRModel::ComputeGradient(const Vector<float>& x, const OneHotVector& y)
{
(y_diff = y_hat).Sub(y);
db.Add(y_diff);
dW.AddMul(y_diff, x);
}
size_t LRModel::Eval(const Vector<float>& x)
{
y_hat.AssignMul(W, x).Add(b).SoftMax();
return y_hat.Max().second;
}Vanilla Neural Network
NN也类似,和LR不同的是,NN在输出层之前加了若干隐藏层。 公式会变得复杂一些,但是实现还是很直接
Forward
x(0)是输入, x(L)是最终的输出 y^, σL是softMax函数, σl,∀l∈[1,L−1]是sigmod函数
back propagation
void VanillaNNModel::ComputeGradient(const Vector<float>& x, const OneHotVector& y)
{
int L = m_config.LayerNumber;
(gradient_layers[L - 1] = activate_layers[L - 1]).Sub(y);
for (int i = L - 2; i >= 0; i--)
{
gradient_layers[i].AssignMulTMat(weights[i + 1], gradient_layers[i + 1]);
gradient_layers[i].Mul(activate_layers[i]).MulScalarVecSub(1.0f, activate_layers[i]);
}
for (int i = 0; i < L; i++)
{
d_biases[i].Add(gradient_layers[i]);
d_weights[i].AddMul(gradient_layers[i], i > 0 ? activate_layers[i - 1] : x);
}
}
size_t VanillaNNModel::Eval(const Vector<float>& data)
{
int L = m_config.LayerNumber;
for (int i = 0; i < L; i++)
{
layers[i].AssignMul(weights[i], i == 0 ? data : activate_layers[i - 1]).Add(biases[i]);
activate_layers[i] = layers[i];
if (i != L - 1) activate_layers[i].Sigmod();
else activate_layers[i].SoftMax();
}
y_hat = activate_layers[L - 1];
return y_hat.Max().second;
}基本程序库
这些主要是向量,OneHotVector和矩阵运算,以及一些常用的utility,基本上用到了什么数学操作就顺手加了进去
template<class T>
class Vector
{
public:
// ......
Vector<T>& AddMul(const Matrix<T>& m, const Vector<T>& v);
Vector<T>& MulScalarVecSub(T value, const Vector<T>& other);
Vector<T>& SoftMax();
};template<class T>
class Matrix
{
public:
// ......
Matrix<T>& AddMul(const Vector<T>& a, const Vector<T>& b);
Matrix<T>& Add(T scale, const Matrix<T>& other);
};实战数字识别
mnist数字识别堪称深度学习的hello world, 这个数据库包括60000个训练样本,10000个测试样本,大小是28*28的手写数字。
数据准备
mnist网站上给出的原始文件是二进制的,对照其网站的格式,我们实现了MnistDataSet类,它的基类DataSet如下:
class DataSet
{
public:
DataSet() = default;
DataSet(int categoryNumber);
virtual bool Load(const std::string& dataFile,
const std::string& labelFile) = 0;
// ......
