使用pyspark操作数据库
1.sqlite篇
# -*- coding: utf-8 -*-
# @Author: xiaodong
# @Date : 2020/4/4
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("sqlite").getOrCreate()
# 注意,这里的sqlite的db路径需要写绝对路径。
url = "jdbc:sqlite:D:/work/workspace/python_executor_db/data/dbs/movies.db?rewriteBatchedStatements=true"
properties = {"driver": "org.sqlite.JDBC"}
links_frame = spark.read.jdbc(url,
"(select * from links)a",
properties=properties)
movies_frame = spark.read.jdbc(url,
"(select * from movies)b",
properties=properties)
# 如果你擅长用sql,你可以这么做
links_frame.registerTempTable("links")
movies_frame.registerTempTable("movies")
r = spark.sql("""
select
a.*, b.*
from
links a,
movies b
where a.movieId = b.movieId
""")
r.show()
# 以下两种方式,由于当存在相同列名时不好取列,因此需要特殊处理下
r = links_frame.join(movies_frame, links_frame.movieId == movies_frame.movieId)
r = links_frame.join(movies_frame, on="movieId").select(links_frame.moviesId.alias("a_movieId"),
movies_frame.moviesId.alias("b_movieId"),
"imdbId",
"tmdbId",
"title",
"genres"
)
# 对genres列做统计, 统计各genre元素出现个数
target = (
r.select("genres")
.rdd
.map(lambda obj: obj.genres.split("|"))
.flatMap(lambda obj: obj)
.map(lambda obj: (obj, 1))
.reduceByKey(lambda x, y: x+y)
)
print(target.collectAsMap())
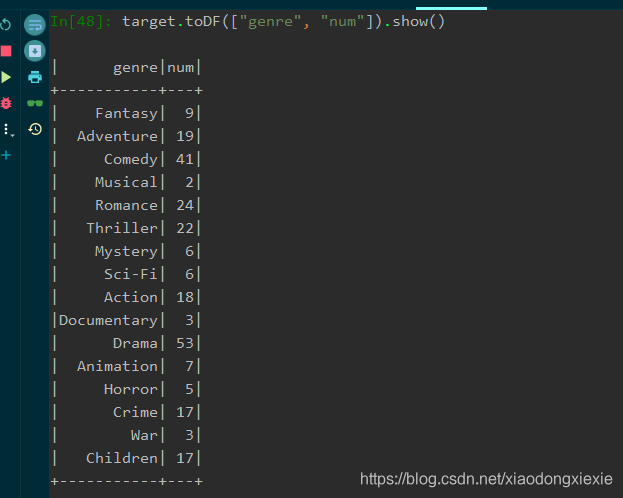
r = target.toDF(["genre", "num"])
r.cache().show()
# 将数据写入到别的数据库(如:oracle,mysql,greenplum)
# 不过,这么写入sqlite时有点问题,如果谁有spark写入sqlite的途径,可以交流下~
# (
# r.write.format("jdbc") # .format("greenplum")
# .options(**your-options-dict) # {"url": "your-jdbc-url", "dbtable": "your-table", "driver": "your-driver"}
# .mode("overwrite")
# .save()
# )

2.mysql篇
spark = SparkSession.builder.appName("mysql").getOrCreate()
# 建议使用rewriteBatchedStatements = True 模式,支持批量插入
# 建议使用serverTimezone=Asia/Shanghai,不然你如果用到sql中的datetime等类型时间可能会对不上
url = "jdbc:mysql://localhost:3306/movies?rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai"
# jar包 mysql-connector-java-8.0.13.jar
# 如果使用jar包为5.xx版本,则driver 为 com.mysql.jdbc.Driver
properties = {"driver": "com.mysql.cj.jdbc.Driver",
"user": "root",
}
links_frame = spark.read.jdbc(url,
"links", # 注意和下面的两种写法
properties=properties)
movies_frame = spark.read.jdbc(url,
"(select * from movies)b",
properties=properties)
r = links_frame.join(movies_frame, links_frame.movieId == movies_frame.movieId)
# 两个表有列同名时后期处理比较繁琐,
# 可以通过 .withColumnRenamed 将同名列重命名,方便后期使用~
r = links_frame.join(movies_frame, on="movieId").select("imdbId",
"tmdbId",
"title",
"genres")
r.show()
# 对genres列做统计, 统计各genre元素出现个数
target = (
r.select("genres")
.rdd
.map(lambda obj: obj[0].split("|"))
.flatMap(lambda obj: obj)
.map(lambda obj: (obj, 1))
.reduceByKey(lambda x, y: x + y)
)
r = target.toDF(["genre", "num"])
options = properties.copy()
options.update({
"dbtable": "genres",
"url": url,
# "password": "your-password",
})
(
r.write
.format("jdbc")
.options(**options)
.mode("overwrite") # 建议预先设计好表结构,然后用 "append" 模式
.save()
)
spark.stop()
版权声明:本文为xiaodongxiexie原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。