
号外号外!!
根据最新出炉的PYPL6月报告,“通过半年的发展,Python基本已奠定2019-2010年的地位,持续称王就对了!”(CSDN)
看过上期推文的朋友一定会想起来Python最具杀伤力的武器——简洁有效!
贤者曾言:Life is simple, I use Python!
本期精彩看点——字符串字符串类型(str)是编程中最常用的数据类型。字符串就是一系列字符,在Python中经常见用引号括起来的字符串。(包括单引号、双引号/三引号)
'朴实'"无华"'''数据科学'''"""一起学!"""另外,三引号可以换行。(单双引号直接换行会报错)
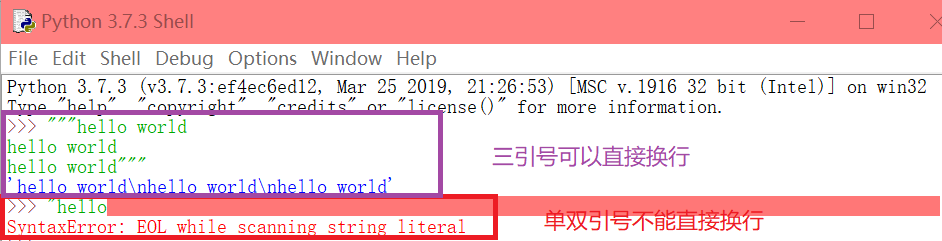
那么问题来了,如果字符串内容中包含引号,怎么正确输入呢?
法一:用其他类型的引号,避免出现歧义;
"Let's go!"'俗话说"英雄所见略同"'法二:利用转义字符\ 。
'Let\'s go!"
通过转义字符\加上想表达的引号,程序也可以准确输出。但这个写法容易出错,小编还是更推荐法一。
说到转义字符,我们先来补充一下常用的四个转义字符。
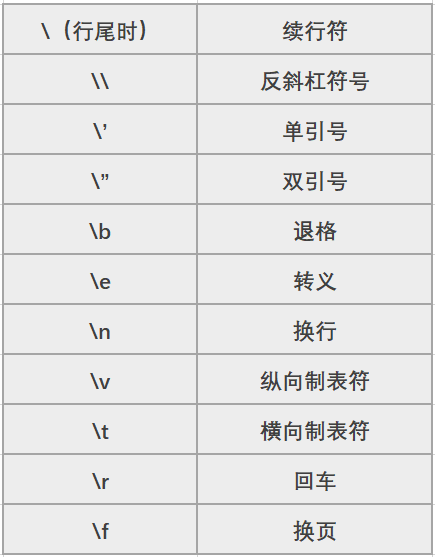
(本文稍后会涉及部分转移符号的运用)

字符串方法和函数篇
1大小写转换
方法lower( )、方法upper( )
>>>S='Life is simple, I use Python'>>>S.lower()'life is simple, i use python'>>>S.upper()'LIFE IS SIMPLE, I USE PYTHON'返回S字符串的小写、大写格式。(注意,这是新生成的字符串,在另一片内存片段中)
>>> print('ab ABC'.lower())ab abc>>> print('ab CD'.upper())AB CD方法title( ),将每个单词的首字母大写
>>> print('sherlock holmes'.title())Sherlock Holmes2
字串搜索
方法cout( )
S.count(sub[,start[, end]])返回字符串S中子串sub出现的次数,可以指定从哪里开始计算(start)以及计算到哪里结束(end),索引从0开始计算,不包括end边界。
>>> print('brubrubr'.count('br'))3>>> print('brubrubr'.count('br',1))2 #index=1,即从‘r’开始查找,查找范围为‘rubrumm’>>> print('brubrubr'.count('br',1,7))1 #查找范围为‘rubrub’>>> print('brubrubr'.count('br',1,8))2 #查找范围为‘rubrubr’方法endwith( )、方法startwith( )
S.endswith(suffix[, start[, end]]) S.startswith(prefix[, start[, end]])endswith() 检查字符串S是否以suffix结尾,返回布尔值的True和False。suffix可以是一个元组(tuple)。可以指定起始start和结尾end的搜索边界。
同理 startswith() 用来判断字符串S是否是以prefix开头。
>>> print('abcdef'.endswith('def'))True #搜索范围为‘abcdef’>>> print('abcdef'.endswith('def',4))False #搜索范围为‘ef’>>> print('abcdef'.endswith('def',0,5))False #搜索范围为‘abcde’>>> print('abcdef'.endswith('def',0,6))True #搜索范围为‘abcdef’方法find( )、方法rfind( ) & 方法index( )、方法rindex( )
S.find(sub[, start[, end]]) S.rfind(sub[, start[, end]])S.index(sub[, start[, end]]) S.rindex(sub[, start[, end]])方法find( )搜索字符串S中是否包含子串sub,如果包含,则返回sub的索引位置,否则返回"-1"。可以指定起始start和结束end的搜索位置。
方法index( )和方法find( )一样,唯一不同点在于当找不到子串时,抛出 ValueError 错误。
方法rfind( )则是返回搜索到的最右边子串的位置,如果只搜索到一个或没有搜索到子串,则和方法find( )是等价的。
方法rindex( )同理可知。
3
拼接字符串
+
Python中利用”+“来合并字符串的方法叫做拼接。
>>> print('abc'+'def')abcdef还记得Python中一个最经典的例子——”hello world“,我们对此做个小拓展,可以输出一个” hello xxxx“的输出。
>>> name='sherlock holmes'>>> print("Hello," + name.title() + "!")Hello,Sherlock Holmes!4
分割
方法split( )、方法rsplit( )、方法splitlines( )
S.split(sep=None, maxsplit=-1) S.rsplit(sep=None, maxsplit=-1) S.splitlines([keepends=True])这三个函数用来分割字符串,并生成一个列表。下面我们根据例子来理解一下三个函数的用法。
先来看方法split( )的用法:
>>> 'a,b,c'.split(',')['a', 'b', 'c']>>> 'a,b,c'.split(',',1)['a', 'b,c'] #限定分割次数1>>> 'a b c'.split(maxsplit=1)['a', 'b c'] #maxsplit限定分割次数>>> 'a,b,c'.split()['a,b,c'] >>> 'a b c'.split()['a', 'b', 'c'] #不指定sep时方法split() 根据sep对S进行分割,maxsplit用于指定分割次数,如果不指定sep或者指定为None,则改变分割算法:以空格为分隔符。
方法rsplit( )和方法split()是一样的,只不过是从右边向左边搜索。
下面来看看方法splitlines( ),它是用来专门用来分割换行符。
>>> ''.split('\n')['']>>> ''.splitlines()[]>>> 'OH MY GOD\n'.split('\n')['OH MY GOD', '']>>> 'OH MY GOD\n'.splitlines()['OH MY GOD']5
添加空白
\n 换行符
>>> print("Films:\nX-Men\nWonder\nMarvel's The Avengers")Films:X-MenWonderMarvel's The Avengers\n\t 换行符和制表符
>>> print("Films:\n\tX-Men\n\tWonder\n\tMarvel's The Avengers")Films: X-Men Wonder Marvel's The Avengers6
修剪
方法strip( )、方法lstrip( )、方法rstrip( )
S.strip([chars]) #移除左右两边的字符chars,默认移除空白(空格、制表符、换行符)。S.lstrip([chars]) #移除左边S.rstrip([chars]) #移除右边>>> ' sherlock holmes '.lstrip()'sherlock holmes '>>> ' sherlock holmes '.rstrip()' sherlock holmes'>>> ' sherlock holmes '.strip()'sherlock holmes'>>> 'sherlock holmes'.lstrip('s')'herlock holmes'>>> 'sherlock holmes'.rstrip('s')'sherlock holme'>>> 'sherlock holmes'.strip('s')'herlock holme'>>> print('www.example.com'.lstrip('cmowz.')) example.com >>> print('wwwz.example.com'.lstrip('cmowz.')) example.com >>> print('wwaw.example.com'.lstrip('cmowz.')) aw.example.com >>> print('www.example.com'.strip('cmowz.')) example由于 www.example.com 的前4个字符都是字符序列 cmowz. 中的字符,所以都被移除,而第五个字符e不在字符序列中,所以修剪到此结束。同理 wwwz.example.com ;wwaw.example.com 中第3个字符a不是字符序列中的字符,所以修剪到此结束。
字符串的转化
type( )函数查看数据类型
>>> type(int('114525'))#字符串转化为整数<class 'int'>>>> type(float('3.0'))#字符串转化为浮点数<class 'float'>>>> type(eval("[1,2,[3,4,[5,6],7],8]"))#字符串转化为列表<class 'list'>>>> type(eval("{'a':'hi','b':'there'}"))#字符串转化为字典<class 'dict'>字符串格式化
本文将介绍两种字符串格式化的方法,format( )函数和f-strings。
从 Python 2.6开始,新增了一种格式化字符串的函数str.format(),基本语法是通过{}和:来代替以前的%。format函数支持通过位置、关键字、对象属性和下标等多种方式使用,不仅参数可以不按顺序,也可以不用参数或者一个参数使用多次。并且可以通过对要转换为字符串的对象的__format __方法进行扩展。
'{1} {0}'.format('abc', 123) # 可以不按顺序进行位置映射,输出'123 abc''{} {}'.format('abc', 123) # 可以不指定参数名称,输出'abc 123''{1} {0} {1}'.format('abc', 123) # 参数可以使用多次,输出'123 abc 123''{name} {age}'.format(name='tom', age=27) # 可以按关键字映射,输出'tom 27''{person.name} {person.age}'.format(person=person) # 可以按对象属性映射,输出'tom 27''{0[1]} {0[0]}'.format(lst) # 通过下标映射另外,在复杂格式控制方面,format函数也提供了更加强大的控制方式:
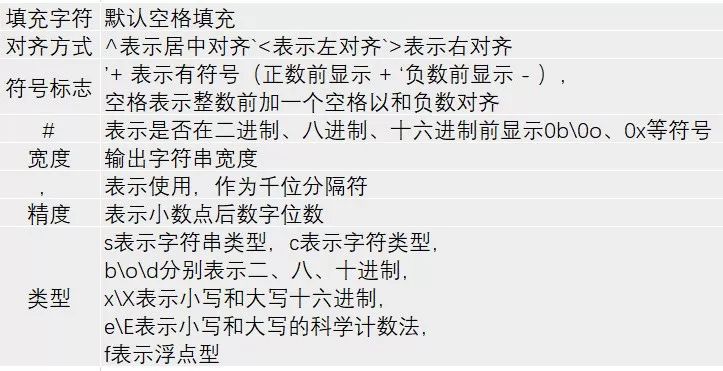
'{:S^+#016,.2f}'.format(1234) # 输出'SSS+1,234.00SSSS'具体控制参数的含义可参见下表:

Life is simple, I use Python.
即日起,关注我们,
无论起步何处,都是Python学习者。
