论文地址:Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
概述:
本篇论文是由来自苏黎世联邦理工学院和上海交通大学的Guolei Sun等人提出,被ECCV 2020(oral)接收。其旨在通过挖掘跨图像的语义信息来促进弱监督语义分割(WSSS)任务。具体来说,他们提出了一个 co-attention (共同注意力) 机制和 contrastive co-attention (对比共同注意力) 机制来帮助分类器更好的学习物体的模式 (pattern)。该方法能被应用在不同的弱监督语义分割settings下,比如 (1) 标准的图像级别监督; (2) 附加的单标签数据; (3) 附加的带噪声的网络数据。实验表明,此方法在不同的settings下都取得了SOTA的性能,并且在 CVPR2020 Learning from Imperfect Data Challenge 挑战赛中获得了第一名。
接下来将通过动机,贡献,方法和结果四个parts介绍本篇论文。
预计阅读时长:25分钟
注:本篇需要提前对Attention有所了解。
一.Motivation
当前的WSSS模型通常仅使用单图像信息识别物体模式,而忽略了弱注释数据中的丰富语义上下文。例如,利用图像级标签,不仅可以识别每个单独图像的语义,而且它还给出了跨图像语义关系,即两个图像是否共享某些语义。这种跨图像的语义信息其实可以作为物体模式挖掘的有用线索。
二.Contribution
(1) 通过co-attention分类器在成对训练样本上的工作,该论文解决了跨图像语义相关性对于完整的物体模式学习以及物体位置推断的价值。
(2) co-attention分类器以更全面的方式挖掘语义线索。 除了单图像语义外,它还通过共同注意力机制和对比共同注意力机制从跨图像语义相似性和差异挖掘互补监督。
(3) 该方法通用性很强,可以通过精确的图像级监督,超简单的单标签甚至是嘈杂的Web爬下来的数据来学习WSSS。 它优雅地解决了不同WSSS设置的固有挑战,并始终如一地展现出令人满意的结果。
三.Co-attention Classification Network
对于主流的WSSS方法,给定一组带有图像级标签的训练图像,首先训练一个分类网络以发现相应的区分对象区域 (比如说对于一张label为狗的图片,找到图像中对狗的分类贡献大的区域,有点类似目标检测)。 在训练样本上得到的物体定位图(object localization maps)会被作为伪真值masks来进一步监督语义分割网络的学习。
本论文的idea:
与以往大多数单独处理每个训练图像的工作不同,作者将跨图像语义关系作为类级别的上下文来探索,以更全面地理解物体模式。 为此,设计了两个共同注意力机制。 第一个驱动分类器从共同关注的对象区域中学习通用语义,而另一个驱动分类器将注意力集中在其余对象上,以实现非共享的语义分类 (主要的工作在于分类器上)。基于以上,提出了Co-attention Classification Network。
下图展示了主流方法和本论文的方法的不同。
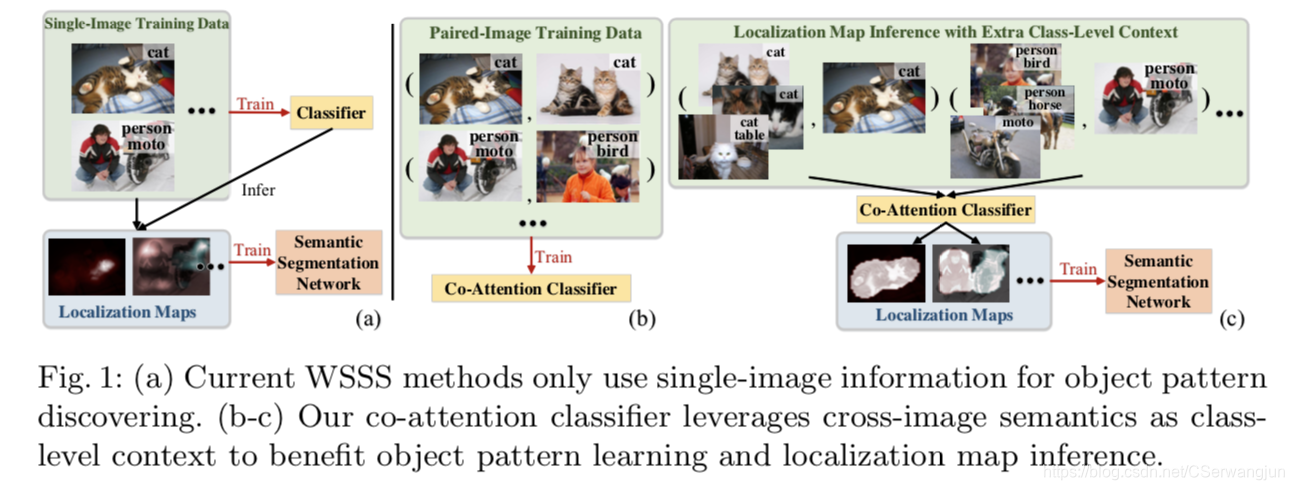 注:图来自原论文
注:图来自原论文下面重点介绍Co-attention 和 contrastive co-attention,以及作者如何用他们来促进特征的表达能力和分类器的。
Co-Attention:
训练集中的图片被表征成 < I n , l n > <I_{n}, l_{n}><In,ln>, I n I_{n}In是训练集中的第n nn个图片。l n l_{n}ln是它相应的label,为一个K维的向量,K是训练集总共的类别数。
