编译过程:
预处理, 展开头文件/宏替换/去掉注释/条件编译 (test.i main .i)
编译, 检查语法,生成汇编 ( test.s main .s)
汇编, 汇编代码转换机器码 (test.o main.o)
链接 链接到一起生成可执行程序 a.out

编译:编译阶段是检查语法,生成汇编
汇编:汇编代码转换机器码 这个阶段,非底层的程序员不需要考虑, 编译器不会搞错的。也与c/c++开发者无关,但是我们可以利用反汇编来调试代码,学习汇编语言依然是必备的。
链接
———————————————————————————————————
预处理:主要是做一些代码文本的替换工作。(该替换是一个递归逐层展开的过程。)
(1)将所有的#define删除,并展开所有的宏定义
(2)处理所有的条件预编译指令,如:#if #ifdef #elif #else #endif
(3)处理#include预编译指令,将被包含的文件插进到该指令的位置,这个过程是递归的
(4)删除所有的注释//与/* */
(5)添加行号与文件名标识,以便产生调试用的行号信息以及编译错误或警告时能够显示行号
(6)保留所有的#pragma编译器指令,因为编译器需要使用它们

以下为转载内容:编译原理学习(一)–编译以及编译过程
①编译器首先也是一种电脑程序。它会将用某种编程语言写成的源代码(原始语言),转换成另一种编程语言(目标语言)。
②高级计算机语言便于人编写,阅读,维护。低阶机器语言是计算机能直接解读、运行的。编译器主要的目的是将便于人编写,阅读,维护的高级计算机语言所写作的源代码,翻译为计算机能解读、运行的低阶机器语言的程序。
1.词法分析
编译器的第一个步骤称为词法分析或扫描。词法分析器读入组成源程序的字符流,并将其组成有意义的词素的序列。形如<token-name, attribute-value>这样的词法单元。(token-name是由语法分析使用的抽象符号,attribute-value是指向符号表中关于这个词法单元的条目,符号表条目的信息会被语义分析和代码生成步骤使用)
例如源程序包含如下赋值语句:position = initial + rate * 60
2.语法分析
编译的第2个步骤称为语法分析或解析。语法分析器使用由词法分析器生成的各词法单元的第一个分量来创建树形的中间表示。该中间表示给出了词法分析产生的词法单元的语法结构。常用的表示方法是语法树,树中每个内部节点表示一个运算,而该节点的子节点表示运算的分量。
以上赋值语句表示成语法树: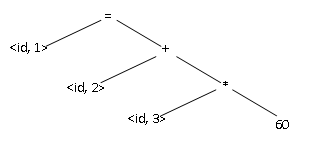
3.语义分析
(数据的含义就是语义。简单的说,数据就是符号。数据本身没有任何意义,只有被赋予含义的数据才能够被使用,这时候数据就转化为了信息,而数据的含义就是语义)
语义分析器使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致 。它同时收集类型信息,并存放在语法树或符号表中,以便在中间代码生成过程使用。
语义分析的一个重要部分就是类型检查。比如很多语言要求数组下标必须为整数,如果使用浮点数作为下标,编译器就必须报错。再比如,很多语言允许某些类型转换,称为自动类型转换。
图1-1中显示了一个这样的自动类型转换,假设position,initial和rate已经被声明为浮点型,而词素60是一个整数。语义分析器输出中有一个inttofloat的额外节点,明确的把60转换为一个浮点数。
4.中间代码生成
在源程序翻译成目标代码的过程中,一个编译器可能构造出一个或多个中间表示。这些中间表示可以有多种形式。语法树是一种中间表示形式,它们通常在语法分析和语义分析中使用。
在源程序的语法分析和语义分析完成之后(也会生成中间表示,区别语法树),很多编译器生成一个明确的低级的或类机器语言的中间表示。该中间表示有两个重要的性质:1.易于生成;2.能够轻松地翻译为目标机器上的语言。
5.代码优化
代码优化试图改进中间代码,以便生成更好的目标代码。即更快(省时),更短(省空间)或能耗更低。
6.代码生成
代码生成以中间表示形式作为输入,并把它映射为目标语言。如果目标语言是机器代码,则必须为每个变量选择寄存器或内存位置,中间指令则被翻译为能够完成相同任务的机器指令序列。
代码生成的一个至关重要的方面是合理分配寄存器以存放变量的值。