java 并发问题存在的原因 & 解决方案
基于jdk1.8 参考<深入理解JVM> <java并发实践> <Linux内核设计与实现>等
并发存在的原因
计算机的运算速度与它的存储和通信子系统的速度差距太大.速度差距可以看下面的图感受一下

图片摘自 公众号 码农翻身
下面再从数据维度感受一下速度的差距
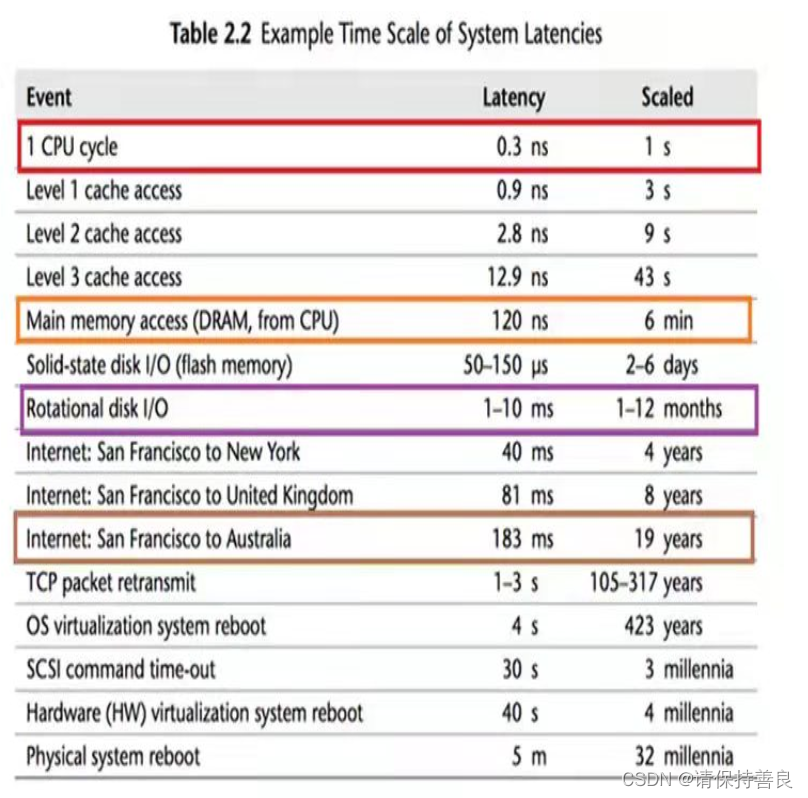
1,000 皮秒 = 1纳秒 ns
1,000,000 皮秒 = 1微秒 μs
1,000,000,000 皮秒 = 1毫秒 ms
1,000,000,000,000 皮秒 = 1秒 s
上图可以看到 CPU最快;
Cpu一个时钟周期是0.3纳秒;
内存访问需要120纳秒;
固态硬盘访问需要 50-150微妙(50,000-150,000 纳秒);
传统硬盘访问需要 1-10 毫秒(1,000,000-10,000,000 纳秒);
网络最慢,都是几十毫秒(几十 *1,000,000 纳秒);
简单类比
cpu 一个时钟周期如果是1s;
内存访问是 6分钟;
固态硬盘是2-6天;
传统硬盘是1-12个月;
网络访问就是几年了;
为了压榨计算机的能力,避免资源的浪费.采取一些手段来提升计算机的性能.目前被证明非常有效的手段之一是让计算机同时处理多项任务.
如多任务操作系统.在单处理器机器上,这会产生多个进程同时运行的错觉.在多核处理器上,
这会使多个进程在不同的处理机上真正同时并行地运行.
无论是单处理器还是多处理器上,多任务操作系统都能使多个进程处于堵塞或者睡眠状态,直到工作就绪.
也就是说现在linux操作系统也许有100个进程在内存,但是只有一个处于可运行状态.
(PS:线程也是一种进程,线程一般隶属于某一个进程.操作系统最小的调度单位是线程.)