首先,如图二(下方)所示,我们从数据集中采样两张图片< I m , I n > <I_{m}, I_{n}><Im,In>,然后输入到一个卷积神经网络中获取这两张图片的feature maps < F m , F n > <F_{m}, F_{n}><Fm,Fn>, (它们的大小为C×H×W, C为通道数,H*W为图像分辨率)。然后,基于 F m F_{m}Fm,和F n F_{n}Fn, 我们通过下式算一个亲和矩阵(affinity matrix) P PP,
P = F m T W P F n ∈ R H W × H W P =F_{m}^TW_PF_n ∈R^{HW×HW}P=FmTWPFn∈RHW×HW
F m , F n ∈ R C × H W F_m, F_n∈R^{C×HW}Fm,Fn∈RC×HW, 这里两个特征图都被平铺成矩阵的格式, W P ∈ R C × C W_P∈R^{C×C}WP∈RC×C是一个学习的变量矩阵。亲和度矩阵P PP存储与F m , F n F_m, F_nFm,Fn中的任意两个位置相对应的相似性分数,即,P ( i , j ) P(i,j)P(i,j)给出F m F_mFm中的第i ii个位置和F n F_nFn中的第j jj个位置之间的相似性。
之后,通过softmax对P PP列正则化,我们可以得到F n F_nFn中每个位置对于F m F_mFm的注意图 A m A_mAm (attention maps,可以理解为权重,具体查阅attention相关知识)。
A m = s o f t m a x ( P ) ∈ [ 0 , 1 ] H W × H W A_m =softmax(P)∈[0,1]^{HW×HW}Am=softmax(P)∈[0,1]HW×HW
同样的,我们可以得到图n nn中每个位置对图m mm的attention maps A n A_nAn.
这里需要重点理解P PP中行列,以及每个元素的意义,不然对应的关系会弄错。
然后,我们可以把这两个feature maps送到一个类感知全卷积层去获得类感知激活图 (class-aware activation maps) < S m , S n > <S_{m}, S_{n}><Sm,Sn> (大小K×H×W)。
现在有了attention maps (简单可以理解为权重),之后我们要做的事情就是和其他的attention机制一样,将特征和attention maps相乘来获得一个被加权后的feature maps。我们可以根据F n ( F m ) F_n(F_m)Fn(Fm)的每个位置来计算F m ( F n ) F_m(F_n)Fm(Fn)的注意力总和:
F m m ∩ n = F n A n ∈ R C × H × W , F n m ∩ n = F m A m ∈ R C × H × W , F_m^{m∩n} =F_nA_n∈R^{C×H×W},F_n^{m∩n} =F_mA_m∈R^{C×H×W},Fmm∩n=FnAn∈RC×H×W,Fnm∩n=FmAm∈RC×H×W,
注意:这里的size是被reshape过的。
共同注意特征F m m ∩ n F_m^{m∩n}Fmm∩n保留了F m F_mFm和F n F_nFn中的共同语义信息,并且定位了F m F_mFm中的共同物体 (可看图二的示例)。这种基于共同注意的通用语义分类可以使分类器更完整,更准确地理解物体模式。
之后,我们将共同注意特征送进一个类感知全卷积层去获得类感知激活图 (class-aware activation maps) S m m ∩ n = φ ( F m m ∩ n ) ∈ R K × H × W S_m^{m∩n}=φ(F_m^{ m∩n})∈R^{K×H×W}Smm∩n=φ(Fmm∩n)∈RK×H×W 和 S n m ∩ n = φ ( F n m ∩ n ) ∈ R K × H × W S_n^{m∩n}=φ(F_n^{ m∩n})∈R^{K×H×W}Snm∩n=φ(Fnm∩n)∈RK×H×W.