};主要需要override Load方法,下面是load方法中parse label的代码示例
bool MnistDataSet::LoadLabels(const std::string& labelFile)
{
std::ifstream fin(labelFile.c_str(), std::ifstream::binary);
if (!fin)
return false;
int magicNumber;
int number;
fin.read((char *)&magicNumber, 4);
magicNumber = Utility::EndiannessSwap(magicNumber);
fin.read((char *)&number, 4);
number = Utility::EndiannessSwap(number);
unsigned char t;
for (int i = 0; i < number; i++)
{
fin.read((char *)&t, 1);
m_targets.push_back(OneHotVector((size_t)t, m_categoryNumber));
}
return true;
}mnist数字识别训练程序
string configPath = argv[1];
auto pConfig = Configuration::CreateConfiguration(configPath);
// 加载mnist 数据库
MnistDataSet trainSet(pConfig->category_number);
trainSet.Load(pConfig->trainingDataPath, pConfig->trainingLabelPath);
MnistDataSet testSet(pConfig->category_number);
testSet.Load(pConfig->validateDataPath, pConfig->validateLabelPath);
// 创建Model训练
auto pModel = pConfig->CreateModel();
pModel->Fit(trainSet, testSet);
pModel->Save();logistic regression配置文件
<?xml version="1.0" encoding="utf-8"?>
<Configuration>
<DataSetting>
<CategoryNumber>10</CategoryNumber>
<FeatureNumber>784</FeatureNumber>
<TrainingData path="C:\train-images.idx3-ubyte" labelFile="C:\train-labels.idx1-ubyte"/>
<ValidateData path="C:\t10k-images.idx3-ubyte" labelFile="C:\t10k-labels.idx1-ubyte"/>
</DataSetting>
<ModelSetting type="LR" savePath="C:\lrmodel.txt">
<TrainEpoch>200</TrainEpoch>
<LearningRate>0.1</LearningRate>
<BatchSize>128</BatchSize>
</ModelSetting>
</Configuration>运行命令
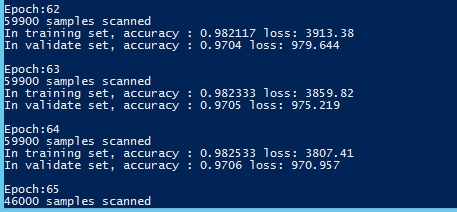
.\MinstDigitalRec.exe C:\workspace\github\ml\sample\LR.config.xmlLR训练的结果
最终在测试集上达到92%左右
2个隐藏层的NN配置文件
<?xml version="1.0" encoding="utf-8"?>
<Configuration>
<DataSetting>
<CategoryNumber>10</CategoryNumber>
<FeatureNumber>784</FeatureNumber>
<TrainingData path="C:\train-images.idx3-ubyte" labelFile="C:\train-labels.idx1-ubyte"/>
<ValidateData path="C:\t10k-images.idx3-ubyte" labelFile="C:\t10k-labels.idx1-ubyte"/>
</DataSetting>
<ModelSetting type="VanillaNN" savePath="C:\vnnmodel.txt">
<TrainEpoch>200</TrainEpoch>
<LearningRate>0.1</LearningRate>
<BatchSize>128</BatchSize>
<hiddenLayer size="50"/>
<hiddenLayer size="50"/>
</ModelSetting>
</Configuration>运行命令
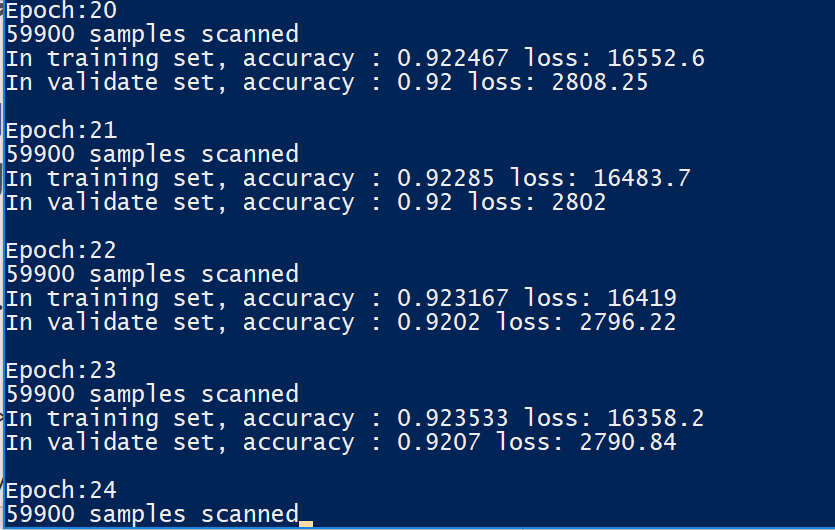
.\MinstDigitalRec.exe C:\workspace\github\ml\sample\VanillaNN.config.xmlNN训练60多轮结果
最终在测试集上达到97%