常用的进程调度方式有 基于时间片抢占式调度. 即在一个时间段内,每个进程只会在分配到的有限的时间片内允许执行.
此外,一个服务端同时对多个客户端提供服务是另一个更具体的并发应用场景.
每秒事务处理数(TPS)是 这种场景下衡量一个服务性能高低好坏的最重要的指标之一. 而TPS数值与程序的并发能力有着密切的关系.
此处引出了并发。
缓存的存在的原因 以及 引入的新问题
计算机中大多数的运算任务不仅仅只靠处理器计算完成,大多数情况下还需要和内存交互. 所以无法仅仅依靠寄存器来完成所有的运算任务.
并且由于计算机的存储设备与处理器的运算速度有几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近的缓存
来作为内存与处理器之间的缓冲.
此处引出了cpu Cache。 当然还有内存层面的 Page Cache。 下图感受一下
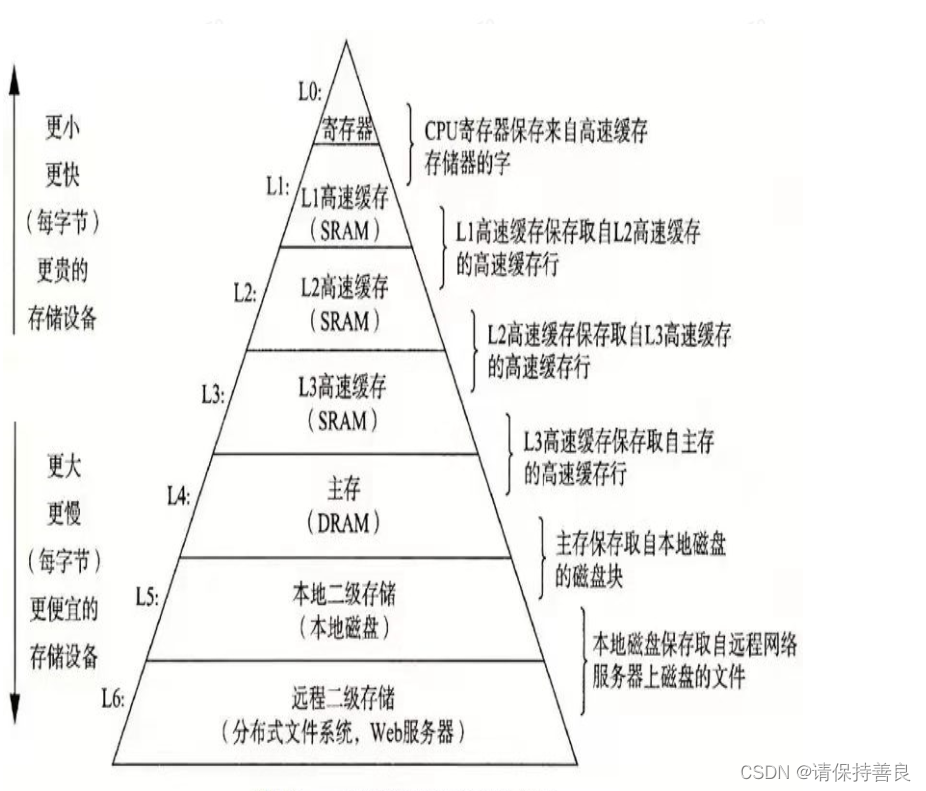
CPU cache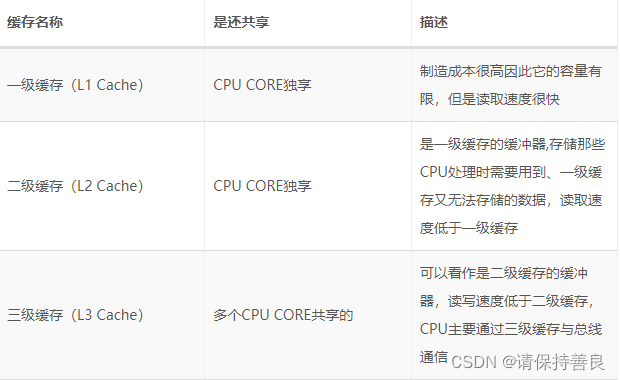
引入的新的问题 : 缓存一致性
每个处理器都有自己的高速缓存,而它们又共享同一个主内存.