之后将全局平均池化应用在这上面来获得最后的分类得分s m m ∩ n s_m^{m∩n}smm∩n和s n m ∩ n s_n^{m∩n}snm∩n。预测的label应该是两张图片的共同label。
通过共同注意机制,不仅图像中的区别模块,比如人的头,其他比如脚这些不那么区别的部分也会被检测出来。这对后续的分割任务十分重要。
这部分的的损失函数如下:
L c o − a t t m n ( ( I m , l m ) , ( I n , l n ) ) = L C E ( s m m ∩ n , l m ∩ l n ) + L C E ( s n m ∩ n , l m ∩ l n ) L_{co-att}^{mn}((I_m,l_m),(I_n,l_n))=L_{CE}(s_m^{m∩n}, l_m∩l_n)+L_{CE}(s_n^{m∩n}, l_m∩l_n)Lco−attmn((Im,lm),(In,ln))=LCE(smm∩n,lm∩ln)+LCE(snm∩n,lm∩ln)
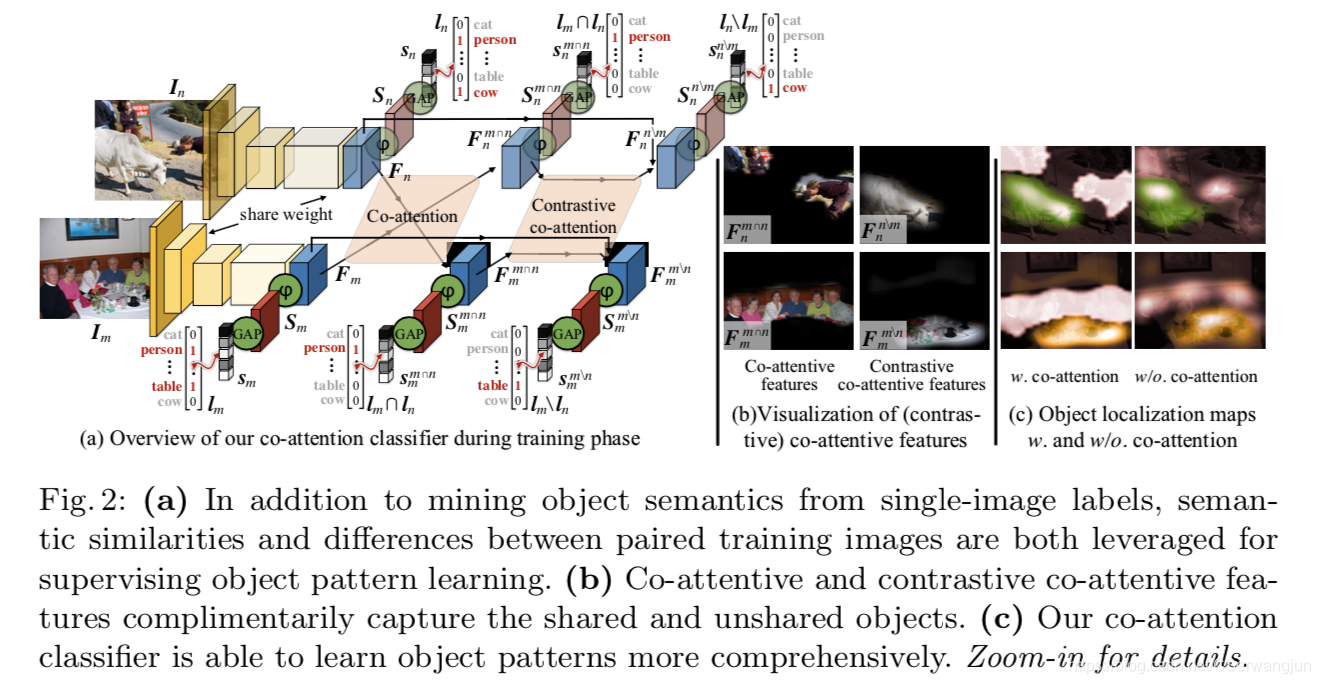 注:图来自原论文
注:图来自原论文Contrastive Co-Attention:
co-attention利用了两张图片中的相同语义部分来促进物体识。但是,那不同的部分该如何训练?