当多个处理器的运算任务涉及同一块主内存区域时,将可能导致各自的缓存数据不一致.
MESI 是众多缓存一致性协议中的一种,也在Intel系列中广泛使用的缓存一致性协议
缓存行(Cache line)的状态有Modified、Exclusive、 Share 、Invalid,而MESI 命名正是以这4中状态的首字母来命名的
乱序执行存在的原因 以及 引入的新问题
除了增加高速缓存之外,为了使得处理器内部的运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行优化.然后将乱序执行的结构重组,
保证该结果与顺序执行的结果是一致的.
比如某些io操作耗时是cpu运算耗时的上万倍,这种时候不可能让cpu资源闲置下来等待io.而是选择不影响最终结果的 乱序执行.
此外 java 虚拟机的即时编译器中也有类似的指令重排序优化.
指令重排序
1.编译器优化的重排
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2.指令并行的重排
现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序
3.内存系统的重排
由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
java的解决方案 - java 内存模型
自jdk1.5后内存模型成熟. java 内存模型的主要目标是定义程序中各个变量的访问规则:
即 在虚拟机中将变量存储到内存 和 从内存中取出变量这样的底层细节.
主要包括8种交互操作 分别为 lock unlock read load use assign store write(都是原子性) 详细可以参看 <深入理解java虚拟机> 以及 对 volatile 的特殊规则.
Java中的8大原子操作
1、lock:主内存,标识变量为线程独占
2、unlock:主内存,解锁线程独占变量
3、read:主内存,读取内存到线程缓存(工作内存)
4、load:工作内存,read后的值放入线程本地变量副本
5、use:工作内存,传值给执行引擎
6、assign:工作内存,执行引擎结果赋值给线程本地变量
7、store:工作内存,存值到主内存给write备用
8、write:主内存,写变量值
volatile 修饰的对象的特殊规则
1. volatile 修饰的变量对所有线程可见.即 对volatile 变量的修改 其他线程立即可见.(禁用cpu多级缓存,直接从内存读取)
2. volatile 修饰的变量 禁止指令重排序.("指令重排序无法越过内存屏障")
经典面试题 : DCL(Double Check Lock)到底需不需要加volatile?
单例如下
public class Singleton {
private Integer value = 32;
private static volatile Singleton INSTANCE;
private Singleton() {
}
public static Singleton getInstance() {
// 外层第一次校验. (如果对象不为空,直接返回.这里为了提升性能,没有加锁.)
if (INSTANCE == null) {
// 如果对象为空(这种情况较少) 则进入竞争抢锁逻辑
synchronized (Singleton.class) {
//第二次校验. (获取到锁之后,再次判断对象是否为空的作用是 在上一步中如果有多个线程处于竞争锁的队列中,当第一个任务结束之后,其他的线程依然会进入到这里执行下述逻辑;
//使用 volatile 的作用是利用 volatile 的特殊性让cpu禁用缓存,直接读取内存. 这样其他的线程就可以读取到初始化好的对象;
//使用 volatile 的还有一层作用是利用volatile 禁止指令重排序的规则. 保证返回的对象是完整的对象 而不是实例化一半的对象. 详见下述t1()方法 字节码描述)
if (INSTANCE == null) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
public static void t1() {
Singleton singleton = new Singleton();
}
}
// access flags 0x9
public static t1()V
L0
LINENUMBER 29 L0
NEW Singleton
DUP
INVOKESPECIAL Singleton.<init> ()V
ASTORE 0
L1
LINENUMBER 32 L1
RETURN
L2
LOCALVARIABLE singleton LSingleton; L1 L2 0
MAXSTACK = 2
MAXLOCALS = 1
上述字节码主要语句是
1. NEW Singleton : 在内存中申请一块空间
2. INVOKESPECIAL Singleton.<init> ()V : 调用特殊的方法.这里是初始化方法
3. ASTORE 0 : 建立关联. 将 singleton 指向创建号内存的空间
这里对象的初始化可能存在指令重排序的指令是 2和3.
如果执行顺序是 1,3,2(这种情况对于同一个线程来说 运行的最终结果是一致的. 没有违反 JVM 规定的8种happens-before不可以发生指令重排序规则. 所以可以发生重排序)
然后这种情况下 如果没有禁止重排序, 当第一个线程执行完1,3指令之后,另一个线程进来的时候,
在 "外层第一次校验"的时候判断对象是否为空? 由于singleton已经指向了一个内存地址 所以不为空,直接返回了初始化一半的对象.
volatile 底层实现
hotspot实现
bytecodeinterpreter.cpp
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) {
if (support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence();
}
}
......
orderaccess_linux_x86.inline.hpp
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
LOCK 用于在多处理器中执行指令时对共享内存的独占使用。
它的作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效。另外还提供了有序的指令无法越过这个内存屏障的作用。
Lock 指令在不同架构的机器上实现方式有所不同.
JVM中的两种锁
(注: 锁比 volatile 控制力度更强. 禁止重排序&多线程可见性)
互斥同步锁 1. synchronized
重量级锁(经过操作系统的调度)synchronized 早期都是这种锁(目前的实现中升级到最后也是这种锁)
每个Java对象都有一个对应的ObjectMonitor对象,它实现了同步机制,这就是为什么Object对象都能当成锁的原因。
同步方法->调用指令读取运行时常量池中方法的 ACC_SYNCHRONIZED 标志
当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志,如果设置了,执行线程将先持有 monitor,
然后再执行方法,最后在方法(正常/非正常)完成时释放 monitor。
显式同步->有明确的 monitorenter 和 monitorexit 指令
虚拟机执行到 monitorenter 指令的时候,会请求获取对象的 monitor 锁,基于 monitor 锁又衍生出一个锁计数器的概念。
当执行 monitorenter 时,若对象未被锁定时,或者当前线程已经拥有该对象的 monitor 锁,则锁计数器 +1,该线程获取该对象锁。
当执行 monitorexit 时,锁计数器 -1。当计数器为 0 时,此对象锁就被释放了。此时,其它阻塞的线程可以请求获取该 monitor 锁。
如果获取 monitor 对象失败,该线程则会进入阻塞状态,直到其他线程释放锁
在Java虚拟机(HotSpot)中,monitor是由ObjectMonitor实现.
objectMonitor.cpp C++源码链接
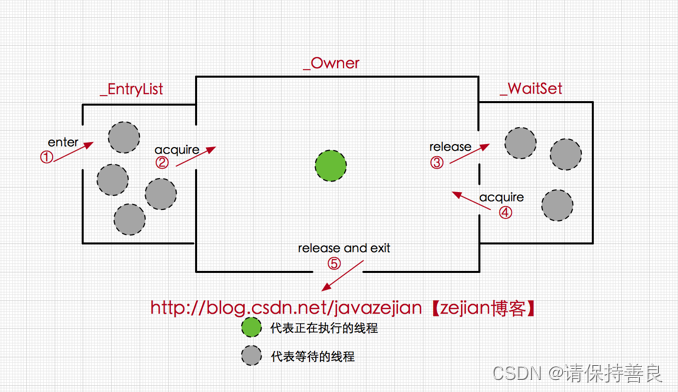
下面的demo 让大家在字节码层面体验一下
public class JavaSync {
public Integer value;
//同步方法
public synchronized void setValue1(Integer value) {
this.value = value;
}
public void setValue2(Integer value) {
//显式同步
synchronized (this) {
this.value = value;
}
}
}
切换到目标类目录执行javac JavaSync.java命令生成编译后的 .class 文件。执行javap -verbose JavaSync反编译后得到:
......