作者提出对比共同注意机制来解决这个问题。
过程和共同注意力机制很相似,首先还是要获得共同注意特征图F m m ∩ n F_m^{ m∩n}Fmm∩n和F n m ∩ n F_n^{ m∩n}Fnm∩n,然后基于这个共同注意特征图,我们来获得类无关的共同注意特征图:
B m m ∩ n = σ ( W B F m m ∩ n ) ∈ [ 0 , 1 ] H × W , B n m ∩ n = σ ( W B F n m ∩ n ) ∈ [ 0 , 1 ] H × W B_m^{m∩n}=σ(W_BF_m^{m∩n})∈[0,1]^{H×W}, B_n^{m∩n}=σ(W_BF_n^{m∩n})∈[0,1]^{H×W}Bmm∩n=σ(WBFmm∩n)∈[0,1]H×W,Bnm∩n=σ(WBFnm∩n)∈[0,1]H×W
这个类无关的共同注意图中突出图片中的所有共同区域。σ σσ是sigmoid函数。我们通过1-B来获得contrastive co-attention. 这个做法很直观,比如对于图中的共同区域,在类无关共同注意图中它的权重是比较高的,但是我们对比共同注意关注的是不同的部分,因此我们通过1减去该值,可以使得原本很关注的部分(共同的部分)变得不关注,不关注的部分(不同的部分)变得关注。
具体的计算:
A m m ∖ n = 1 − B m m ∩ n ∈ [ 0 , 1 ] H × W , A n m ∖ n = 1 − B n m ∩ n ∈ [ 0 , 1 ] H × W , A_m^{m\setminus n} = 1−B_m^{m∩n} ∈ [0, 1]^{H×W,} A_n^{m\setminus n} = 1−B_n^{m∩n} ∈ [0, 1]^{H×W,}Amm∖n=1−Bmm∩n∈[0,1]H×W,Anm∖n=1−Bnm∩n∈[0,1]H×W,
有了类无关注意图,通过将特征图和对比注意图点乘,我们得到生成对比注意特征图 contrastive co-attention features.
F m m ∖ n = F m ⊗ A m m ∖ n ∈ R C × H × W , F n m ∖ n = F n ⊗ A n m ∖ n ∈ R C × H × W F_m^{m\setminus n} =F_m⊗A_m^{m\setminus n} ∈R^{C×H×W}, F_n^{m\setminus n} =F_n⊗A_n^{m\setminus n} ∈R^{C×H×W}Fmm∖n=Fm⊗Amm∖n∈RC×H×W,Fnm∖n=Fn⊗Anm∖n∈RC×H×W
与研究共同语义作为促进物体模式挖掘的信息线索的共同注意相比,对比共同注意从配对图像之间的语义差异解决了互补知识。图2(b)给出了一个直观的例子。对比共同注意能帮助图像更好的区分不同的语义对象。因为两张图片的共同部分和非共同部分被解耦,这可以使得分类器能更好的关注图片的不同部分。比如说,两张图片中都有人,某张图片有只牛,对比共同注意在拿掉人的时候,同时可能也拿掉了分类器错误识别的牛的某部分(被认为是人),剩余的牛的部分足够分类器的去分类,分类器不会被误识别的部分干扰。
训练的损失函数和共同注意部分的很相似:
L c o n − c o − a t t m n ( ( I m , l m ) , ( I n , l n ) ) = L C E ( s m m ∖ n , l m ∖ l n ) + L C E ( s n m ∖ n , l m ∖ l n ) L_{con-co-att}^{mn}((I_m,l_m),(I_n,l_n))=L_{CE}(s_m^{m\setminus n}, l_m\setminus l_n)+L_{CE}(s_n^{m\setminus n}, l_m\setminus l_n)Lcon−co−attmn((Im,lm),(In,ln))=LCE(smm∖n,lm∖ln)+LCE(snm∖n,lm∖ln)
结合共同注意和对比共同注意,整个分类器的训练损失函数如下:
L = ∑ m , n L b a s i c m n + L c o − a t t m n + L c o n − c o − a t t m n L=\sum_{m,n} L_{basic}^{mn}+L_{co-att}^{mn}+L_{con-co-att}^{mn}L=m,n∑Lbasicmn+Lco−attmn+Lcon−co−attmn
其中L b a s i c L_{basic}Lbasic是最基本的WSSS中的损失函数:
L b a s i c = L C E ( s m , l m ) + L C E ( s n , l n ) L_{basic}=L_{CE}(s_m,l_m)+L_{CE}(s_n,l_n)Lbasic=LCE(sm,lm)+LCE(sn,ln)
分类器训练好了之后,对于弱监督语义分割任务,后面很重要的一步就是生成物体位置图 Object Location Maps, 作者提出了一个利用co-attention,来整合相关图片中的上下文信息,提高localization maps的质量。简单来说就是对于图片的某个label,选取几个相同label的图片,生成他们的类感知激活图,最后的localization maps就是它们的平均。
图片测试/推断的时候,还是利用单张图片来做的。
原文还介绍了在其他settings下如何运用他们的方法。比较简单,本文不做介绍,感兴趣的朋友请自行查阅原文。
四.结果
作者做了详实的实验来证明他们的效果,Backbone网络为VGG16和ResNet101,并且还做了消融实验来验证co-attention和contrastive co-attention的作用。在VOC2012上的实验最后达到了66.9mIoU (ResNet101)。