public synchronized void setValue1(java.lang.Integer);
descriptor: (Ljava/lang/Integer;)V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED -> [ ACC_SYNCHRONIZED 标志 ]
Code:
stack=2, locals=2, args_size=2
0: aload_0
1: aload_1
2: putfield #2 // Field value:Ljava/lang/Integer;
5: return
LineNumberTable:
line 7: 0
line 8: 5
LocalVariableTable:
Start Length Slot Name Signature
0 6 0 this LJavaSync;
0 6 1 value Ljava/lang/Integer;
public void setValue2(java.lang.Integer);
descriptor: (Ljava/lang/Integer;)V
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=2
0: aload_0
1: dup
2: astore_2
3: monitorenter -> [监视器 进入]
4: aload_0
5: aload_1
6: putfield #2 // Field value:Ljava/lang/Integer;
9: aload_2
10: monitorexit -> [监视器 退出]
11: goto 19
line 14: 19
LocalVariableTable:
Start Length Slot Name Signature
0 20 0 this LJavaSync;
0 20 1 value Ljava/lang/Integer;
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 14
locals = [ class JavaSync, class java/lang/Integer, class java/lang/Object ]
stack = [ class java/lang/Throwable ]
frame_type = 250 /* chop */
offset_delta = 4
}
SourceFile: "JavaSync.java"
互斥同步锁 2.java.util.concurrent.ReentrantLock
ReentrantLock底层使用了CAS+AQS队列实现.
CAS主要是由sun.misc.Unsafe这个类通过JNI调用CPU底层指令实现。(cas介绍见后续的描述)
AQS是一个用于构建锁和同步容器的框架。
AQS使用一个FIFO的队列(也叫CLH队列,是CLH锁的一种变形),表示排队等待锁的线程。队列头节点称作“哨兵节点”或者“哑节点”,它不与任何线程关联。
其他的节点与等待线程关联,每个节点维护一个等待状态waitStatus。结构如下图所示: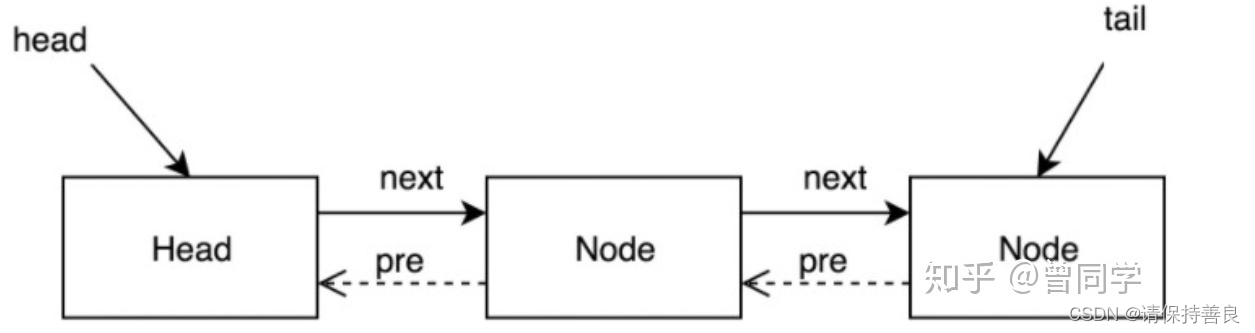
0.每一个ReentrantLock自身维护一个AQS队列记录申请锁的线程信息;
1.通过大量CAS保证多个线程竞争锁的时候的并发安全;
2.可重入的功能是通过维护state变量来记录重入次数实现的。
3.公平锁需要维护队列,通过AQS队列的先后顺序获取锁,缺点是会造成大量线程上下文切换;
4.非公平锁可以直接抢占,所以效率更高;
synchronized VS ReentrantLock
synchronized是Java原生关键字锁;
ReentrantLock是Java语言层面提供的锁;
ReentrantLock在等待锁时可以使用lockInterruptibly()方法选择中断, 改为处理其他事情,
而synchronized关键字,线程需要一直等待下去。同样的,tryLock()方法可以设置超时时间,用于在超时时间内一直获取不到锁时进行中断。
ReentrantLock可以实现公平锁,而synchronized的锁是非公平的。
ReentrantLock拥有方便的方法用于获取正在等待锁的线程。
ReentrantLock可以同时绑定多个Condition对象,而synchronized中,
锁对象的wait()和notify()或notifyAll()方法可以实现一个隐含的条件,如果要和多于一个条件关联时,只能再加一个额外的锁,
而ReentrantLock只需要多次调用newCondition方法即可。
ReentrantLock 更加灵活 功能更多 但是需要手动调用相应的方法.
非阻塞同步锁 1.CAS操作本身的原子性保障
轻量级锁(CAS的实现,不经过OS调度)(无锁 - 自旋锁 - 乐观锁)
AtomicInteger
CAS主要是由sun.misc.Unsafe这个类通过JNI调用CPU底层指令实现。
Unsafe:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
运用:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class T02_TestUnsafe {
int i = 0;
private static T02_TestUnsafe t = new T02_TestUnsafe();
public static void main(String[] args) throws Exception {
//Unsafe unsafe = Unsafe.getUnsafe();
Field unsafeField = Unsafe.class.getDeclaredFields()[0];
unsafeField.setAccessible(true);
Unsafe unsafe = (Unsafe) unsafeField.get(null);
Field f = T02_TestUnsafe.class.getDeclaredField("i");
long offset = unsafe.objectFieldOffset(f);
System.out.println(offset);
boolean success = unsafe.compareAndSwapInt(t, offset, 0, 1);
System.out.println(success);
System.out.println(t.i);
//unsafe.compareAndSwapInt()
}
}
底层实现
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
jdk8u: unsafe.cpp:
cmpxchg = compare and exchange set swap
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
jdk8u:
atomic_linux_x86.inline.hpp 93行
is_MP = Multi Processors
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
jdk8u: atomic_linux_x86.inline.hpp
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
最终实现:
cmpxchg = cas修改变量值
lock cmpxchg 指令
下面是这段代码解释:
os::is_MP
判断是否为多处理器,如果是多处理器则返回 true。
asm
内嵌汇编代码。
volatile
告诉编译器对访问该变量的代码就不再进行优化,和Java中的volatile不同。
LOCK_IF_MP
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
根据当前系统是否为多核处理器决定是否为cmpxchgl指令添加lock前缀。
cmpxchgl
汇编指令,用于实现交换,单核处理器使用 cmpxchgl 命令实现 CAS 操作,多核处理器使用带 lock 前缀的cmpxchgl 命令实现 CAS 操作。
所以这里还需要重点了解下lock前缀,intel的手册对lock前缀的说明如下:
1.确保对内存的读-改-写操作原子执行。在Pentium及Pentium之前的处理器中,
带有lock前缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。
很显然,这会带来昂贵的开销。从Pentium 4,Intel Xeon及P6处理器开始,
intel在原有总线锁的基础上做了一个很有意义的优化:如果要访问的内存区域(area of memory)
在lock前缀指令执行期间已经在处理器内部的缓存中被锁定(即包含该内存区域的缓存行当前处于
独占或以修改状态),并且该内存区域被完全包含在单个缓存行(cache line)中,
那么处理器将直接执行该指令。由于在指令执行期间该缓存行会一直被锁定,
其它处理器无法读/写该指令要访问的内存区域,因此能保证指令执行的原子性。
这个操作过程叫做缓存锁定(cache locking),缓存锁定将大大降低lock前缀指令的执行开销,
但是当多处理器之间的竞争程度很高或者指令访问的内存地址未对齐时,仍然会锁住总线。
2.禁止该指令与之前和之后的读和写指令重排序。
3.把写缓冲区中的所有数据刷新到内存中